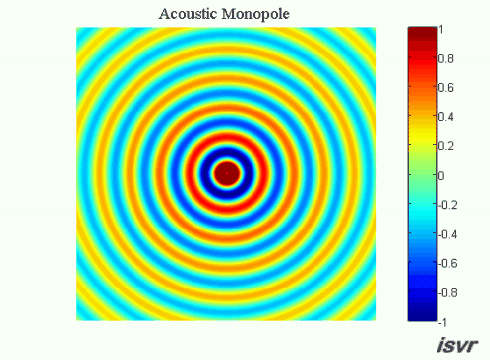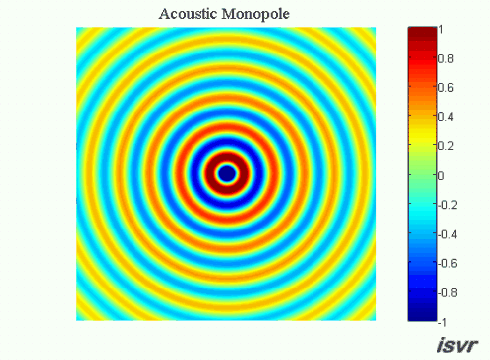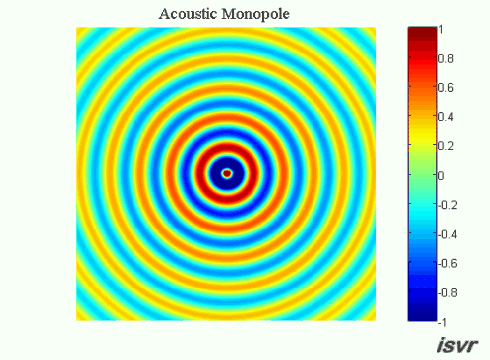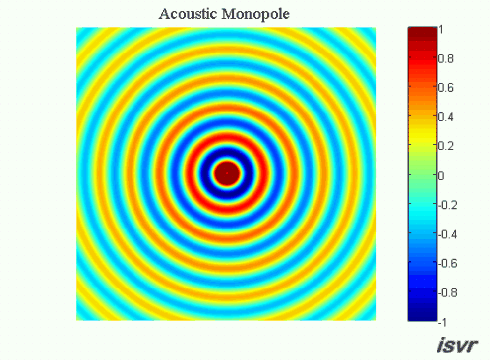
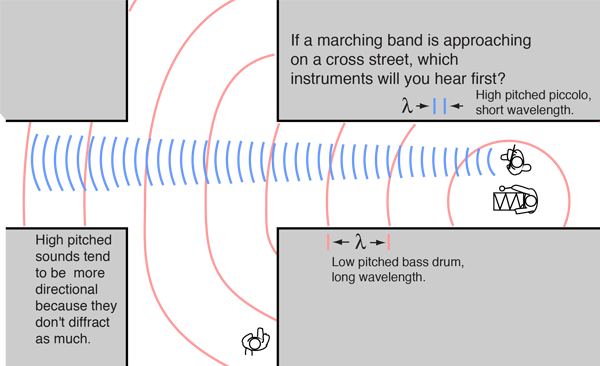
Ok, en väldigt basic fråga om hur ljud fungerar fysiskt:
Om två exakt lika ljudvågor utbreder sig i exakt motsatt riktning mot varandra, vad händer då när de möts? Släcker de ut varandra och "försvinner" för alltid, eller fortsätter de förbi varandra oberört liksom? Är det bara exakt där de möts som en utsläckning uppstår, eller i hela rummet efter kollisionen (eller vad man ska kalla det)?
rajapruk skrev:Ok, en väldigt basic fråga om hur ljud fungerar fysiskt:
Om två exakt lika ljudvågor utbreder sig i exakt motsatt riktning mot varandra, vad händer då när de möts? Släcker de ut varandra och "försvinner" för alltid, eller fortsätter de förbi varandra oberört liksom? Är det bara exakt där de möts som en utsläckning uppstår, eller i hela rummet efter kollisionen (eller vad man ska kalla det)?
Blir inte vågen förstärkt där dom möts? 2 rundstrålande högtalare tex. där man sitter närmare den ena så hör man ju den andra åxå, låt vara med någon millisekunds fördröjning men man hör den. Knepig fråga i alla fall.
Fd. högtalarbyggare i samarbete med Monacor AB under 10 år, HiFi Kit Stockholm sedan 1973, Visaton, Inertia AB, Sinus. Sveriges Radio. Deltagit i HiFi och musik, Elektronikvärlden och Teknik för alla.
Vågorna summeras i varje punkt i rummet med hänsyn tagen till fasen (superponering).
Det är så stående våg uppstår. Då bildas noder och bukar.
Kör en sinuston på 1 - 5kHz genom stereon i båda högtalarna och rör dej i rummet. Då kan du hitta ställen med svagt ljud och högt ljud - det "kvittrar"när du rör dej. Summering sker oavset vinkel mellan ljuden.
Jo! Det förstår du visst! (redigering: du tog bort inlägget att du inte förstod.....)
Tänk såhär, Ljudet (övertryck och undertryck) rör sig med ljudets hastighet från primär basarna mot bakväggen. Hade det vara varit en rigid bakvägg hade ljudet reflekterats.
Om nu ljudet möter en "vägg" som är eftergivlig minskar reflektionen. Kasta en boll mot en gardin och du får knappt någon stuts tillbaka. Om nu t o m "väggen" för sig i takt med ljudvågen (alltså en högtalare) är det som om väggen inte fanns!
Det svåra i tanken är att inte se det som en tryckvåg som rör sig med ljudets hastighet, man kan inte se det som en stillastående sinus ut från högtalaren.
Lite halvtaskig liknelse men om du försöker minska reklektionen kan du använda något som i praktiken tar hand om ljudtrycket såsom dämpmaterial, Helmholtzresonator eller en högtalare. Alltså gör så att ljudvågen inte "ser" en vägg (eller något annat som har annan akustisk impedans.
rajapruk skrev:Ok, en väldigt basic fråga om hur ljud fungerar fysiskt:
Om två exakt lika ljudvågor utbreder sig i exakt motsatt riktning mot varandra, vad händer då när de möts? Släcker de ut varandra och "försvinner" för alltid, eller fortsätter de förbi varandra oberört liksom? Är det bara exakt där de möts som en utsläckning uppstår, eller i hela rummet efter kollisionen (eller vad man ska kalla det)?
Se där, nu ställs det frågor som visar på att det finns tankeverksamhet. Detta är vågrörelselära och tar lite tid att snappa.
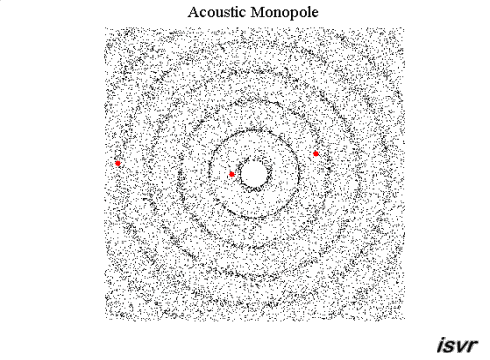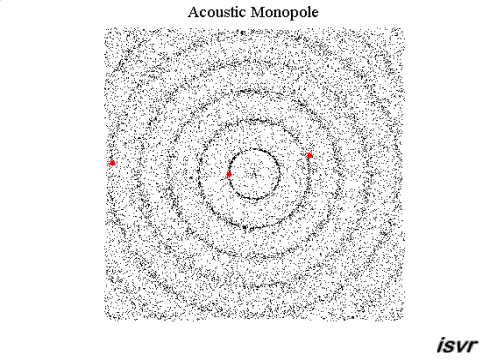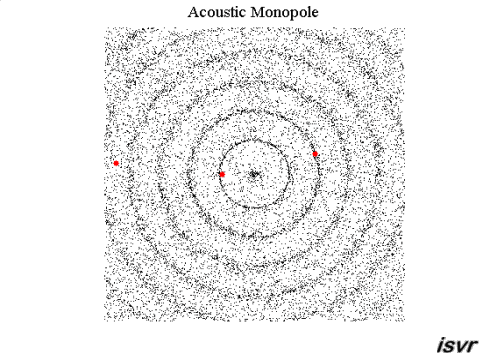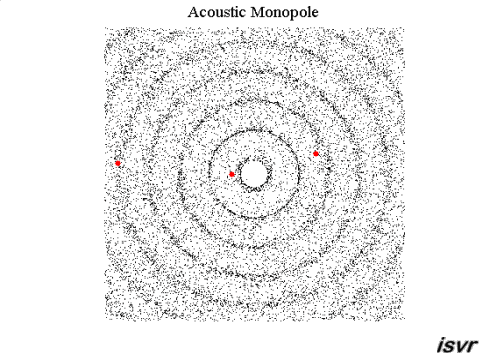
Det jag blåmarkerat strukit under kallas för villkor. Dock kan jag säga att svaret kan göras allmängiltig. Vågorna kan uttryckas som vektorer och summeras enligt superpositionsprincipen. Vågorna som i det här fallet är akustiska ljudvågor i luft beskrivs med frekvens, amplitud och fas. Amplituden är tryck och vektorn är en gradient d v s en tryckgradient. Denna tryckgradient har en hastighet som är ljudets hastighet i luft. Utbredningshastigheten av gradienten är vinkelrät mot gradienten.
För en sfärisk våg är gradienten en sfär som blir större ju längre från dess mittpunkt vågen utbreder sig. För denna vågs mittpunkt kan man rita in vektorer i samtliga riktningar.
För en plan våg är gradienten ett plan som bibehåller samma storlek på ytan då vågen utbreder sig. För denna våg kan man rita in vektorer i en och endast en riktning där alla vektorer är parallella med varandra och vinkelrät mot tryckgradienten.
Sedan finns ett specialfall som är cylindrisk vågutbredning. Vi glömmer denna typ i denna diskussion.
I verkligheten är akustiska vågor som ett slags mellanting av plan och sfärisk våg och beror på avståndet från ljudkällans ljudalstring och tryckgradienten som fortskrider från ljudkällan med ljudets hastighet.
Efter 1,7 till 2 meter betraktar man ljudvågorna i luft som plana.
Så, om man betraktar 2 plana ljudvågor och applicerar dessa på din frågeställning så är det så att dessas respektive tryckgradient fortskrider i gradientens normalriktning.
Innan de möts kan vi kalla respektive vektor för A respektive B. Då vågorna möts summeras de A+B enligt superpositionsprincipen. Därefter fortsätter respektive våg precis såsom innan vågorna möttes d v s A och B fortsätter som om inget hade hänt. Detta gäller oavsett fas i summationspunkten. I summationspunkten gäller att om fasdifferensen mellan A och B är noll så summeras de till + 6 dB med dina villkor och om fasdifferensen är 180 grader så blir deras summa = noll. Oavsett vilket så är A respektive B identiska efter summationspunkten som de var före.
För att komplicera det hela så är respektive vektor helt intakt även i summationspunkten. Dock är summan i den punkten = A+B.
För att ytterligare komplicera det hela så är ljudtryck inte en vektor och har därmed ingen riktning. Ljudtryck är en skalär storhet i en punkt. Det är en amplitud och mäts med enheten Pascal. Gör man en kvot mellan två ljudtryck så förkortas enheten Pascal bort eftersom den finns i både nämnaren och täljaren. Det blir en kvot. Genom att välja en tryckreferens lika med hörselns tröskelvärde så fås ett slags referenssystem och om man dessutom tar logaritmen så fås en skala på ljudtrycket som ges enheten dB och kallas på engelska för SPL, sound pressure level vilket är en nivå på sound pressure och sound pressure är ett tryck och mäts i Pascal. Det kan vara bra att känna till skillnaden mellan sound pressure och sound pressure level. Man övergår till SPL eftersom hörselns dynamikområde är väldigt stort och då underlättar det med logskala och hörselns tröskelpunkt som referens. Nivån på referensen blir då på denna skala 0 dB.
Om man istället för sinustoner applicerar impuls och svarar på din fråga så är impulsen hos A oförändrad efter summationspunkten i jämförelse med före och likaså för B. Men i summationspunkten blir summan +6 dB om A och B är i fas och om de är i motfas blir summan noll i summationspunkten.
Detta kan också appliceras på det man kallar för direktljudet. En reflex med exempelvis en riktning 45 grader från direktljudets riktning påverkar direktljudet enkom i området där de möts. Efter mötet är direktljudet intakt d v s oförändrat såsom det var innan mötet. D v s sätts en mätmikrofon i detta område syns en kamfiltereffekt och då kan man förledas tro att det är direktljudet man mätt upp men så är det inte. Direktljud indikerar att det rör sig om en riktning och denna riktning är en tryckgradient som fortplantar sig med riktning mot mottagaren och tryckgradienten i denna riktning kallas direktljud. Denna tryckgradient förblir oförändrad efter möte med reflex under förutsättning att reflexens tryckgradients riktning är skilt från direktljudets. Detta kan enkelt simuleras med impuls. I klartext, reflexer från närstående vägg som har annan riktning än direktljudet påverkar inte direktljudet efter det att vågorna har korsat varandra. Jag ser att många på forumet har helt missförstått detta fenomen och tror att om man mäter på 1 meter från ljudkälla i rum och får en tonkurva och tror att detta representerar direktljudet så tror de fel. Det representerar ingen vektor och därmed ingen riktning. Det representerar ett ljudtryck i en punkt som är en skalär. Direktljudet kan se helt annorlunda ut både före och efter denna punkt på väg mot lyssnaren.
Resonanser mellan 2 parallella väggar i rum innebär att en forcerad ljudvåg exempelvis sinusoid som reflekteras i vägg och därefter går i motsatt riktning samtidigt som inkommande sinusvåg fortsätter så uppstår en summa av dessa. Först uppstår en stående våg. I resonans, vars frekvens ges av avståndet mellan väggarna, så fortsätter fenomenet med att amplituden ökar i vissa punkter längs med linjen mellan väggarna. Eftersom vågen fortskridit mer än 2 meter i rummet så betraktas den som plan och detta plan är parallellt med väggarna. Det blir två plana ljudvågor som går åt varsitt håll mellan väggarna och summeras i varje punkt enligt superpositionsprincipen.
På så sätt bildas ett interferensmönster i rummet. Detta mönster kan man åskådliggöra i olika rumsakustikprogram.
Vill påpeka att jag inte korrekturläst detta inlägg för jag måste göra annat nu.
