jansch skrev:petersteindl skrev:LeifB skrev:
Låter som man göra en egen mix.
Separera ut allt och bygga upp den igen.
Som sagt vilken app kan fixa det?
Det finns en app som separerar allt och bygger upp det.
Den appen finns i en dator som kallas för hjärnan.
Vill man bygga en motsvarande kopia av sådan hjärna/dator med app så finns det 2 sätt.
1. Du följer en gammal och beprövad anvisning som lyder: Varen fruktsamma och föröken eder.

2.
Du bygger en kopia på hörseln i form av axlar + huvud + öron + trumhinnor + hjärna med exempelvis en Dell + Windows 10 som operativsystem + en mjukvara i form av app.Den kopian skall uppfylla kraven att vara: In the image and in the likeness of a brain.Nu gäller det bara att ta reda på hur den där appen ska fungera och hur den skall skrivas/programmeras för att åstadkomma korrekt slutresultat från given input. D v s, man går från en mängd akustiska ljudvågor som når 2 trumhinnor och blir till kod i nervsystemet och behandlas på visst sätt för att därefter bli ett resultat i form av output som sker på något sätt. Det är bara att sätta sig vid datorn och programmera. Man måste ju veta hur input ser ut och beskriva den med matematiska formler. Vågekvationen kan funka och hur summation av vågor ser ut matematiskt. Då hamnar ljudet i form av kod på trumhinnorna. Sedan går ljudet till mellanöra i form av mekanisk rörelse och därefter till inneröron och därefter i form av elektrokemisk kod i nervsystemet. Sedan fixar hjärnan det lilla extra, nämligen att segregera all kod till att bli skild kod beroende på respektive ljudkälla, musikinstrument, röster osv. samt även en total segregation av respektive ljudkällas första reflexer som beskriver den akustiska miljön samt respektive ljudkällas positionering i denna akustiska miljö. Direktljud och tidiga reflexer sätter respektive ljudkällas positionering i förhållande till varandra i 3 dimensioner och även på korrekt plats i den akustiska miljön som också kallas perspektiv.
Piece of cake. Hörseln fixar det på några hundra millisekunder.
Näääää..... nu blev det väl fel.
Inspelat stereomaterial där man försöker separera sång, trummor etc skall ju inte förvanskas av torso etc utan förhoppningsvis vara ett perfekt urklipp av den
inspelade stämman/musikinstrumentet. Annars blir det ju "kaka på kaka" oavsett om man gör mätningar eller neuroakustisk forskning.
Den akustiska lyssningsmiljön ingår ju förhoppningsvis inte heller i applikationen om man är ute efter att bedömma direktljud, fantomprojektion, etc.
Nej, det jag skriver är 100 % helt korrekt. På något annat sätt är det inte. Fast, jag tror att du inte förstått det jag pratar om. Jag kanske inte varit tillräcklig tydlig. Jag gör ett nytt försök.
Jag pratar inte om inspelat stereomaterial där man försöker separera sång, trummor etc. Att jag nämner det, beror på att det är en vink, ett tips en antydan till vad som behöver förstås för att kunna förstå hörseln.
Objektet jag pratar om är: Hörselns förmåga att kunna höra enskilda musikinstrument och röster och vilka kvanta och parametrar som ligger till grund för detta.
Jag pratar enkom om hörselns funktion.
Jag är således helt ointresserad av att bedöma direktljud, fantomprojektion, etc.
Hörseln bedömer inte direktljud och heller inte fantomprojektion. Tror man det så har man missuppfattat hela hörselns funktion.
Då du t.ex. hör en cello i ett rum, så har inte hörseln förmågan att filtrera bort de tidiga reflexerna. Det kan i och för sig göras under förutsättning att man akustiskt dämpar de tidiga reflexerna. Men det är inte hörseln som fixar det.