Mvh Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
petersteindl skrev:Resonanser mellan 2 parallella väggar i rum innebär att en forcerad ljudvåg exempelvis sinusoid som reflekteras i vägg och därefter går i motsatt riktning samtidigt som inkommande sinusvåg fortsätter så uppstår en summa av dessa. Först uppstår en stående våg. I resonans, vars frekvens ges av avståndet mellan väggarna, så fortsätter fenomenet med att amplituden ökar i vissa punkter längs med linjen mellan väggarna. Eftersom vågen fortskridit mer än 2 meter i rummet så betraktas den som plan och detta plan är parallellt med väggarna. Det blir två plana ljudvågor som går åt varsitt håll mellan väggarna och summeras i varje punkt enligt superpositionsprincipen.
Först och främst Peter - heder åt dej att du har ork och ambition att ge ett så uttömmande svar.
Vet inte om jag misstolkar det du skrivit i citatet ovan, men det är inte riktgt korrekt enligt min mening. Den övriga texten i ditt inlägg håller jag helt med om.
Vågen kommer inte vara plan i den mening att den är parallell med väggen efter 2 meter om vi har en normal ljudkälla där ljudkällans storlek är väsentligt mindre än våglängden ( vilket den normalt är i hifi sammanhang).
Vid MÄTNINGAR på en typisk ljudkälla, t.ex en normal hifi högtalare, anser man att ljudvågen är plan för en mätmikrofon efter ca 2 meter*. Detta är dock väldigt beroende av avstånd mellan högtalarelement, elementens utformning, höljet, basport, mm. Det tar alltså tid (sträcka) för ljudvågen att forma sig då ljudkällan inte är punktformig. ( eller inte är kolvformig och väldigt stor). Då ljudkällan trots allt är är någorlunda punktformig kommer en sfärisk ljudvågsutbredning att ske mot väggen, ju bredare vägg desto större fasskillnad ut mot kanterna - avståndet är ju längre och det finns ingen metod att "förlänga" ljudvågen (om det är "samma luft" i hela rummet)
Vad som däremot sker vid resonans mellan väggarna är att ljudvågen sprider ut sig när den studsar mellan väggarna och så småningom kommer en plan, stående våg att skapas mellan väggarna. I det skedet är de reflekterande väggarna "ljudkälla".
Vid Högtalarmätningar är alltså en plan vågfront egentligen en snygg och homogen sfärisk vågfront där radien är så stor att ett mikrofonmembran uppfattar vågfronten som plan vid den högsta frekvens som mätningen sker vid. = det dynamiska trycket är jämnt fördelat över membranet.
*tyvärr mäts de flesta hifi högtalare upp på 1 meters avstånd, man borde mäta på mycket längre avstånd t.ex minsta lyssningsavstånd som borde vara klart över 2 meter. Att rumsmätningar då är svåra att genomföra vid direktljudsmätning är trist men inget att göra åt.
petersteindl skrev:Resonanser mellan 2 parallella väggar i rum innebär att en forcerad ljudvåg exempelvis sinusoid som reflekteras i vägg och därefter går i motsatt riktning samtidigt som inkommande sinusvåg fortsätter så uppstår en summa av dessa. Först uppstår en stående våg. I resonans, vars frekvens ges av avståndet mellan väggarna, så fortsätter fenomenet med att amplituden ökar i vissa punkter längs med linjen mellan väggarna. Eftersom vågen fortskridit mer än 2 meter i rummet så betraktas den som plan och detta plan är parallellt med väggarna. Det blir två plana ljudvågor som går åt varsitt håll mellan väggarna och summeras i varje punkt enligt superpositionsprincipen.
Först och främst Peter - heder åt dej att du har ork och ambition att ge ett så uttömmande svar.
Vet inte om jag misstolkar det du skrivit i citatet ovan, men det är inte riktgt korrekt enligt min mening. Den övriga texten i ditt inlägg håller jag helt med om.
Vågen kommer inte vara plan i den mening att den är parallell med väggen efter 2 meter om vi har en normal ljudkälla där ljudkällans storlek är väsentligt mindre än våglängden ( vilket den normalt är i hifi sammanhang).
Vid MÄTNINGAR på en typisk ljudkälla, t.ex en normal hifi högtalare, anser man att ljudvågen är plan för en mätmikrofon efter ca 2 meter*. Detta är dock väldigt beroende av avstånd mellan högtalarelement, elementens utformning, höljet, basport, mm. Det tar alltså tid (sträcka) för ljudvågen att forma sig då ljudkällan inte är punktformig. ( eller inte är kolvformig och väldigt stor). Då ljudkällan trots allt är är någorlunda punktformig kommer en sfärisk ljudvågsutbredning att ske mot väggen, ju bredare vägg desto större fasskillnad ut mot kanterna - avståndet är ju längre och det finns ingen metod att "förlänga" ljudvågen (om det är "samma luft" i hela rummet)
Vad som däremot sker vid resonans mellan väggarna är att ljudvågen sprider ut sig när den studsar mellan väggarna och så småningom kommer en plan, stående våg att skapas mellan väggarna. I det skedet är de reflekterande väggarna "ljudkälla".
Vid Högtalarmätningar är alltså en plan vågfront egentligen en snygg och homogen sfärisk vågfront där radien är så stor att ett mikrofonmembran uppfattar vågfronten som plan vid den högsta frekvens som mätningen sker vid. = det dynamiska trycket är jämnt fördelat över membranet.
*tyvärr mäts de flesta hifi högtalare upp på 1 meters avstånd, man borde mäta på mycket längre avstånd t.ex minsta lyssningsavstånd som borde vara klart över 2 meter. Att rumsmätningar då är svåra att genomföra vid direktljudsmätning är trist men inget att göra åt.
Jag bör tillägga att vid de otal simuleringar vi gjort så har det varit 2 basmoduler utmed en vägg på ungefär 4-6 meter från varandra och även med center bas och med 4 eller 5 basar utplacerade i rummet längs med väggar och hörn. Jag glömde skriva det. Då tittar vi på vågutbredning i 2 dimensioner respektive i 3 dimensioner. Basmoduler har placerats i hörn på samma vägg. basmodulerna har även placerats 85 cm från vägg. Sedan gör vi filmer av den simulerade vågutbredningen samt har ett antal mätpunkter i rummet så man kan se hur frekvensgången ser ut i respektive punkt och förändras i tiden vartefter vågorna utbreder sig i rummet fram och tillbaka. Först tänkte jag att vi skulle lägga upp filmer här i gif-format, men det visade sig bli mycket stora filer d v s strax under 1 GB per animering.
Det är oerhört lärorikt att se dessa animeringar och hur avståndet till bakre vägg, från högtalaren sett, ödelägger direktljudet eftersom reflexen då är parallell med direktljudet samt går i samma riktning. Det är lika intressant att se hur reflexer från sidoväggar inte påverkar direktljudet och då får vi simulera Intensitet. Dessutom var det intressant att se hur det ser ut i basen från planstrålare då man tar hänsyn till proximyeffekten samt tittar på realdel och imaginärdel och behandlar ljudvågorna som reaktiva. Det var i september 2018 vi höll på med detta och jag måste sätta mig in i resultaten ånyo innan jag ger mig in i närmare beskrivningar.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
Finns det någon chans att animeringarna kan läggas på en server? Tex Dropbox. Det skulle vara oerhört spännande att få ta del av efter att du satt dig in i resultaten.
Mvh Johan
Orthoakustiska öron. Bor i Sörmland och ibland i Sthlm
Styrelseledamot sedan maj 2024 i Stiftelsen Stig Carlsson.
petersteindl skrev:Resonanser mellan 2 parallella väggar i rum innebär att en forcerad ljudvåg exempelvis sinusoid som reflekteras i vägg och därefter går i motsatt riktning samtidigt som inkommande sinusvåg fortsätter så uppstår en summa av dessa. Först uppstår en stående våg. I resonans, vars frekvens ges av avståndet mellan väggarna, så fortsätter fenomenet med att amplituden ökar i vissa punkter längs med linjen mellan väggarna. Eftersom vågen fortskridit mer än 2 meter i rummet så betraktas den som plan och detta plan är parallellt med väggarna. Det blir två plana ljudvågor som går åt varsitt håll mellan väggarna och summeras i varje punkt enligt superpositionsprincipen.
Först och främst Peter - heder åt dej att du har ork och ambition att ge ett så uttömmande svar.
Vet inte om jag misstolkar det du skrivit i citatet ovan, men det är inte riktgt korrekt enligt min mening. Den övriga texten i ditt inlägg håller jag helt med om.
Vågen kommer inte vara plan i den mening att den är parallell med väggen efter 2 meter om vi har en normal ljudkälla där ljudkällans storlek är väsentligt mindre än våglängden ( vilket den normalt är i hifi sammanhang).
Vid MÄTNINGAR på en typisk ljudkälla, t.ex en normal hifi högtalare, anser man att ljudvågen är plan för en mätmikrofon efter ca 2 meter*. Detta är dock väldigt beroende av avstånd mellan högtalarelement, elementens utformning, höljet, basport, mm. Det tar alltså tid (sträcka) för ljudvågen att forma sig då ljudkällan inte är punktformig. ( eller inte är kolvformig och väldigt stor). Då ljudkällan trots allt är är någorlunda punktformig kommer en sfärisk ljudvågsutbredning att ske mot väggen, ju bredare vägg desto större fasskillnad ut mot kanterna - avståndet är ju längre och det finns ingen metod att "förlänga" ljudvågen (om det är "samma luft" i hela rummet)
Vad som däremot sker vid resonans mellan väggarna är att ljudvågen sprider ut sig när den studsar mellan väggarna och så småningom kommer en plan, stående våg att skapas mellan väggarna. I det skedet är de reflekterande väggarna "ljudkälla".
Vid Högtalarmätningar är alltså en plan vågfront egentligen en snygg och homogen sfärisk vågfront där radien är så stor att ett mikrofonmembran uppfattar vågfronten som plan vid den högsta frekvens som mätningen sker vid. = det dynamiska trycket är jämnt fördelat över membranet.
*tyvärr mäts de flesta hifi högtalare upp på 1 meters avstånd, man borde mäta på mycket längre avstånd t.ex minsta lyssningsavstånd som borde vara klart över 2 meter. Att rumsmätningar då är svåra att genomföra vid direktljudsmätning är trist men inget att göra åt.
Jag bör tillägga att vid de otal simuleringar vi gjort så har det varit 2 basmoduler utmed en vägg på ungefär 4-6 meter från varandra och även med center bas och med 4 eller 5 basar utplacerade i rummet längs med väggar och hörn. Jag glömde skriva det. Då tittar vi på vågutbredning i 2 dimensioner respektive i 3 dimensioner. Basmoduler har placerats i hörn på samma vägg. basmodulerna har även placerats 85 cm från vägg. Sedan gör vi filmer av den simulerade vågutbredningen samt har ett antal mätpunkter i rummet så man kan se hur frekvensgången ser ut i respektive punkt och förändras i tiden vartefter vågorna utbreder sig i rummet fram och tillbaka. Först tänkte jag att vi skulle lägga upp filmer här i gif-format, men det visade sig bli mycket stora filer d v s strax under 1 GB per animering.
Det är oerhört lärorikt att se dessa animeringar och hur avståndet till bakre vägg, från högtalaren sett, ödelägger direktljudet eftersom reflexen då är parallell med direktljudet samt går i samma riktning. Det är lika intressant att se hur reflexer från sidoväggar inte påverkar direktljudet och då får vi simulera Intensitet. Dessutom var det intressant att se hur det ser ut i basen från planstrålare då man tar hänsyn till proximyeffekten samt tittar på realdel och imaginärdel och behandlar ljudvågorna som reaktiva. Det var i september 2018 vi höll på med detta och jag måste sätta mig in i resultaten ånyo innan jag ger mig in i närmare beskrivningar.
Med vänlig hälsning Peter
OK, du bygger upp en "line array högtalare". Med få högtalare utspridda i en linje kommer ett smalt frekvensområde att spridas med någorlunda plan vågfront i horisontalplanet. Rummets avgränsningar kommer också i viss mån att hjälpa till. Detta kräver säkerligen datorsimulering/animation för att få grepp om hur line array påverkas av rummet. Normalt arbetar ju line arrays i frifält eller extremt stora rum.
petersteindl skrev:Resonanser mellan 2 parallella väggar i rum innebär att en forcerad ljudvåg exempelvis sinusoid som reflekteras i vägg och därefter går i motsatt riktning samtidigt som inkommande sinusvåg fortsätter så uppstår en summa av dessa. Först uppstår en stående våg. I resonans, vars frekvens ges av avståndet mellan väggarna, så fortsätter fenomenet med att amplituden ökar i vissa punkter längs med linjen mellan väggarna. Eftersom vågen fortskridit mer än 2 meter i rummet så betraktas den som plan och detta plan är parallellt med väggarna. Det blir två plana ljudvågor som går åt varsitt håll mellan väggarna och summeras i varje punkt enligt superpositionsprincipen.
Först och främst Peter - heder åt dej att du har ork och ambition att ge ett så uttömmande svar.
Vet inte om jag misstolkar det du skrivit i citatet ovan, men det är inte riktgt korrekt enligt min mening. Den övriga texten i ditt inlägg håller jag helt med om.
Vågen kommer inte vara plan i den mening att den är parallell med väggen efter 2 meter om vi har en normal ljudkälla där ljudkällans storlek är väsentligt mindre än våglängden ( vilket den normalt är i hifi sammanhang).
Vid MÄTNINGAR på en typisk ljudkälla, t.ex en normal hifi högtalare, anser man att ljudvågen är plan för en mätmikrofon efter ca 2 meter*. Detta är dock väldigt beroende av avstånd mellan högtalarelement, elementens utformning, höljet, basport, mm. Det tar alltså tid (sträcka) för ljudvågen att forma sig då ljudkällan inte är punktformig. ( eller inte är kolvformig och väldigt stor). Då ljudkällan trots allt är är någorlunda punktformig kommer en sfärisk ljudvågsutbredning att ske mot väggen, ju bredare vägg desto större fasskillnad ut mot kanterna - avståndet är ju längre och det finns ingen metod att "förlänga" ljudvågen (om det är "samma luft" i hela rummet)
Vad som däremot sker vid resonans mellan väggarna är att ljudvågen sprider ut sig när den studsar mellan väggarna och så småningom kommer en plan, stående våg att skapas mellan väggarna. I det skedet är de reflekterande väggarna "ljudkälla".
Vid Högtalarmätningar är alltså en plan vågfront egentligen en snygg och homogen sfärisk vågfront där radien är så stor att ett mikrofonmembran uppfattar vågfronten som plan vid den högsta frekvens som mätningen sker vid. = det dynamiska trycket är jämnt fördelat över membranet.
*tyvärr mäts de flesta hifi högtalare upp på 1 meters avstånd, man borde mäta på mycket längre avstånd t.ex minsta lyssningsavstånd som borde vara klart över 2 meter. Att rumsmätningar då är svåra att genomföra vid direktljudsmätning är trist men inget att göra åt.
Jag bör tillägga att vid de otal simuleringar vi gjort så har det varit 2 basmoduler utmed en vägg på ungefär 4-6 meter från varandra och även med center bas och med 4 eller 5 basar utplacerade i rummet längs med väggar och hörn. Jag glömde skriva det. Då tittar vi på vågutbredning i 2 dimensioner respektive i 3 dimensioner. Basmoduler har placerats i hörn på samma vägg. basmodulerna har även placerats 85 cm från vägg. Sedan gör vi filmer av den simulerade vågutbredningen samt har ett antal mätpunkter i rummet så man kan se hur frekvensgången ser ut i respektive punkt och förändras i tiden vartefter vågorna utbreder sig i rummet fram och tillbaka. Först tänkte jag att vi skulle lägga upp filmer här i gif-format, men det visade sig bli mycket stora filer d v s strax under 1 GB per animering.
Det är oerhört lärorikt att se dessa animeringar och hur avståndet till bakre vägg, från högtalaren sett, ödelägger direktljudet eftersom reflexen då är parallell med direktljudet samt går i samma riktning. Det är lika intressant att se hur reflexer från sidoväggar inte påverkar direktljudet och då får vi simulera Intensitet. Dessutom var det intressant att se hur det ser ut i basen från planstrålare då man tar hänsyn till proximyeffekten samt tittar på realdel och imaginärdel och behandlar ljudvågorna som reaktiva. Det var i september 2018 vi höll på med detta och jag måste sätta mig in i resultaten ånyo innan jag ger mig in i närmare beskrivningar.
Med vänlig hälsning Peter
Hade varit väldigt kul att se de simuleringarna. Jag insåg att olika ljudvågor måste ha samma riktning för att kunna släcka ut eller förstärka varandra i större område av rummet. Det förklarar kanske iaf delvis varför olika invinkling av högtalare relativt begränsningsytor kan göra så stor skillnad.
Jag har fininställt mina högtalare (magnitud per varje enskilt element följer sin måltonkurva perfekt) efter mätningar i öronhöjd i lyssningsposition, 5 punkter inom 50cm som punkterna på tärningen-5, medelvärde. Lyssningspositionen är 4m från högtalare. 2 m från vägg bakom lyssnaren.
Peter, vad säger du om den metoden? Min tanke är att medelvärdet jämnar ut påverkan från individuella reflexer från sidoväggar, vägg bakom lyssnaren, tak och golv. Alltså påverkan från de reflexer som har annan riktning än direktljudet ”tas bort” till stor del ur mätningen (magnitudmässigt). Jag skulle väl ha mätt i olika höjd då också för att få till detta ännu mer. Det är först nu jag kopplar ihop riktningen på reflexerna i 3 dimensioner med detta mätförfarandet. Jag har mer tänkt på det som reflexers olika avstånd till begränsningsytor tidigare, att det är det som jag viktat bort med medelvärde.
Även tidskompensering (individuell delay per element satt för maximal utsläckning i fasvänd delning) baserar jag från lyssningsposition, fast från en enskild mätning/punkt. Den mätpunkten med jämnast frekvensgång i delningsområdet (den med troligtvis minst påverkan av reflexer i det frekvensområdet).
Reflexers olika ankomsttid relativt mänskliga hörselns integrering mm är inte beaktat i denna metoden magnitudmässigt, det är väl en svaghet kanske? Jag har funderat på om jag ska ha tidsfönster på mätningarna också. Eller om de reflexer som kommer sent ändå har försvagats magnitudmässigt så mycket under resans gång att det löser sig själv i medelvärdesbildningen, att de får mindre påverkan ändå. Så ser det ut för mig när jag tittar på reflexernas ankomsttider i ETC-diagram för enskild mätpunkt. Senare reflexer än 2ms ligger alla under -10dB direktljudet som högst. Fast samtidigt, jag tänker mig att ALLA reflexers (med annan riktning är direktljudet) påverkan magnitudmässigt medelvärdesförsvunnit, så skit samma vilken tid de anländer egentligen.
Reflexer som kommer i samma riktning som direktljudet kan man betrakta som en del av direktljudet, Peter? I alla fall inom ett visst tidsområde antar jag. Inom typ 10ms?
Senast redigerad av rajapruk 2019-11-29 10:51, redigerad totalt 4 gånger.
jansch skrev: Först och främst Peter - heder åt dej att du har ork och ambition att ge ett så uttömmande svar.
Vet inte om jag misstolkar det du skrivit i citatet ovan, men det är inte riktgt korrekt enligt min mening. Den övriga texten i ditt inlägg håller jag helt med om.
Vågen kommer inte vara plan i den mening att den är parallell med väggen efter 2 meter om vi har en normal ljudkälla där ljudkällans storlek är väsentligt mindre än våglängden ( vilket den normalt är i hifi sammanhang).
Vid MÄTNINGAR på en typisk ljudkälla, t.ex en normal hifi högtalare, anser man att ljudvågen är plan för en mätmikrofon efter ca 2 meter*. Detta är dock väldigt beroende av avstånd mellan högtalarelement, elementens utformning, höljet, basport, mm. Det tar alltså tid (sträcka) för ljudvågen att forma sig då ljudkällan inte är punktformig. ( eller inte är kolvformig och väldigt stor). Då ljudkällan trots allt är är någorlunda punktformig kommer en sfärisk ljudvågsutbredning att ske mot väggen, ju bredare vägg desto större fasskillnad ut mot kanterna - avståndet är ju längre och det finns ingen metod att "förlänga" ljudvågen (om det är "samma luft" i hela rummet)
Vad som däremot sker vid resonans mellan väggarna är att ljudvågen sprider ut sig när den studsar mellan väggarna och så småningom kommer en plan, stående våg att skapas mellan väggarna. I det skedet är de reflekterande väggarna "ljudkälla".
Vid Högtalarmätningar är alltså en plan vågfront egentligen en snygg och homogen sfärisk vågfront där radien är så stor att ett mikrofonmembran uppfattar vågfronten som plan vid den högsta frekvens som mätningen sker vid. = det dynamiska trycket är jämnt fördelat över membranet.
*tyvärr mäts de flesta hifi högtalare upp på 1 meters avstånd, man borde mäta på mycket längre avstånd t.ex minsta lyssningsavstånd som borde vara klart över 2 meter. Att rumsmätningar då är svåra att genomföra vid direktljudsmätning är trist men inget att göra åt.
Jag bör tillägga att vid de otal simuleringar vi gjort så har det varit 2 basmoduler utmed en vägg på ungefär 4-6 meter från varandra och även med center bas och med 4 eller 5 basar utplacerade i rummet längs med väggar och hörn. Jag glömde skriva det. Då tittar vi på vågutbredning i 2 dimensioner respektive i 3 dimensioner. Basmoduler har placerats i hörn på samma vägg. basmodulerna har även placerats 85 cm från vägg. Sedan gör vi filmer av den simulerade vågutbredningen samt har ett antal mätpunkter i rummet så man kan se hur frekvensgången ser ut i respektive punkt och förändras i tiden vartefter vågorna utbreder sig i rummet fram och tillbaka. Först tänkte jag att vi skulle lägga upp filmer här i gif-format, men det visade sig bli mycket stora filer d v s strax under 1 GB per animering.
Det är oerhört lärorikt att se dessa animeringar och hur avståndet till bakre vägg, från högtalaren sett, ödelägger direktljudet eftersom reflexen då är parallell med direktljudet samt går i samma riktning. Det är lika intressant att se hur reflexer från sidoväggar inte påverkar direktljudet och då får vi simulera Intensitet. Dessutom var det intressant att se hur det ser ut i basen från planstrålare då man tar hänsyn till proximyeffekten samt tittar på realdel och imaginärdel och behandlar ljudvågorna som reaktiva. Det var i september 2018 vi höll på med detta och jag måste sätta mig in i resultaten ånyo innan jag ger mig in i närmare beskrivningar.
Med vänlig hälsning Peter
OK, du bygger upp en "line array högtalare". Med få högtalare utspridda i en linje kommer ett smalt frekvensområde att spridas med någorlunda plan vågfront i horisontalplanet. Rummets avgränsningar kommer också i viss mån att hjälpa till. Detta kräver säkerligen datorsimulering/animation för att få grepp om hur line array påverkas av rummet. Normalt arbetar ju line arrays i frifält eller extremt stora rum.
Jag skulle nog säga att det är motsatt: En line array i basen är busenkel och jag kan just nu inte komma på någon variant som skulle vara enklare att hantera rumsmässigt, i basen alltså. petersteindl's varianter med basar uppe och nere och med centerbas blir förståss en annan histora, men enkel i förhållande till planceirng ute i rummet, som nästan alla håller på med och som är ett rent hopplöst projekt att få bra. Ju fler möjligheter (olika rikningar) som ljudet kan smita iväg med desto värre blir det. I basen är högtalare rundstrånadet, så det gäller att se til att ljudet egentligen bara kan gå en väg: framåt.
Väldigt bra inlägg av petersteindl tidigare i tråden, ett av årets bästa!
Denna signatur är endast för privat bruk. Vänligen läs ej!
Max_Headroom skrev: Jag skulle nog säga att det är motsatt: En line array i basen är busenkel och jag kan just nu inte komma på någon variant som skulle vara enklare att hantera rumsmässigt, i basen alltså. petersteindl's varianter med basar uppe och nere och med centerbas blir förståss en annan histora, men enkel i förhållande till planceirng ute i rummet, som nästan alla håller på med och som är ett rent hopplöst projekt att få bra. Ju fler möjligheter (olika rikningar) som ljudet kan smita iväg med desto värre blir det. I basen är högtalare rundstrånadet, så det gäller att se til att ljudet egentligen bara kan gå en väg: framåt.
Väldigt bra inlägg av petersteindl tidigare i tråden, ett av årets bästa!
Förstår inte din kommentar..... En plan vågfront krävs väl inte för att det ska låta bra? Det kan däremot vara en nackdel men med få, utspridda basar skapas ingen line array som täcker ett normalt basregister. För det krävs att basarna placeras väsentligt tätare än våglängden.
Max_Headroom skrev:Väldigt bra inlägg av petersteindl tidigare i tråden, ett av årets bästa!
Håller med! Vill samtidigt uppmana alla att våga fråga de "dumma" frågorna ibland. Det är ofta då faktiskt.io kollektivt skiner till, tycker jag.
Som glad amatör så är jag glad då mer info kommer fram. Även om jag inte förstår allt Peter och Jansch skriver ovan så har jag numera en hel del mäterfarenhet . Det bästa är att testa teori och praktik .
Det är även så att konstruktörer på väldigt hög nivå diffar i hur de går tillväga för att skapa det perfekta ljudet. Det man kan vara överens om är fysiken men man har helt olika filosofier hur illusionen ska utföras i ett lyssningsrum. Peter S, IÖ, Phil Budd, Rod Crawford, Carlsson, Naqref, Kevin Voecks, Peter Snell, Troelsgravesen, Toole, linkwitz, har alla lite olika recept på det perfekta ljudet.
Mina egna experiment med högtalare kloss mot väggen och utan dämpning de närmaste 2 ms runt högtalaren har inte utfallit positivt. Möjligen krävs det väldigt speciell konstruktion för att det ska fungera.
Själv försöker jag optimera klassisk tvåvägskonstruktion på stativ en bit ut i rummet.
Rajapruk: har du en tjock matta på golvet framför högtalarna eller kör du med odämpat golv ?
petersteindl skrev:Resonanser mellan 2 parallella väggar i rum innebär att en forcerad ljudvåg exempelvis sinusoid som reflekteras i vägg och därefter går i motsatt riktning samtidigt som inkommande sinusvåg fortsätter så uppstår en summa av dessa. Först uppstår en stående våg. I resonans, vars frekvens ges av avståndet mellan väggarna, så fortsätter fenomenet med att amplituden ökar i vissa punkter längs med linjen mellan väggarna. Eftersom vågen fortskridit mer än 2 meter i rummet så betraktas den som plan och detta plan är parallellt med väggarna. Det blir två plana ljudvågor som går åt varsitt håll mellan väggarna och summeras i varje punkt enligt superpositionsprincipen.
Först och främst Peter - heder åt dej att du har ork och ambition att ge ett så uttömmande svar.
Vet inte om jag misstolkar det du skrivit i citatet ovan, men det är inte riktgt korrekt enligt min mening. Den övriga texten i ditt inlägg håller jag helt med om.
Vågen kommer inte vara plan i den mening att den är parallell med väggen efter 2 meter om vi har en normal ljudkälla där ljudkällans storlek är väsentligt mindre än våglängden ( vilket den normalt är i hifi sammanhang).
Vid MÄTNINGAR på en typisk ljudkälla, t.ex en normal hifi högtalare, anser man att ljudvågen är plan för en mätmikrofon efter ca 2 meter*. Detta är dock väldigt beroende av avstånd mellan högtalarelement, elementens utformning, höljet, basport, mm. Det tar alltså tid (sträcka) för ljudvågen att forma sig då ljudkällan inte är punktformig. ( eller inte är kolvformig och väldigt stor). Då ljudkällan trots allt är är någorlunda punktformig kommer en sfärisk ljudvågsutbredning att ske mot väggen, ju bredare vägg desto större fasskillnad ut mot kanterna - avståndet är ju längre och det finns ingen metod att "förlänga" ljudvågen (om det är "samma luft" i hela rummet)
Vad som däremot sker vid resonans mellan väggarna är att ljudvågen sprider ut sig när den studsar mellan väggarna och så småningom kommer en plan, stående våg att skapas mellan väggarna. I det skedet är de reflekterande väggarna "ljudkälla".
Vid Högtalarmätningar är alltså en plan vågfront egentligen en snygg och homogen sfärisk vågfront där radien är så stor att ett mikrofonmembran uppfattar vågfronten som plan vid den högsta frekvens som mätningen sker vid. = det dynamiska trycket är jämnt fördelat över membranet.
*tyvärr mäts de flesta hifi högtalare upp på 1 meters avstånd, man borde mäta på mycket längre avstånd t.ex minsta lyssningsavstånd som borde vara klart över 2 meter. Att rumsmätningar då är svåra att genomföra vid direktljudsmätning är trist men inget att göra åt.