Hörseln är byggd för att maskera ljud som ligger under en viss nivå i jämförelse med andra ljud som ligger över en viss nivå. Det är efterklangen som maskeras då direktljud och tidiga reflexer har en viss mängd högre nivå än efterklangen. I konserthus hörs detta strax efter slutackordet, d v s då efterklangen klingar ut. Det är ett intervall på ungefär 1,5-3 sekunder. Har konserthuset T60 på 2 sekunder och slutackordet kommer upp i 110 dB så har nivån sjunkit till 50 dB efter 2 sek. Då hörs den nivån fortfarande.
Hörseln hör en integrerad helhet mellan direktljud och reflexer.
Det du skriver angående neuroakustisk forskning är dessutom inte korrekt.
Menar du verkligen att hörseln kan detektera riktning och göra avståndsbedömning till ljudkällor utan ytteröron och utan att få med tidiga reflexer från den akustiska miljön?
Jag hävdar bestämt nej.
I alla de böcker och forskningsrapporter jag läst i ämnet gällande lokalisation av ljudkällor, så framkommer det tydligt att man som grundkrav måste ha med HRTF i resonemangen för att förstå hörselns funktion och det gäller även inom neuroakustik.
All HRTF är en kodning som varje människa tillför alla inkommande ljudvågor från yttre ljudkällor, således ej hörlurar. Den kodningen är till för att detektera riktning, inte för att avgöra klang, trots att mycket stor frekvenskurveförändring sker pga HRTF. Frekvensgångsförändring är således en parameter för riktning.
Kan hörseln detektera riktning med hjälp av HRTF, så innebär det att hörseln lyckats med uppgiften och trunkerar denna HRTF för klangbestämning. Det är således ett sorteringsarbete med avkodning och dechiffrering.
Detta betyder att hörseln måste känna igen om frekvenskurvan finns i ljudkällorna eller som en egen mekanism i hörseln.
Du skriver ibland att tekniska objektiva mätinstrument har 1000-falt högre upplösning än hörseln som mätinstrument.
Jag hävdar precis tvärtom. Hörseln som mätinstrument har miljoners-miljarders gånger högre upplösning än marknadens samtliga tekniska mätinstrument, beroende på vad som mäts.
Detta gäller t.ex. då man sitter på konserthus och hör orkestern spela musik. Man kan t.ex. vara helt blind.
Du hör storleken på rummet.
Du hör avstånd till väggar.
Du hör den akustiska miljön och du kan bedöma hur den ser ut.
Du hör instrumentens placering. Det betyder att du hör vilken infallsvinkel ljudvågorna från respektive instrument har till ditt huvud och det gäller direktljudet.
Hörseln detekterar direktljudet, men man hör inte direktljudet i sig. Man hör en summa av direktljud och tidiga reflexer.
Hörseln detekterar från vilken infallsvinkel de tidiga reflexerna kommer ifrån. Det är en helt essentiell information för hörseln i sin avståndsbedömning till ljudkällan.
Du hör nämligen perspektiv. Det fär med sig en del konsekvenser.
Men frågan är: Vilka parametrar styr hela denna process? Denna process kan inte ske med objektiva fysikaliska mätinstrument.
Allt ljud från samtliga instrument i orkestern som når mikrofonkapseln summeras vid kapseln enligt superpositionsprincipen. Hur vet mätinstrumentet vilken del som tillhör oboe eller violin eller trumpet eller valthorn?
Mätinstrumentet vet ju inte ens vad en violin eller en trumpet eller en oboe ens är för något.
Hur kan mätinstrumentet segregera mellan musikinstrumenten och dessutom sätta dem på rätt plats dels i förhållande till varandra dels i förhållande till lokalens väggar och tak.
Mätinstrumentet kan i detta fall inte mäta något som helst av detta.
Allt ljud från samtliga instrument i orkestern som når öronen summeras vid respektive trumhinna enligt superpositionsprincipen. Hur vet hörseln som mätinstrument vilken del som tillhör oboe eller violin eller trumpet eller valthorn?