Jo, det är ju kompromisser vid mätning 1,3 meter ifrån högtalaren. Men vad gör man, problemet blir ju att man mäter hela rummet med längre mätavstånd ? Och miken fungerar inte som hur hörseln tolkar över 2 ms eller längre ?
petersteindl skrev:Resonanser mellan 2 parallella väggar i rum innebär att en forcerad ljudvåg exempelvis sinusoid som reflekteras i vägg och därefter går i motsatt riktning samtidigt som inkommande sinusvåg fortsätter så uppstår en summa av dessa. Först uppstår en stående våg. I resonans, vars frekvens ges av avståndet mellan väggarna, så fortsätter fenomenet med att amplituden ökar i vissa punkter längs med linjen mellan väggarna. Eftersom vågen fortskridit mer än 2 meter i rummet så betraktas den som plan och detta plan är parallellt med väggarna. Det blir två plana ljudvågor som går åt varsitt håll mellan väggarna och summeras i varje punkt enligt superpositionsprincipen.
Först och främst Peter - heder åt dej att du har ork och ambition att ge ett så uttömmande svar.
Vet inte om jag misstolkar det du skrivit i citatet ovan, men det är inte riktgt korrekt enligt min mening. Den övriga texten i ditt inlägg håller jag helt med om.
Vågen kommer inte vara plan i den mening att den är parallell med väggen efter 2 meter om vi har en normal ljudkälla där ljudkällans storlek är väsentligt mindre än våglängden ( vilket den normalt är i hifi sammanhang).
Vid MÄTNINGAR på en typisk ljudkälla, t.ex en normal hifi högtalare, anser man att ljudvågen är plan för en mätmikrofon efter ca 2 meter*. Detta är dock väldigt beroende av avstånd mellan högtalarelement, elementens utformning, höljet, basport, mm. Det tar alltså tid (sträcka) för ljudvågen att forma sig då ljudkällan inte är punktformig. ( eller inte är kolvformig och väldigt stor). Då ljudkällan trots allt är är någorlunda punktformig kommer en sfärisk ljudvågsutbredning att ske mot väggen, ju bredare vägg desto större fasskillnad ut mot kanterna - avståndet är ju längre och det finns ingen metod att "förlänga" ljudvågen (om det är "samma luft" i hela rummet)
Vad som däremot sker vid resonans mellan väggarna är att ljudvågen sprider ut sig när den studsar mellan väggarna och så småningom kommer en plan, stående våg att skapas mellan väggarna. I det skedet är de reflekterande väggarna "ljudkälla".
Vid Högtalarmätningar är alltså en plan vågfront egentligen en snygg och homogen sfärisk vågfront där radien är så stor att ett mikrofonmembran uppfattar vågfronten som plan vid den högsta frekvens som mätningen sker vid. = det dynamiska trycket är jämnt fördelat över membranet.
*tyvärr mäts de flesta hifi högtalare upp på 1 meters avstånd, man borde mäta på mycket längre avstånd t.ex minsta lyssningsavstånd som borde vara klart över 2 meter. Att rumsmätningar då är svåra att genomföra vid direktljudsmätning är trist men inget att göra åt.
Jo, det är ju kompromisser vid mätning 1,3 meter ifrån högtalaren. Men vad gör man, problemet blir ju att man mäter hela rummet med längre mätavstånd ? Och miken fungerar inte som hur hörseln tolkar över 2 ms eller längre ?
Mät i exakt samma riktning på 30 cm, 50 cm, 80 cm och 1,3 meter. Det skall vara direktljudets riktning. Du kan dels sätta högtalaren mitt i rummet vid mätning med mikrofonen så långt som möjligt från väggar golv och tak. Sedan kan du ställa in tidsfönstret allt efter behag. Sedan kan du ha högtalaren på befintligt använd högtalarposition och mäta samma mätsekvens. Tippar att högtalaren är närmare vägg då.
Dessutom kan jag säga att det som du tror hur hörseln fungerar inom 2 ms, är inte ens i närheten av hur hörseln verkligen fungerar, åtminstone av det du gång på gång skriver.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
Jag fann det mycket användbart när jag konstruerade mina SLAM!
Väldigt bra skript Men det hanterar inte rumspåverkan....Eller är jag dåligt uppdaterad?
Då få man nog tänka till lite:
HenrikE skrev:Är det reflexerna från sidoväggarna du vill åt? Det går att skapa flera källor som är aktiva samtidigt. Jag har inte testat men det borde funka att definiera flera källor där en av dem är den "riktiga" och övriga är dess spegelbilder. Skulle det kunna ge något i stil med vad du är ute efter?
jansch skrev:Tangband -Du är mycket ambitiös och ivrig att lära dej. Väldigt imponerande och jag hoppas att du ser positivt på den kritik du får.
Vi borde nog Starta en ny tråd om hur hörseln uppfattar ljud. Eller rättare sagt UPPLEVER ljud I olika situationer.
Hörseln är ju inte "endimensionell" den mening att t.ex en fördröjning på 2ms alltid tolkas på samma sätt.
Det finns dock en "risk" med en sådan tråd då vi ger oss in i psykoakustikens värld där det är ont om absoluta sanningar.
Tack Jansch, jag har lärt mig mycket av dig och Peter mfl. säkert även missuppfattat en del teori- jag gör därför hela tiden praktiska experiment med egna mätningar och inspelningar.
Jag kan inte mycket av det teoretiska, är en gröngöling jämfört med Peter och dig Jansch, men mina egna experiment med både inspelningar med mikrofoner av tex flygel , samt uppspelning hemmavid är att det händer något dramatiskt i skillnaden mellan hur en mikrofon fungerar och hur hörseln tolkar och selekterar ljud vid avstånd kring 70-80 cm eller mer . https://en.m.wikipedia.org/wiki/Precedence_effect Kanske är det fel av mig att kalla det precedenceeffekten, kanske borde det kallas något annat, men min upplevelse av skillnaden mellan mikrofonen och hörselns selektering av ljud gör att jag vill dämpa alla ytor som befinner sig mindre än 2 ms ljudväg från högtalaren. Ljudet blir markant bättre om man gör det. Har man en stativhögtalare kan man lätt experimentera själv , och där har jag funnit att ljudet blir markant bättre med gångväg element-framvägg på minst 43 cm = 86 cm med ljudstudsen. Dämpar man en stor yta bakom högtalaren kan man placera den närmare framväggen. En heltäckningsmatta på golvet under och framför stativhögtalaren gör ljudet dramatiskt bättre. Takreflexerna är mindre problematiska eftersom de sker i tid senare än golvreflexerna. Långt senare än 2 ms. Högtalaren är ju nästan alltid placerad närmare golvet .
Nedan ses den rekommenderade dämpningen bakom piP . Är ytan på dämpningen en slump ?
Senast redigerad av Tangband 2019-11-29 22:01, redigerad totalt 6 gånger.
Några bilder kan kanske illustrera en del av vad som händer. Det sker en maskering av upplevelsen av ljud som kommer lite fördröjt i förhållande till direktljudet. Mikrofonen däremot har ingen selektering utan tar in all information. Därför blir mätningar långt från högtalaren i rum med mycket efterklang väldigt missvisande. Mikrofonen kommer att visa information som hjärnan i verkligheten till dels selekterar bort och tolkar på helt annat sätt.
Att mikrofonen och hörseln fungerar helt olika efter 2 ms får även stora konsekvenser vid inspelning . Bästa lyssningsplatsen i konsertsalen är inte bästa upptagningsplatsen för mikrofonen. Tex kan en flygel spelas in med mikrofonen på 70-100cm avstånd där ljudet sedan i stereon hemma låter som om man satt på bästa platsen, fjärde raden i konsertlokalen, 7 meter ifrån. Som ett exempel. http://www.torgny.biz/Recording%20sound_1.htm
Senast redigerad av Tangband 2019-11-29 22:03, redigerad totalt 1 gång.
jansch skrev:Tangband -Du är mycket ambitiös och ivrig att lära dej. Väldigt imponerande och jag hoppas att du ser positivt på den kritik du får.
Vi borde nog Starta en ny tråd om hur hörseln uppfattar ljud. Eller rättare sagt UPPLEVER ljud I olika situationer.
Hörseln är ju inte "endimensionell" den mening att t.ex en fördröjning på 2ms alltid tolkas på samma sätt.
Det finns dock en "risk" med en sådan tråd då vi ger oss in i psykoakustikens värld där det är ont om absoluta sanningar.
Jag kan inte mycket av det teoretiska, men mina egna experiment med både inspelningar med mikrofoner av tex flygel , samt uppspelning hemmavid är att det händer något dramatiskt i skillnaden mellan hur en mikrofon fungerar och hur hörseln tolkar och selekterar ljud vid avstånd kring 70-80 cm eller mer . https://en.m.wikipedia.org/wiki/Precedence_effect Kanske är det fel av mig att kalla det precedenceeffekten, kanske borde det kallas något annat, men min upplevelse av skillnaden mellan mikrofonen och hörselns selektering av ljud gör att jag vill dämpa alla ytor som befinner sig mindre än 2 ms ljudväg från högtalaren. Ljudet blir markant bättre om man gör det. Har man en stativhögtalare kan man lätt experimentera själv , och där har jag funnit att ljudet blir markant bättre med gångväg element-framvägg på minst 43 cm = 86 cm med ljudstudsen.
Nedan ses den rekommenderade dämpningen bakom piP . Är ytan på dämpningen en slump ?
Det är inte bara hörseln i sig som selekterar ljud, det är hjärnan och det hela varierar med vad man väljer att koncentrera sig på, den så kallade cocktail-party effekten.
The cocktail party effect is the phenomenon of the brain's ability to focus one's auditory attention (an effect of selective attention in the brain) on a particular stimulus while filtering out a range of other stimuli, as when a partygoer can focus on a single conversation in a noisy room. https://en.wikipedia.org/wiki/Cocktail_party_effect
Det är med hjälp av alla sinnen som man ofta kan avnjuta ett egentligen ganska illa-låtande live-framförande och gå därifrån med intrycket att det lät fantastiskt. Samma fenomen sker när man ser musiker spela live i ett youtube klipp där man först när man blundar inser att det egentligen låter ganska dåligt.
När man ser exempelvis basisten spela framför sig så kan man med så pass djup koncentration fullständigt grotta ner sig i hans spelande, till den grad att man nästan helt kan solla bort de övriga instrumenten, och detta även i de fall där basgitarren kanske nästan egentligen var fullständigt begravd i de övriga ljuden.
Detta fenomen, eller kanske ska man istället kalla det för sinnets förmåga att selektivt sålla fram det man för stunden vält att koncentrera hörandet på, går helt enkelt inte lika bra på en inspelning som i grund och botten minskats ned från helt enskilda ljudkällor och mixats ned till två enstaka kanaler som spelas upp i endast två ljud-utstrålare, stereo-högtalarna.
Vi som lyssnar på inspelad musik sitter mångt och mycket i händerna på den tolkning mixaren har gjort av framförandet, han/hon har i de flesta inspelningar tillgång till närmickade ljudupptagningar där han kan framhäva exempelvis ett solo av ett enskilt instrument genom att försiktigt höja den kanalen i mixen. Ett ypperligt exempel är ju den fina inspelningen "Jazz at the Pawnshop" där det användes två huvudsakliga mikrofoner för att fånga helheten, en eller två mikrofoner för att fånga sorlet från publiken och resten av lokalen, och sen 4-5 nära mikrofoner för enskilda instrument där nivån ändras i mixen för att framhäva solon eller särskilt viktiga element under mixningen. Mycket snyggt gjort av en inspelningstekniker med känsla, herr Gert Palmcrantz.
Närmickning är helt enkelt ett väldigt viktigt verktyg för att komma runt stereo-uppspelningens tillkortakommanden i kombination med att man lyssnar "blint" och därmed försvårar möjligheten till "Cocktail-party effekten".
rajapruk skrev:Jag har fininställt mina högtalare (magnitud per varje enskilt element följer sin måltonkurva perfekt) efter mätningar i öronhöjd i lyssningsposition, 5 punkter inom 50cm som punkterna på tärningen-5, medelvärde. Lyssningspositionen är 4m från högtalare. 2 m från vägg bakom lyssnaren.
Peter, vad säger du om den metoden? Min tanke är att medelvärdet jämnar ut påverkan från individuella reflexer från sidoväggar, vägg bakom lyssnaren, tak och golv. Alltså påverkan från de reflexer som har annan riktning än direktljudet ”tas bort” till stor del ur mätningen (magnitudmässigt). Jag skulle väl ha mätt i olika höjd då också för att få till detta ännu mer. Det är först nu jag kopplar ihop riktningen på reflexerna i 3 dimensioner med detta mätförfarandet. Jag har mer tänkt på det som reflexers olika avstånd till begränsningsytor tidigare, att det är det som jag viktat bort med medelvärde.
Även tidskompensering (individuell delay per element satt för maximal utsläckning i fasvänd delning) baserar jag från lyssningsposition, fast från en enskild mätning/punkt. Den mätpunkten med jämnast frekvensgång i delningsområdet (den med troligtvis minst påverkan av reflexer i det frekvensområdet).
Reflexers olika ankomsttid relativt mänskliga hörselns integrering mm är inte beaktat i denna metoden magnitudmässigt, det är väl en svaghet kanske? Jag har funderat på om jag ska ha tidsfönster på mätningarna också. Eller om de reflexer som kommer sent ändå har försvagats magnitudmässigt så mycket under resans gång att det löser sig själv i medelvärdesbildningen, att de får mindre påverkan ändå. Så ser det ut för mig när jag tittar på reflexernas ankomsttider i ETC-diagram för enskild mätpunkt. Senare reflexer än 2ms ligger alla under -10dB direktljudet som högst. Fast samtidigt, jag tänker mig att ALLA reflexers (med annan riktning är direktljudet) påverkan magnitudmässigt medelvärdesförsvunnit, så skit samma vilken tid de anländer egentligen.
Reflexer som kommer i samma riktning som direktljudet kan man betrakta som en del av direktljudet, Peter? I alla fall inom ett visst tidsområde antar jag. Inom typ 10ms?
Intressanta frågeställningar. Jag tror det är väsentligt kortare tid än 10 ms. Vad upplever du själv ? Prova tex och dämpa 2 ms runt dina högtalare ( ca 70 cm åt alla håll, även golvet ) Låter det annorlunda ?
Tangband skrev:Goat76 - örat med hjärnan är verkligen fantastiskt
Ja, visst är det fantastiskt och det är en ganska tydlig förminskning som sker vid stereo-lyssning.
De "ljudfenomen" som vi ser som självklart skadliga för uppfattningen av ljudåtergivningen gjorda med ett gäng mikrofoner, nermixat till ynka två kanaler och sedan uppspelat med endast två högtalare i ett medelstort bostadsrum med alla de tänkbara problem det medför behöver nödvändigtvis inte alla ha varit av skadlig karaktär vid naturlig lyssning vid ursprungshändelsen.
Det vi tvingas sålla bort p.g.a. denna förminskning eller "fördummning" (d.v.s. nedmixat och uppspelat i två ynka kanaler) av den ursprungliga riktiga musikhändelsen där var och ett av alla ljudkällor tilläts placeras där de lät bäst i lokalen, kan mycket väl istället mycket väl ha varit väldigt viktiga hörnstenar eller naturliga "ljudfenomen" för den verkliga ljudhändelsen.
Jag vill exemplifiera en sak för flera på faktiskt, dock speciellt för JM och för tangband. Det gäller direktljudet från Bremen 3D8 även kallad äggen. Hur ser direktljudet i diskanten ut? Det spekuleras ju en del. Låt oss se hur en sådan konfiguration kan te sig.
Det är diskanterna utan delningsfilter som är uppmätt. Mätningarna är gjorda av lilltroll. Alla mätningar är med mätmikrofon på 0,5 meter från direktdiskanten och i den vinkel som jag använder som direktljudsvinkel vid praktisk lyssning d v s 45 grader horisontalvinkel. Jag vill visa hur det ser ut inom 1 ms och det på direktljudet.
Mätningar 1a och 1b är med ägget placerad någon meter ut i rummet d v s utan närhet till vägg. Mätningen är enkom med direktdiskanten inkopplad och utan närhet till vägg. Alltså, enbart 1 diskant monterad i högtalarhölje utan påverkan från någon vägg.
1a 3D8 på stativ direkt_diskant direct-axis 1000us.png (98.64 KiB) Visad 7883 gånger
1b 3D8 på stativ direkt_diskant direct-axis 1500us.png (101.2 KiB) Visad 7883 gånger
Här ser man att allt händer redan inom 1 ms. Tonkurvan ser ut som diskantelementet gör monterad på stor plan baffel.
Vi utgår från denna kurva och vill få fram dels hur den skuggade diskanten påverkar direktljudet, dels hur väggreflexen från direktdiskanten påverkar direktljudet, dels hur direktljudet blir med direktdiskant + skuggad diskant samt med inkluderade tidiga väggreflexer d v s verkliga direktljudet från en Bremen 3D8 med båda diskanter inkopplade och monterad på vägg.
Mätningar 2a och 2b är med ägget någon meter ut i rummet d v s utan närhet till vägg. Dock, nu är båda diskanterna inkopplade. Det betyder att man mäter den skuggade diskantens påverkan på direktdiskanten och förändrar därmed tonkurvan i den riktning (vektor) som är direktljudet.
2a 3D8 på stativ med 2 diskanter direct-axis 1000us.png (100.57 KiB) Visad 7883 gånger
Här syns en svacka som uppstår från 2 kHz till 4 kHz runt 2,7 kHz. Man kan även se en liten svacka kring 8 kHz. Detta är den skuggade diskantens påverkan.
2b 3D8 på stativ diskanter direct-axis 1500us.png (102.47 KiB) Visad 7883 gånger
Denna mätning tillför inget nytt och indikerar att förloppet håller sig inom 1 ms.
Vi använder fönstring som visas. Vi har fönstring på 1 ms och 1,5 ms för att få med hela pulsen från båda diskanter + reflexer och för att se om extra 0,5 ms ger ytterligare info. 2,5 ms samt 4 ms har vi med för att se om vi kan lokalisera ännu ytterligare oväntade reflexers inverkan som i så fall skulle kunna ge möjliga otäcka nollställen. Detta för att se huruvida olika reflexer möjligtvis inverkar och i så fall möjligtvis förändrar första 1,5 ms. Det finns dock i mätningen inget mellan 1,5 ms och 4 ms som påverkar direktljudet som vi skall se.
Här gäller det att förstå att direktdiskanten mäts först och främst med 1 ms. Skall man få med den andra diskanten som kommer senare så måste även fönstringen fördröjas i proportion annars trunkeras påverkan från den senare signalen. Signalerna ligger så pass tätt att inget av väsentlighet förändras inom närmaste millisekunder. Alltså, för säkerhets skull har vi även en fönstring på 1,5 ms. Samma gäller spegelbildens diskanter bakom vägg gällande väggreflexen, man måste möjligtvis ha med något längre tid än 1 ms fönstring för att få med hela impulsen. Låt oss se.
Mätningar 3a, 3b och 3c är med ägget monterat på vägg. Dock, nu är enkom direktdiskanten inkopplad. Det betyder att man enkom mäter väggreflexens påverkan på direktdiskanten där väggreflexen därmed påverkar tonkurvan i den riktning som är direktljudet.
3a 3D8 på vägg direkt_diskant direct-axis 1500us.png (104.72 KiB) Visad 7883 gånger
Här ser man att det uppstår en svacka mellan 3 kHz och 5 kHz centrerat kring 4,2 kHz. Det syns även en svacka kring 12 kHz. Detta är väggreflexens påverkan.
3b 3D8 på vägg direkt_diskant direct-axis 2500us.png (110.17 KiB) Visad 7883 gånger
Här framstår inget nytt.
3c 3D8 på vägg direkt_diskant direct-axis 4000us.png (112.4 KiB) Visad 7883 gånger
Inte här heller. Allt inträffar inom 1,5 ms och egentligen inom 1 ms.
Nu placeras ägget mot vägg och båda diskanter strålar d v s såsom högtalaren skall användas. Hur blir det då? Fås alla interferenser såsom destruktiva, eller kan man placera diskanterna skickligt så att destruktiva och konstruktiva interferenser tar ut varandra? Det är ju totalen som är det intressanta. Låt oss se. Mätningar 4a, 4b och 4c är med ägget monterat på vägg. Dock, nu är både direktdiskanten samt den skuggade diskanten inkopplade. Det betyder att man mäter både den skuggade diskantens inverkan på direktdiskanten samt båda diskanters väggreflexers påverkan på direktdiskanten och totalen inverkar därmed på tonkurvan i den riktning som är direktljudet.
4a 3D8 på vägg med 2 diskanter direct-axis 1500us.png (105.08 KiB) Visad 7883 gånger
Här ser man hela högtalarens direktljud. Vi skulle med lätthet kunna minska fönstringen till 1 ms. Man kan också se att med 2 diskanter och placerad vid vägg med rätt vinklar och rätt avstånd åt alla håll och kanter och med rätt spridningsmönster från diskanterna så blir faktiskt summan ett direktljud mot lyssnaren som är rätt nära direktljudet från högtalaren såsom den vore enkom med 1 diskant monterad på stor baffel i frifält. Så illa pinkat anser jag slutresultatet inte vara. Möjligtvis att 5,5 kHz skulle kunna vara 1,5 dB lägre i nivå? och 6,3 kHz 1 dB starkare. Det kan möjligtvis åtgärdas eller förbättras med lite fårullsmatta på lämplig plats. Vi har gjort massor med sådana mätningar. I total utstrålad energi är tonkurvan väldigt rak, även i detta område. I klartext anser jag mig ha åstadkommit en vägghögtalare utan artefakter från väggen d v s enkom med väggens positiva inverkan.
Detta gäller inom 1 ms och på direktljudet. Tippar att alla som spekulerat mycket sämre resultat nu kan ha fått något att tänka på. Man kan faktiskt använda saker till sin fördel som andra inte klarat av och därför kastar ut barnet med badvattnet. Jag gillar dock att gå till botten med det jag gör.
4b 3D8 på vägg med 2 diskanter direct-axis 2500us.png (109.18 KiB) Visad 7883 gånger
Här syns inget nytt.
4c 3D8 på vägg med 2 diskanter direct-axis 4000us.png (119.65 KiB) Visad 7883 gånger
Här är det lite krusningar som inte tillhör diskantens direktljud.
Vi har även gjort mätningar på ungefär 1,2 meters avstånd och då kan man jämföra. Finns samma fel i båda så är det den vektorn d v s den riktningen d v s i detta fall direktljudet.
Hoppas att informationen kan vara till nytta och att JM, tangband och andra förstår att det finns en del tankar bakom konstruktionen och att det finns fog för hur högtalaren är utformad. Man kan faktiskt med olämplig placering av diskanter och olämpligt spridningsmönster och olämpligt mått till vägg få ett slutresultat som är enkom destruktivt på direktljudet d v s med massor med kamfiltereffekt.
Avslutningsvis vill jag påpeka att svackorna inte är så breda som det ser ut på kurvorna eftersom kurvorna inte visar lägre frekvens än 500 Hz. Skulle kurvorna redovisas 20 Hz till 20 kHz så skulle de mer se ut som interferens brukar se ut.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
Peter, jag påstår inte att dina högtalare skulle mäta dåligt. Det har jag aldrig påstått. Det verkar krävas otroligt mycket kunskap för att balansera utstrålningarna från de två diskanterna så att man kan dra full nytta av väggmonteringen, utan nackdelar.. Jag antar även att utan den där kunskapen skulle resultatet lätt bli mindre bra . Jag tycker äggen dessutom är skitsnygga och skulle gärna lyssna på ett par.
jansch skrev:Rajapruk - Du måste ha ett extremt dämpat rum?
Dämpning har jag "bara" en tjock golvmatta och en ganska stor soffa fylld med dämpmaterial i alla hålrum. Soffan står ute i rummet, vilket är bra ur dämpsynpunkt.
Sedan är mina högtalare ganska riktade i sin spridning med horn (speciellt vertikalt), och vinklade 45 grader bort från närmaste sidoväggar.
Rummet är stort (ca 70kvm).
Senast redigerad av rajapruk 2019-11-30 01:27, redigerad totalt 2 gånger.
rajapruk skrev:Jag har fininställt mina högtalare (magnitud per varje enskilt element följer sin måltonkurva perfekt) efter mätningar i öronhöjd i lyssningsposition, 5 punkter inom 50cm som punkterna på tärningen-5, medelvärde. Lyssningspositionen är 4m från högtalare. 2 m från vägg bakom lyssnaren.
Peter, vad säger du om den metoden? Min tanke är att medelvärdet jämnar ut påverkan från individuella reflexer från sidoväggar, vägg bakom lyssnaren, tak och golv. Alltså påverkan från de reflexer som har annan riktning än direktljudet ”tas bort” till stor del ur mätningen (magnitudmässigt). Jag skulle väl ha mätt i olika höjd då också för att få till detta ännu mer. Det är först nu jag kopplar ihop riktningen på reflexerna i 3 dimensioner med detta mätförfarandet. Jag har mer tänkt på det som reflexers olika avstånd till begränsningsytor tidigare, att det är det som jag viktat bort med medelvärde.
Även tidskompensering (individuell delay per element satt för maximal utsläckning i fasvänd delning) baserar jag från lyssningsposition, fast från en enskild mätning/punkt. Den mätpunkten med jämnast frekvensgång i delningsområdet (den med troligtvis minst påverkan av reflexer i det frekvensområdet).
Reflexers olika ankomsttid relativt mänskliga hörselns integrering mm är inte beaktat i denna metoden magnitudmässigt, det är väl en svaghet kanske? Jag har funderat på om jag ska ha tidsfönster på mätningarna också. Eller om de reflexer som kommer sent ändå har försvagats magnitudmässigt så mycket under resans gång att det löser sig själv i medelvärdesbildningen, att de får mindre påverkan ändå. Så ser det ut för mig när jag tittar på reflexernas ankomsttider i ETC-diagram för enskild mätpunkt. Senare reflexer än 2ms ligger alla under -10dB direktljudet som högst. Fast samtidigt, jag tänker mig att ALLA reflexers (med annan riktning är direktljudet) påverkan magnitudmässigt medelvärdesförsvunnit, så skit samma vilken tid de anländer egentligen.
Reflexer som kommer i samma riktning som direktljudet kan man betrakta som en del av direktljudet, Peter? I alla fall inom ett visst tidsområde antar jag. Inom typ 10ms?
Intressanta frågeställningar. Jag tror det är väsentligt kortare tid än 10 ms. Vad upplever du själv ? Prova tex och dämpa 2 ms runt dina högtalare ( ca 70 cm åt alla håll, även golvet ) Låter det annorlunda ?
Jag tror att direktjudet lämpligen skall ses som allt före 1-2ms någonting av det ljud som går i riktning rakt mot lyssnaren. Tidsspannet där hörseln lokaliserar ljudet. Men det kan vara helt fel Typ högtalarens impuls + de reflexer man vill räkna till direktljudet i högtalarens design: baffeln, kanske väggen den är monterad mot, etc. Jag tror på det som Adhoc mfl lärt mig, att försöka ha så lite reflexer som möjligt efter direktljudet, alltså ca 2ms fram till ca 20ms. Därefter efter ca 20ms är reflexer av godo (för att hörseln inte integrerar dessa till direktljudet, utan gör större ljudbild av det istället), och så mycket som möjligt typ. Helst snett bakifrån (hmmm, det borde man ju kunna fixa artificiellt med surrounds... Det blev jag sugen på att testa nu!).
Om jag skulle dämpa runt mina högtalare så skulle det bli markant hörbart bättre tror jag. Jag har designat dem för att kunna docka 12cm tjock dämpning mot sidorna. Men jag kan och vill inte ha det så i mitt vardagsrum av utseendeskäl, så det blir bara tråkigt att prova det då känner jag.
Min dröm är att bygga in dem helt i hörnets väggar, och kanske även dämpa runtom, för minsta möjliga tidiga reflexer. Men det är nog för "knasigt" för att någonsin realiseras.
Ok, nu ska jag försöka provocera fram att Peter avslöjar sin centerkanalshemlighet!
Jag tänker göra såhär för att mixa upp 2-kanal till surroundljud att spela i en flerkanalsanläggning med identiska högtalare runtom. Målet är en stor och stabilt centrerad ljudbild, som kan höras från en stor sweetspot, och stereosystemfel reducerade.
1. Jag skickar ut en kopia av ljudet 20ms fördröjt till surroundkanalerna, -3dB kanske. L-kanal går till L surround. R-kanal går till R-surround. Godartade reflexer bakifrån rummet simuleras. Detta ger förhoppningsvis känslan av en större lokal och större ljudbild.
2. Jag jämför L och R kanalerna och hittar allt ljud som är samma i dem. Detta är det ljud som skall upplevas komma från mitten antar jag. Detta ljud skickas till centern. Frågan är sedan om L och R enbart skall spela det för dem unika ljudet, eller även lite av centerns ljud? Det får jag testa mig fram med. Speciellt basen vill man väl nyttja alla högtalare för.
"Jag jämför L och R och hittar allt ljud som är samma i dem" - hur göra det rent praktiskt? Hmmm....