Hörseln som mätinstrumentet vet vad en violin och en trumpet och en oboe är. Därmed finns förutsättningen att lösa upp ekvationerna för att kunna segregera all information som finns på trumhinnorna. Det är således en föregående inlärningsprocess inblandat i dechiffrering av kod i hjärnan. Men hur går det till? Vilka parametrar styr? Vilka storheter är det och med vilka enheter mäts de?
Det är här som AI blir synnerligen intressant som företeelse. Man kan alltså simulera med neurala nätverk och studera/analysera vilka parametrar hörseln använder sig av då hörseln exempelvis hör en trumpet 20 grader till höger och 3 meter bakom 2a-violiner osv.
Det är just detta jag tidigare ville ge en vink om.
Hörseln som mätinstrument klarar det galant och ganska snabbt. Därmed är hörseln som mätinstrument triljarder gånger mer överlägset än voltmetrar, spektrumanalysatorer, frekvensgångsmätare, distorsionsanalysatorer mm.
Inte ens spektrogram inom spektralanalysen duger i sammanhanget i att göra en analys av en symfoniorkester med alla instrument.

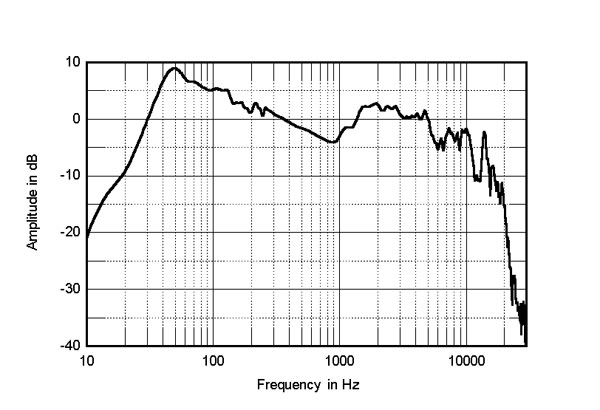
Kan du här se vad det är för ljud-källa/-or, avståndet till ljud-källan/-orna, hur rummet ser ut, osv?
Spektralanalys är en metod för att undersöka ett spektrum, den spektrala energifördelningen, det vill säga energifördelningen i frekvensplanet hos en signal.
Signalen redogörs för i ett spektrogram. Spektralanalys kan användas för olika typer av signaler, som t.ex. ljud.
Inom akustiken och talteknologin kallas spektralanalysen för spektrografi.
Vilka parametrar använder hörseln för dess uppgift att segregera varenda ton som finns på trumhinnorna och för att höra instrumentet, dess positionering, den akustiska miljön, eller för den delen, vad som spelas?
Ur allas försvar kan jag säga, det är inte ens utrett inom vetenskapen. Vissa hypoteser och antaganden vet man är felaktiga, men man har inget bättre alternativ än så länge.
Nu forskas det extremt mycket inom neurovetenskap gällande hörseln.
Man använder även AI för att söka förstå vilka parametrar som styr.
I artiklar jag läst har man gjort en hel del mätningar på densitet av impulser i nerver som funktion av akustiska stimuli. Till en början var samtliga resultat stokastiska och oanvändbara för analys.
Sedan gjorde man samma försök, men istället för att mäta på summation av signaler, så mätte man subtraktion av signaler d v s differensen. Då helt plötsligt blev densiteten av aktionspotentialer i neuronerna direkt proportionellt med akustiska stimuli från höger och vänster trumhinna. Om differenser finns i nervbanor så har hörseln ett enastående verktyg i att selektera bort information efter dechiffrering av ILD och HRTF.
Hörseln använder även kognitiva processer med jämförelse med minne d v s. inlärningsprocesser och då kan vi lära oss mycket av AI.
Det är därför jag tog upp AI. En frågeställning är hur detaljer upplevs. Det har jag svarat på. Jag har dessutom tagit upp vilka parametrar som styr och med vilka enheter det mäts.
Jag har ännu inte kommit in på de viktigaste parametrarna, nämligen olika former av korrelation och kovarians och en kombination dem emellan.
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.