2.1. Nisse = L - ((L + R) / 2) Nisse innehåller alltså L utan allt som är gemensamt med R.
2.2. Bosse = R - ((L + R) / 2) Bosse innehåller alltså R utan allt som är gemensamt med L.
2.3. Centern Kalle skall spela enbart det som är gemensamt i L och R. Kalle = (L - Nisse) + (R - Bosse)
Slutgiltig output: L = Nisse (+ 0.5 Kalle kanske för att mjuka till övergång) R = Bosse (+ 0.5 Kalle kanske för att mjuka till övergång) C = Kalle (-0.5 Kalle om det lagts till Kalle i Nisse och Bosse också)
Plus görs med summering i dsp. Minus görs med summering med en invers/fasvänd i dsp. Division med 2 görs med -3dB i dsp. (Är jag rätt ute här??)
3. Eller så skiter man i allt det här i 2.x ovan, och bara låter C spela: (L+R)/2, fast fördröjt minst 2ms efter L och R. Så centern bara tillför lite mjukt av totala ljudet för att jämna ut stereosystemfel, men det kommer fördröjt efter att hörseln lokaliserat varifrån ljudet skall komma i stereomixen och i lägre amplitud, men ändå inom tiden det integreras tonmässigt av hörseln.
Klockan är mycket. Hjärnan är mosig. Ovan innehåller säkert massa feltänk, men det är det som är meningen. Peter skall provoceras av detta och avslöja företagshemligher i affekt! Om inte Peter skjuter detta fullständigt i sank, så vet vi att jag är på rätt spår
Om rummet ska upplevas som större än det är, tror jag det behövs en "period av tystnad" med mycket svaga / ohörbara, dämpade eller bortstyrda reflektioner från objekt nära högtalarna / framför en.
Resultat förhoppningsvis: Mindre av krokigheter i frekvenskurvan vid lyssningsplats för det först uppfattade ljudet. Reflektioner i musiken, från själva inspelningsrummet eller tillagda i studion kan höras och kommer inte dränkas av det egna rummets reflektioner. Efter "tystnaden", reflektioner, helst från sidan, som är starkare än dom under "tystnadsperioden" och tillräckligt starka för att upplevas. Har det gått typ 20 ms till dess, motsvarar det att gångsträckan är knappt 7 m längre än direktljudets, -alltså upplevs då ett större rum för dom flesta. För musik verkar reflektionstiden kunna sträckas ut betydligt jämfört med tal, utan att dom reflektionerna upplevs som eko.
rajapruk skrev:Ok, nu ska jag försöka provocera fram att Peter avslöjar sin centerkanalshemlighet!
Jag tänker göra såhär för att mixa upp 2-kanal till surroundljud att spela i en flerkanalsanläggning med identiska högtalare runtom. Målet är en stor och stabilt centrerad ljudbild, som kan höras från en stor sweetspot, och stereosystemfel reducerade.
1. Jag skickar ut en kopia av ljudet 20ms fördröjt till surroundkanalerna, -3dB kanske. L-kanal går till L surround. R-kanal går till R-surround. Godartade reflexer bakifrån rummet simuleras. Detta ger förhoppningsvis känslan av en större lokal och större ljudbild.
2. Jag jämför L och R kanalerna och hittar allt ljud som är samma i dem. Detta är det ljud som skall upplevas komma från mitten antar jag. Detta ljud skickas till centern. Frågan är sedan om L och R enbart skall spela det för dem unika ljudet, eller även lite av centerns ljud? Det får jag testa mig fram med. Speciellt basen vill man väl nyttja alla högtalare för.
"Jag jämför L och R och hittar allt ljud som är samma i dem" - hur göra det rent praktiskt? Hmmm....
2.1. Nisse = L - ((L + R) / 2) Nisse innehåller alltså L utan allt som är gemensamt med R.
2.2. Bosse = R - ((L + R) / 2) Bosse innehåller alltså R utan allt som är gemensamt med L.
2.3. Centern Kalle skall spela enbart det som är gemensamt i L och R. Kalle = (L - Nisse) + (R - Bosse)
Slutgiltig output: L = Nisse (+ 0.5 Kalle kanske för att mjuka till övergång) R = Bosse (+ 0.5 Kalle kanske för att mjuka till övergång) C = Kalle (-0.5 Kalle om det lagts till Kalle i Nisse och Bosse också)
Plus görs med summering i dsp. Minus görs med summering med en invers/fasvänd i dsp. Division med 2 görs med -3dB i dsp. (Är jag rätt ute här??)
3. Eller så skiter man i allt det här i 2.x ovan, och bara låter C spela: (L+R)/2, fast fördröjt minst 2ms efter L och R. Så centern bara tillför lite mjukt av totala ljudet för att jämna ut stereosystemfel, men det kommer fördröjt efter att hörseln lokaliserat varifrån ljudet skall komma i stereomixen och i lägre amplitud, men ändå inom tiden det integreras tonmässigt av hörseln.
Klockan är mycket. Hjärnan är mosig. Ovan innehåller säkert massa feltänk, men det är det som är meningen. Peter skall provoceras av detta och avslöja företagshemligher i affekt! Om inte Peter skjuter detta fullständigt i sank, så vet vi att jag är på rätt spår
Jag har suttit här och tänkt lite på det du skriver här och har själv tidigare snurrat runt i liknande funderingar hur en center i Peters lösning fungerar, men nu har jag kommit fram till att både du och jag har överanalyserat vikten av att sålla fram något som endast ska komma från center-högtalaren.
Det enda man egentligen behöver göra är följande:
1. Både L och R får sina vanliga signaler.
2. Center-kanal C får rakt av en mono-signal, en summering av L och R.
3A. Det optimala är att alla tre högtalare är placerade med exakt samma avstånd till en tänkt sweetspot.
3B. Om punkt 3A inte är fysiskt genomförbart i det specifika lyssningrummet och C befinner sig närmare lyssnaren så bör den kanalen få en så nära på exakt fördröjning i millisekunder beräknat på 1ms = 34,4cm (eller om man vill räkna ut det ännu mer exakt för den miljön man befinner sig i vad gäller temperatur och luftfuktighet).
3C. Man kan leka med större grad av fördröjning i C för att uppnå ett uppfattat större djup i ljudbilden men då uppstår det mer och mer uppenbara fasfel för enskilda ljudelement i mixen. Beroende på vilka frekvenser dessa ljudelement består utav så kan dessa fasfel subjektivt låta både bättre eller sämre beroende på vilka frekvenser som förstärks respektive försvagas, därför är det nog inte önskvärt att på detta sätt fejka en djupare ljudbild.
4. Nivån på C anpassas tills önskad bredd i ljudbilden är uppnådd och ljudbildens bredd minskar succesivt ju starkare ljudnivån är i C. Exempel: Om ljudnivån på lyssningsplats uppfattas som exakt lika starkt från C och L och ett ljudelement i mixen har panorerats 100% till vänster så kommer nu detta ljud att uppfattas komma exakt mittemmelan C och L, förutsatt att man anpassat fördröjningen eller det fysiska avståndet till det samma i punkt 3A eller 3B.
Ovanstående parametrar är enligt mig egentligen de enda man behöver förhålla sig till. Att helt enkelt låta C spela upp en mono-signal av stereomixen och endast anpassa en fördröjning efter fysiska avståndsskillnader mellan de tre kanalerna och anpassa nivån i centerkanalen så kommer nog pusselbitarna falla på plats på det mest naturliga sättet. Att däremot försöka utvinna någon slags modifierad centerkanal ur vänstra och högra kanalen blir nog på sin höjd bara mer eller mindre dåligt. Det räcker alltså med att ett och samma ljud i inspelningen nås örat precis samtidigt från alla tre högtalare (eller två om det är ett fullt panorerat ljud till vänster eller höger).
Med en centerkanal har man nog vunnit en bredare sweetspot, eller kanske snarare så är sweetspoten inte lika tydligt allra bäst på lyssningsplatsen precis i mitten rakt framför centern, men jag vet inte hur Peters ägg ser ut och i vilka riktningar de utstrålar direktljudet.
Jag har svårt att tro att två kanaler skulle kunna bli bättre genom återgivning med tre högtalare som spelar samma frekvenser utplacerade på olika sätt i ett rum. Det vore bättre med tre separata ljudkanaler för tre separata högtalare. Detdär med att omvandla två kanaler till fler genom olika tekniker har fungerat dåligt förr ( läs pro logic )
Tangband skrev:Jag har svårt att tro att två kanaler skulle kunna bli bättre genom återgivning med tre högtalare som spelar samma frekvenser utplacerade på olika sätt i ett rum. Det vore bättre med tre separata ljudkanaler för tre separata högtalare. Detdär med att omvandla två kanaler till fler genom olika tekniker har fungerat dåligt förr ( läs pro logic )
Fast, det är så man gör med användandet av flera basmoduler. Men det kanske inte är det du menar? Vad är det du vill ha sagt?
Är det att dåliga metoder är dåliga? I så fall håller jag med.
Sedan kan jag bara konstatera att missförstånden över hur ljud funkar fullkomligt haglar i några av de trådar som nu är aktuella. Det gäller exempelvis vad direktljud är, precedenceeffekten, vad som händer inom 2 ms, etc. Jag blir alldeles matt då jag läser allt i inläggen. Det blir lätt ett heltidsarbete att försöka reda ut.
Mvh Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
Tangband skrev:Jag har svårt att tro att två kanaler skulle kunna bli bättre genom återgivning med tre högtalare som spelar samma frekvenser utplacerade på olika sätt i ett rum. Det vore bättre med tre separata ljudkanaler för tre separata högtalare. Detdär med att omvandla två kanaler till fler genom olika tekniker har fungerat dåligt förr ( läs pro logic )
Fast, det är så man gör med användandet av flera basmoduler. Men det kanske inte är det du menar? Vad är det du vill ha sagt?
Är det att dåliga metoder är dåliga? I så fall håller jag med.
Sedan kan jag bara konstatera att missförstånden över hur ljud funkar fullkomligt haglar i några av de trådar som nu är aktuella. Det gäller exempelvis vad direktljud är, precedenceeffekten, vad som händer inom 2 ms, etc. Jag blir alldeles matt då jag läser allt i inläggen. Det blir lätt ett heltidsarbete att försöka reda ut.
Mvh Peter
Blir du lika matt av mitt inlägg här ovan, ser du några felaktigheter?
Tangband skrev:Jag har svårt att tro att två kanaler skulle kunna bli bättre genom återgivning med tre högtalare som spelar samma frekvenser utplacerade på olika sätt i ett rum. Det vore bättre med tre separata ljudkanaler för tre separata högtalare. Detdär med att omvandla två kanaler till fler genom olika tekniker har fungerat dåligt förr ( läs pro logic )
Fast, det är så man gör med användandet av flera basmoduler. Men det kanske inte är det du menar? Vad är det du vill ha sagt? .....
Under schröder blir det säkert mindre dåligt, men visst - om du menar en subbas- mono signal som ska spridas ut till 4 separata subwoofers i ett rum för att undertrycka resonanser så blir resultatet dåligt om man lyssnar på musiken, om du frågar mig . Två subwoofers som matas av två separata kanaler är bäst . Vi har provat 1 till 4 subwoofer av high end kvalitet och placerat dessa i rummet efter konstens alla regler under en dag med resultatet att två subbasar , stereokopplade, stående i direkt närhet till topparna, lät bäst. Rummet var dock inte akustikreglerat utan ett helt normalt vardagsrum.
Med det sagt : jag blir gärna överbevisad . Och om tre högtalare med två kanalsmaterial skulle fungera bra så skulle jag applådera . Jag har heller inte testat subwoofers placerade under tak.
Tangband skrev:Jag har svårt att tro att två kanaler skulle kunna bli bättre genom återgivning med tre högtalare som spelar samma frekvenser utplacerade på olika sätt i ett rum. Det vore bättre med tre separata ljudkanaler för tre separata högtalare. Detdär med att omvandla två kanaler till fler genom olika tekniker har fungerat dåligt förr ( läs pro logic )
Fast, det är så man gör med användandet av flera basmoduler. Men det kanske inte är det du menar? Vad är det du vill ha sagt?
Är det att dåliga metoder är dåliga? I så fall håller jag med.
Sedan kan jag bara konstatera att missförstånden över hur ljud funkar fullkomligt haglar i några av de trådar som nu är aktuella. Det gäller exempelvis vad direktljud är, precedenceeffekten, vad som händer inom 2 ms, etc. Jag blir alldeles matt då jag läser allt i inläggen. Det blir lätt ett heltidsarbete att försöka reda ut.
Mvh Peter
Blir du lika matt av mitt inlägg här ovan, ser du några felaktigheter?
Egentligen hela inlägget.
goat76 skrev:
rajapruk skrev:Ok, nu ska jag försöka provocera fram att Peter avslöjar sin centerkanalshemlighet!
Jag tänker göra såhär för att mixa upp 2-kanal till surroundljud att spela i en flerkanalsanläggning med identiska högtalare runtom. Målet är en stor och stabilt centrerad ljudbild, som kan höras från en stor sweetspot, och stereosystemfel reducerade.
1. Jag skickar ut en kopia av ljudet 20ms fördröjt till surroundkanalerna, -3dB kanske. L-kanal går till L surround. R-kanal går till R-surround. Godartade reflexer bakifrån rummet simuleras. Detta ger förhoppningsvis känslan av en större lokal och större ljudbild.
2. Jag jämför L och R kanalerna och hittar allt ljud som är samma i dem. Detta är det ljud som skall upplevas komma från mitten antar jag. Detta ljud skickas till centern. Frågan är sedan om L och R enbart skall spela det för dem unika ljudet, eller även lite av centerns ljud? Det får jag testa mig fram med. Speciellt basen vill man väl nyttja alla högtalare för.
"Jag jämför L och R och hittar allt ljud som är samma i dem" - hur göra det rent praktiskt? Hmmm....
2.1. Nisse = L - ((L + R) / 2) Nisse innehåller alltså L utan allt som är gemensamt med R.
2.2. Bosse = R - ((L + R) / 2) Bosse innehåller alltså R utan allt som är gemensamt med L.
2.3. Centern Kalle skall spela enbart det som är gemensamt i L och R. Kalle = (L - Nisse) + (R - Bosse)
Slutgiltig output: L = Nisse (+ 0.5 Kalle kanske för att mjuka till övergång) R = Bosse (+ 0.5 Kalle kanske för att mjuka till övergång) C = Kalle (-0.5 Kalle om det lagts till Kalle i Nisse och Bosse också)
Plus görs med summering i dsp. Minus görs med summering med en invers/fasvänd i dsp. Division med 2 görs med -3dB i dsp. (Är jag rätt ute här??)
3. Eller så skiter man i allt det här i 2.x ovan, och bara låter C spela: (L+R)/2, fast fördröjt minst 2ms efter L och R. Så centern bara tillför lite mjukt av totala ljudet för att jämna ut stereosystemfel, men det kommer fördröjt efter att hörseln lokaliserat varifrån ljudet skall komma i stereomixen och i lägre amplitud, men ändå inom tiden det integreras tonmässigt av hörseln.
Klockan är mycket. Hjärnan är mosig. Ovan innehåller säkert massa feltänk, men det är det som är meningen. Peter skall provoceras av detta och avslöja företagshemligher i affekt! Om inte Peter skjuter detta fullständigt i sank, så vet vi att jag är på rätt spår
Jag har suttit här och tänkt lite på det du skriver här och har själv tidigare snurrat runt i liknande funderingar hur en center i Peters lösning fungerar, men nu har jag kommit fram till att både du och jag har överanalyserat vikten av att sålla fram något som endast ska komma från center-högtalaren.
Det enda man egentligen behöver göra är följande:
1. Både L och R får sina vanliga signaler.
2. Center-kanal C får rakt av en mono-signal, en summering av L och R.
3A. Det optimala är att alla tre högtalare är placerade med exakt samma avstånd till en tänkt sweetspot.
3B. Om punkt 3A inte är fysiskt genomförbart i det specifika lyssningrummet och C befinner sig närmare lyssnaren så bör den kanalen få en så nära på exakt fördröjning i millisekunder beräknat på 1ms = 34,4cm (eller om man vill räkna ut det ännu mer exakt för den miljön man befinner sig i vad gäller temperatur och luftfuktighet).
3C. Man kan leka med större grad av fördröjning i C för att uppnå ett uppfattat större djup i ljudbilden men då uppstår det mer och mer uppenbara fasfel för enskilda ljudelement i mixen. Beroende på vilka frekvenser dessa ljudelement består utav så kan dessa fasfel subjektivt låta både bättre eller sämre beroende på vilka frekvenser som förstärks respektive försvagas, därför är det nog inte önskvärt att på detta sätt fejka en djupare ljudbild.
4. Nivån på C anpassas tills önskad bredd i ljudbilden är uppnådd och ljudbildens bredd minskar succesivt ju starkare ljudnivån är i C. Exempel: Om ljudnivån på lyssningsplats uppfattas som exakt lika starkt från C och L och ett ljudelement i mixen har panorerats 100% till vänster så kommer nu detta ljud att uppfattas komma exakt mittemmelan C och L, förutsatt att man anpassat fördröjningen eller det fysiska avståndet till det samma i punkt 3A eller 3B.
Ovanstående parametrar är enligt mig egentligen de enda man behöver förhålla sig till. Att helt enkelt låta C spela upp en mono-signal av stereomixen och endast anpassa en fördröjning efter fysiska avståndsskillnader mellan de tre kanalerna och anpassa nivån i centerkanalen så kommer nog pusselbitarna falla på plats på det mest naturliga sättet.
Att däremot försöka utvinna någon slags modifierad centerkanal ur vänstra och högra kanalen blir nog på sin höjd bara mer eller mindre dåligt.
Det räcker alltså med att ett och samma ljud i inspelningen nås örat precis samtidigt från alla tre högtalare (eller två om det är ett fullt panorerat ljud till vänster eller höger).
Med en centerkanal har man nog vunnit en bredare sweetspot, eller kanske snarare så är sweetspoten inte lika tydligt allra bäst på lyssningsplatsen precis i mitten rakt framför centern, men jag vet inte hur Peters ägg ser ut och i vilka riktningar de utstrålar direktljudet.
Det blåmarkerade är, enligt mitt sätt att se på saken, konstigheter. Men det finns ytterligare konstigheter som jag dock för närvarande inte vill upplysa om. Jag nöjer mig med att kommentera din frågeställning gällande direktljud och hur Peters ägg ser ut.
Av det jag sett så är i stort sett samtliga inlägg på faktiskt gällande direktljud med emfas och nästan enkom förknippat med ljudkällan och möjligtvis även med dess utstrålning.
Du frågar nu i vilka riktningar äggen utstrålar direktljudet. Frågan är dock helt felställd och tyder på en total missuppfattning över vad direktljud är för något. Jag skall försöka förklara, åtminstone en liten del av det hela, den del jag anser behövs just nu. Jag vill ogärna vara magistral. Det betyder dock att det måste finnas en ömsesidig kommunikation och att det jag säger skapar eftertanke. Det är i alla fall min förhoppning. Du kan ge dig på att allt jag skriver har föregåtts av extremt mycket eftertanke innan jag skriver.
Låt oss titta på en pulserande sfär. I vilken riktning anser du att direktljudet är? Det är en väldigt retorisk fråga och medvetet ställd så. Jag har nämnt detta i tidigare inlägg. Direktljudet är en vektor. Vilken riktning har denna vektor?
Så här ser det ut om man lägger in ljudtryck. OBS, det är tryck i Pascal och inte absolutbeloppet eller medelvärdet, d v s det är både positiva och negativa tryck i förhållande till atmosfärstrycket.
I denna animering ville man åskådliggöra hur ljudtrycket i SPL minskar med avståndslagen.
Men, nu talar vi riktning och direktljud.
Återigen. I vilken riktning anser du att direktljudet är? från denna sfäriska ljudkälla.
Jag skall ge en annan synvinkel på frågeställningen. En högtalare är monterad på vägg och har denna utstrålning.
I vilken riktning anser du att direktljudet är? från denna väggmonterade ljudkälla? D v s vilken vinkel på vektorn?
Om du svarar på detta så återkommer jag i frågan. OBS! Jag frågar för att sätta igång en tankeverksamhet.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
goat76 skrev: ... Det är inte bara hörseln i sig som selekterar ljud, det är hjärnan och det hela varierar med vad man väljer att koncentrera sig på, den så kallade cocktail-party effekten.
….
Det här tolkar jag som att du separerar hörseln från hjärnan.
Jag vill dock påstå att det man hör är vad hörseln skapar och det är hjärnan med det centrala nervsystemet som är hörseln. Ta bort hjärnan och ingen hörsel återstår.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
Tangband skrev:Jag har svårt att tro att två kanaler skulle kunna bli bättre genom återgivning med tre högtalare som spelar samma frekvenser utplacerade på olika sätt i ett rum. Det vore bättre med tre separata ljudkanaler för tre separata högtalare. Detdär med att omvandla två kanaler till fler genom olika tekniker har fungerat dåligt förr ( läs pro logic )
Fast, det är så man gör med användandet av flera basmoduler. Men det kanske inte är det du menar? Vad är det du vill ha sagt? .....
Under schröder blir det säkert mindre dåligt, men visst - om du menar en subbas- mono signal som ska spridas ut till 4 separata subwoofers i ett rum för att undertrycka resonanser så blir resultatet dåligt om man lyssnar på musiken, om du frågar mig . Två subwoofers som matas av två separata kanaler är bäst . Vi har provat 1 till 4 subwoofer av high end kvalitet och placerat dessa i rummet efter konstens alla regler under en dag med resultatet att två subbasar , stereokopplade, stående i direkt närhet till topparna, lät bäst. Rummet var dock inte akustikreglerat utan ett helt normalt vardagsrum.
Med det sagt : jag blir gärna överbevisad . Och om tre högtalare med två kanalsmaterial skulle fungera bra så skulle jag applådera . Jag har heller inte testat subwoofers placerade under tak.
Alltså, var får du alla tokiga slutsatser och spekulationer ifrån? JAG DISKUTERAR STEREO OCH INTE MONO och har gjort så hela tiden.
Jag vet fortfarande inte vad du vill ha sagt med ditt inlägg som jag kommenterade. Återigen, vad exakt ville du ha sagt?
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
goat76 skrev: ... Det är inte bara hörseln i sig som selekterar ljud, det är hjärnan och det hela varierar med vad man väljer att koncentrera sig på, den så kallade cocktail-party effekten.
….
Det här tolkar jag som att du separerar hörseln från hjärnan.
Jag vill dock påstå att det man hör är vad hörseln skapar och det är hjärnan med det centrala nervsystemet som är hörseln. Ta bort hjärnan och ingen hörsel återstår.
Med vänlig hälsning Peter
Du märker ord, Peter. Jag tror nog alla förstod vad goat76 menade.
Adhoc skrev:Om rummet ska upplevas som större än det är, tror jag det behövs en "period av tystnad" med mycket svaga / ohörbara, dämpade eller bortstyrda reflektioner från objekt nära högtalarna / framför en.
Resultat förhoppningsvis: Mindre av krokigheter i frekvenskurvan vid lyssningsplats för det först uppfattade ljudet. Reflektioner i musiken, från själva inspelningsrummet eller tillagda i studion kan höras och kommer inte dränkas av det egna rummets reflektioner. Efter "tystnaden", reflektioner, helst från sidan, som är starkare än dom under "tystnadsperioden" och tillräckligt starka för att upplevas. Har det gått typ 20 ms till dess, motsvarar det att gångsträckan är knappt 7 m längre än direktljudets, -alltså upplevs då ett större rum för dom flesta. För musik verkar reflektionstiden kunna sträckas ut betydligt jämfört med tal, utan att dom reflektionerna upplevs som eko.
Vi brottas först och främst med 2 olika frekvensfenomen i små rum, dels rumsresonanser som uppstår i tiden, dels destruktiv interferens pga vissa första reflexers inverkan på direktljudet.
Det pratas oftast om ms hit och ms dit och 20 ms. I undersökningar säger man att det är negativt för klangupplevelsen. Varför inte titta på frekvens istället? Säg så här, det är inte önskvärt med destruktiv interferens i området under schröderfrekvensen. I frekvensområdet ovanför betraktas de akustiska ljudvågorna som stokastiska och summation av akustiska ljudvågor sker då enligt medelvärdesprincipen och summan blir en addition så att två i nivå lika starka ljudfält adderas till att bli 3 dB högre ljudnivå.
Under Schröderfrekvensen sker addition enligt superpositionsprincipen och summering blir helt fasberoende. I det området vill man därför försöka undvika summation av akustiska ljudvågor som är nästintill lika starka i nivå. Då kan man analysera saken i frekvensdomän med långt tidsfönster istället för i tidsdomän. Det handlar om samma mynt men respektive sida på myntet.
I inspelningar av akustiska instrument vill man ha de tidiga reflexerna som närstående väggar kan ge och det är runt podiet där musikerna sitter i exempelvis en orkester. Violiner behöver det, eftersom deras ljudutstrålning är hiskeligt frekvensberoende och deras direktljud eller snarast, ljud i en riktning behöver blandas ut med tidiga reflexer från alla möjliga riktningar för att dess utstrålade energi skall vara det som hörs. I en konsertlokal är schröderfrekvensen kring 15 Hz och podiet i sig diffuserar istället för att ge upphov till resonanser eller hörbar färgning pga. interferens.
Men i små rum typ bostadsrum hamnar schröderfrekvensen kring 150 Hz +/- 50 Hz.
Med detta som utgångspunkt kan man räkna och få fram resultat i tidsdomän. Därav, dessa 20 ms som är halva våglängden på 25 Hz. Det är interferens från ungefär 25 Hz till schröderfrekvensen som alla hifinördar slåss mot.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
goat76 skrev: ... Det är inte bara hörseln i sig som selekterar ljud, det är hjärnan och det hela varierar med vad man väljer att koncentrera sig på, den så kallade cocktail-party effekten.
….
Det här tolkar jag som att du separerar hörseln från hjärnan.
Jag vill dock påstå att det man hör är vad hörseln skapar och det är hjärnan med det centrala nervsystemet som är hörseln. Ta bort hjärnan och ingen hörsel återstår.
Med vänlig hälsning Peter
Du märker ord, Peter. Jag tror nog alla förstod vad goat76 menade.
Nej, det gör jag inte. Jag förstår inte och jag vet inte vad goat76 exakt menar. Därför vill jag ta reda på det. Ingen som kan och förstår hörseln skulle uttrycka sig som goat76 gjorde. Det är min bestämda uppfattning. Jag kan tala om att jag talar ur egen erfarenhet. Been there, done that. Men jag ger sällan upp inför min egen kunskapsbrist. Jag tar reda på hur saker ligger till och enda sättet är att lyssna på di lärde och tänka självständigt tills lampan lyser upp helheten. Att jag därefter har en strävan att förmedla detta tycks inte falla somliga på läppen. Det är nämligen så att inte heller någon som tror sig förstå eller veta vad goat76 menar förstår hörseln eller ens det grundläggande hos hörseln, men det gjorde inte heller jag innan jag gjorde en djupdykning i detta ämne. Det är ett feltänk som är representerat i ord av goat76. Inget fel i det, men om man inte vill ta reda på eller hindra andra vari feltänket består så får man leva vidare med det. Det är min utgångspunkt. Därför tar jag upp frågan. Frågeställningen är helt essentiell i sammanhanget. Det ältas samma saker än hit och än dit i mer än 15 år på forumet utan att insikten om ljud och akustik verkar ha höjts. Annars skulle frågorna för länge sedan vara avslutade. Richard, du har ju varit på forumet sedan december år 2006, du borde veta. Jo Tangband, det är nog du som är Richard. Man kan tro att man på forumet helt enkelt inte är intresserade av vad ljud är eller hur hörseln fungerar.
Du får helt enkelt acceptera att jag tar upp sådana saker som jag ser att det finns uppenbara kunskapsluckor i för att försöka belysa och försöka kasta lite ljus över situationen.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
goat76 skrev: ... Det är inte bara hörseln i sig som selekterar ljud, det är hjärnan och det hela varierar med vad man väljer att koncentrera sig på, den så kallade cocktail-party effekten.
….
Det här tolkar jag som att du separerar hörseln från hjärnan.
Jag vill dock påstå att det man hör är vad hörseln skapar och det är hjärnan med det centrala nervsystemet som är hörseln. Ta bort hjärnan och ingen hörsel återstår.
Med vänlig hälsning Peter
Jag uppfattade flera personer inklusive Tangband jämföra hörseln rakt av med hur mikrofoner fungerar och tog avstamp från det du sa att hörseln inte är en statisk företeelse. Jag håller alltså med dig på den punkten och därmed beskrev jag allt det där med cocktail-party effekten vilket visar på att hjärnans förmåga att selektera och koncentrera sig på enskilda ljud är den huvudsakligt största skillnaden från en hjärnlös mikrofon. Du kan omöjligt inte hålla med mig på den punkten.
petersteindl skrev:Fast, det är så man gör med användandet av flera basmoduler. Men det kanske inte är det du menar? Vad är det du vill ha sagt?
Är det att dåliga metoder är dåliga? I så fall håller jag med.
Sedan kan jag bara konstatera att missförstånden över hur ljud funkar fullkomligt haglar i några av de trådar som nu är aktuella. Det gäller exempelvis vad direktljud är, precedenceeffekten, vad som händer inom 2 ms, etc. Jag blir alldeles matt då jag läser allt i inläggen. Det blir lätt ett heltidsarbete att försöka reda ut.
Mvh Peter
Blir du lika matt av mitt inlägg här ovan, ser du några felaktigheter?
Egentligen hela inlägget.
goat76 skrev:
rajapruk skrev:Ok, nu ska jag försöka provocera fram att Peter avslöjar sin centerkanalshemlighet!
Jag tänker göra såhär för att mixa upp 2-kanal till surroundljud att spela i en flerkanalsanläggning med identiska högtalare runtom. Målet är en stor och stabilt centrerad ljudbild, som kan höras från en stor sweetspot, och stereosystemfel reducerade.
1. Jag skickar ut en kopia av ljudet 20ms fördröjt till surroundkanalerna, -3dB kanske. L-kanal går till L surround. R-kanal går till R-surround. Godartade reflexer bakifrån rummet simuleras. Detta ger förhoppningsvis känslan av en större lokal och större ljudbild.
2. Jag jämför L och R kanalerna och hittar allt ljud som är samma i dem. Detta är det ljud som skall upplevas komma från mitten antar jag. Detta ljud skickas till centern. Frågan är sedan om L och R enbart skall spela det för dem unika ljudet, eller även lite av centerns ljud? Det får jag testa mig fram med. Speciellt basen vill man väl nyttja alla högtalare för.
"Jag jämför L och R och hittar allt ljud som är samma i dem" - hur göra det rent praktiskt? Hmmm....
2.1. Nisse = L - ((L + R) / 2) Nisse innehåller alltså L utan allt som är gemensamt med R.
2.2. Bosse = R - ((L + R) / 2) Bosse innehåller alltså R utan allt som är gemensamt med L.
2.3. Centern Kalle skall spela enbart det som är gemensamt i L och R. Kalle = (L - Nisse) + (R - Bosse)
Slutgiltig output: L = Nisse (+ 0.5 Kalle kanske för att mjuka till övergång) R = Bosse (+ 0.5 Kalle kanske för att mjuka till övergång) C = Kalle (-0.5 Kalle om det lagts till Kalle i Nisse och Bosse också)
Plus görs med summering i dsp. Minus görs med summering med en invers/fasvänd i dsp. Division med 2 görs med -3dB i dsp. (Är jag rätt ute här??)
3. Eller så skiter man i allt det här i 2.x ovan, och bara låter C spela: (L+R)/2, fast fördröjt minst 2ms efter L och R. Så centern bara tillför lite mjukt av totala ljudet för att jämna ut stereosystemfel, men det kommer fördröjt efter att hörseln lokaliserat varifrån ljudet skall komma i stereomixen och i lägre amplitud, men ändå inom tiden det integreras tonmässigt av hörseln.
Klockan är mycket. Hjärnan är mosig. Ovan innehåller säkert massa feltänk, men det är det som är meningen. Peter skall provoceras av detta och avslöja företagshemligher i affekt! Om inte Peter skjuter detta fullständigt i sank, så vet vi att jag är på rätt spår
Jag har suttit här och tänkt lite på det du skriver här och har själv tidigare snurrat runt i liknande funderingar hur en center i Peters lösning fungerar, men nu har jag kommit fram till att både du och jag har överanalyserat vikten av att sålla fram något som endast ska komma från center-högtalaren.
Det enda man egentligen behöver göra är följande:
1. Både L och R får sina vanliga signaler.
2. Center-kanal C får rakt av en mono-signal, en summering av L och R.
3A. Det optimala är att alla tre högtalare är placerade med exakt samma avstånd till en tänkt sweetspot.
3B. Om punkt 3A inte är fysiskt genomförbart i det specifika lyssningrummet och C befinner sig närmare lyssnaren så bör den kanalen få en så nära på exakt fördröjning i millisekunder beräknat på 1ms = 34,4cm (eller om man vill räkna ut det ännu mer exakt för den miljön man befinner sig i vad gäller temperatur och luftfuktighet).
3C. Man kan leka med större grad av fördröjning i C för att uppnå ett uppfattat större djup i ljudbilden men då uppstår det mer och mer uppenbara fasfel för enskilda ljudelement i mixen. Beroende på vilka frekvenser dessa ljudelement består utav så kan dessa fasfel subjektivt låta både bättre eller sämre beroende på vilka frekvenser som förstärks respektive försvagas, därför är det nog inte önskvärt att på detta sätt fejka en djupare ljudbild.
4. Nivån på C anpassas tills önskad bredd i ljudbilden är uppnådd och ljudbildens bredd minskar succesivt ju starkare ljudnivån är i C. Exempel: Om ljudnivån på lyssningsplats uppfattas som exakt lika starkt från C och L och ett ljudelement i mixen har panorerats 100% till vänster så kommer nu detta ljud att uppfattas komma exakt mittemmelan C och L, förutsatt att man anpassat fördröjningen eller det fysiska avståndet till det samma i punkt 3A eller 3B.
Ovanstående parametrar är enligt mig egentligen de enda man behöver förhålla sig till. Att helt enkelt låta C spela upp en mono-signal av stereomixen och endast anpassa en fördröjning efter fysiska avståndsskillnader mellan de tre kanalerna och anpassa nivån i centerkanalen så kommer nog pusselbitarna falla på plats på det mest naturliga sättet.
Att däremot försöka utvinna någon slags modifierad centerkanal ur vänstra och högra kanalen blir nog på sin höjd bara mer eller mindre dåligt.
Det räcker alltså med att ett och samma ljud i inspelningen nås örat precis samtidigt från alla tre högtalare (eller två om det är ett fullt panorerat ljud till vänster eller höger).
Med en centerkanal har man nog vunnit en bredare sweetspot, eller kanske snarare så är sweetspoten inte lika tydligt allra bäst på lyssningsplatsen precis i mitten rakt framför centern, men jag vet inte hur Peters ägg ser ut och i vilka riktningar de utstrålar direktljudet.
Det blåmarkerade är, enligt mitt sätt att se på saken, konstigheter. Men det finns ytterligare konstigheter som jag dock för närvarande inte vill upplysa om. Jag nöjer mig med att kommentera din frågeställning gällande direktljud och hur Peters ägg ser ut.
Av det jag sett så är i stort sett samtliga inlägg på faktiskt gällande direktljud med emfas och nästan enkom förknippat med ljudkällan och möjligtvis även med dess utstrålning.
Du frågar nu i vilka riktningar äggen utstrålar direktljudet. Frågan är dock helt felställd och tyder på en total missuppfattning över vad direktljud är för något. Jag skall försöka förklara, åtminstone en liten del av det hela, den del jag anser behövs just nu. Jag vill ogärna vara magistral. Det betyder dock att det måste finnas en ömsesidig kommunikation och att det jag säger skapar eftertanke. Det är i alla fall min förhoppning. Du kan ge dig på att allt jag skriver har föregåtts av extremt mycket eftertanke innan jag skriver.
Låt oss titta på en pulserande sfär. [ Bild ] I vilken riktning anser du att direktljudet är? Det är en väldigt retorisk fråga och medvetet ställd så. Jag har nämnt detta i tidigare inlägg. Direktljudet är en vektor. Vilken riktning har denna vektor?
Så här ser det ut om man lägger in ljudtryck. OBS, det är tryck i Pascal och inte absolutbeloppet eller medelvärdet, d v s det är både positiva och negativa tryck i förhållande till atmosfärstrycket.
[ Bild ] I denna animering ville man åskådliggöra hur ljudtrycket i SPL minskar med avståndslagen.
Men, nu talar vi riktning och direktljud.
Återigen. I vilken riktning anser du att direktljudet är? från denna sfäriska ljudkälla.
Jag skall ge en annan synvinkel på frågeställningen. En högtalare är monterad på vägg och har denna utstrålning.
I vilken riktning anser du att direktljudet är? från denna väggmonterade ljudkälla? D v s vilken vinkel på vektorn?
Om du svarar på detta så återkommer jag i frågan. OBS! Jag frågar för att sätta igång en tankeverksamhet.
Med vänlig hälsning Peter
Vadå egentligen hela inlägget?
Flertalet av de punkter jag skrev i inlägget vet jag mycket väl att de fungerar precis så som jag beskrev efter otaliga timmar av panoreringar, lekande med diverse fördröjningar och vad som sker när man olika fasförskjutningar i dessa fördröjningar.
Det jag håller helt öppet för är att jag inte fullt ut vet vilken typ av process du använder dig av i din center-lösning. Delar du månne stereosignalen och fasvänder du ena kanalen för att utvinna det som inte ska ingå i centern, för att sedan på något vis fasvända den ytterligare en gång till för att få fram endast det som ska ingå i centerns signal på något vis, eller hur går det till? För du verkar som sagt invända mot precis allt jag skrev?
Jag tror nog du kan ge oss lite "ytlig" information om din lösning utan att vara rädd för att sprida dina viktigaste företags-hemligheter.
Med direktljud menar jag fullskaligt direktljud med huvudsak högtalarens membran riktat ganska precis rakt mot lyssnaren eller iallafall en huvudsaklig del av denna. Jag förstår mycket väl att man utsätts för ett visst direktljud från i stort sett vilken vinkel som helst. Förstår du nu vad jag menar?
Jag vet inte hur dina ägg ser ut så jag vet inte åt vilka håll membranen pekar åt när de är placerade på en sidovägg.
P.S. Jag ifrågasätter inte din lösning, jag försöker liksom andra här bara bli mer insatt i hur din center fungerar.
petersteindl skrev: Det här tolkar jag som att du separerar hörseln från hjärnan.
Jag vill dock påstå att det man hör är vad hörseln skapar och det är hjärnan med det centrala nervsystemet som är hörseln. Ta bort hjärnan och ingen hörsel återstår.
Med vänlig hälsning Peter
Du märker ord, Peter. Jag tror nog alla förstod vad goat76 menade.
Nej, det gör jag inte. Jag förstår inte och jag vet inte vad goat76 exakt menar. Därför vill jag ta reda på det. Ingen som kan och förstår hörseln skulle uttrycka sig som goat76 gjorde. Det är min bestämda uppfattning. Jag kan tala om att jag talar ur egen erfarenhet. Been there, done that. Men jag ger sällan upp inför min egen kunskapsbrist. Jag tar reda på hur saker ligger till och enda sättet är att lyssna på di lärde och tänka självständigt tills lampan lyser upp helheten. Att jag därefter har en strävan att förmedla detta tycks inte falla somliga på läppen. Det är nämligen så att inte heller någon som tror sig förstå eller veta vad goat76 menar förstår hörseln eller ens det grundläggande hos hörseln, men det gjorde inte heller jag innan jag gjorde en djupdykning i detta ämne. Det är ett feltänk som är representerat i ord av goat76. Inget fel i det, men om man inte vill ta reda på eller hindra andra vari feltänket består så får man leva vidare med det. Det är min utgångspunkt. Därför tar jag upp frågan. Frågeställningen är helt essentiell i sammanhanget. Det ältas samma saker än hit och än dit i mer än 15 år på forumet utan att insikten om ljud och akustik verkar ha höjts. Annars skulle frågorna för länge sedan vara avslutade. Richard, du har ju varit på forumet sedan december år 2006, du borde veta. Jo Tangband, det är nog du som är Richard. Man kan tro att man på forumet helt enkelt inte är intresserade av vad ljud är eller hur hörseln fungerar.
Du får helt enkelt acceptera att jag tar upp sådana saker som jag ser att det finns uppenbara kunskapsluckor i för att försöka belysa och försöka kasta lite ljus över situationen.
Med vänlig hälsning Peter
Peter, jag vet inte om du just idag är på dåligt humör och att det påverkar din läsförståelse negativt?
Det jag skriver är att en mikrofon bara tar med allt ljud med hull och hår och kan inte selektivt välja att koncentrera sig på ett specifikt ljud i allt sorl och fördjupa sig i det så som våran hörsel med hjälp av hjärnan och sinnet kan. Menar du att du inte håller med om det?
Isåfall får du gärna fördjupa dig i det, alternativt erkänna att du misstolkat det jag skrivit.
petersteindl skrev:Jag vill exemplifiera en sak för flera på faktiskt, dock speciellt för JM och för tangband. Det gäller direktljudet från Bremen 3D8 även kallad äggen. Hur ser direktljudet i diskanten ut? Det spekuleras ju en del. Låt oss se hur en sådan konfiguration kan te sig.
Med vänlig hälsning Peter
Mycket intressanta mätningar. Direktljudet ser mycket bra ut på dina mätningar map frekvens i mätpositionen. Saknar mätningar i lyssningspositionen vid övrigt identiska mätningarna med äggen på vägg med allt inkopplat även basar. Hur ser mätningarna ut efter ca 0-1, 1-2, 2 -8, 8-15, 15- 20 och 20-30 ms. Rummet måste vara exakt beskrivet för att förstå resultaten.
JM
Senior neurofoskanre - KI. Annihilerar antimateria. Beauty is in the Brain of the Listener. We are standing on the shoulders of giants. "Kill your Darlings" => Scientific Progress.
goat76 skrev:............. Med direktljud menar jag fullskaligt direktljud med huvudsak högtalarens membran riktat ganska precis rakt mot lyssnaren eller iallafall en huvudsaklig del av denna. Jag förstår mycket väl att man utsätts för ett visst direktljud från i stort sett vilken vinkel som helst. Förstår du nu vad jag menar? ...........
Det viktiga skriver du i andra meningen jag citerat.
Direktljudet är det ljud som först når lyssnaren eller mikrofonen från ljudkällan förutsatt att ljudkällan inte är skymd*. Det har alltså inte så mycket att göra med hur ljudkällan uppför sig. Sedan kan man lägga till viss andel reflekterat ljud vid konstruktion av högtalare sålänge hörseln uppfattar det som direktljud. Av rent fysikaliska skäl kommer dessa reflexer att vara väldigt "snabba"
*Det finns både i naturen och tillverkade ljudkällor där ljudledning sker . Det behöver inte vara ett membran som är ljudkällan utan t.ex ett veckat horns hornöppning bör betraktas som ljudkälla.
goat76 skrev:............. Med direktljud menar jag fullskaligt direktljud med huvudsak högtalarens membran riktat ganska precis rakt mot lyssnaren eller iallafall en huvudsaklig del av denna. Jag förstår mycket väl att man utsätts för ett visst direktljud från i stort sett vilken vinkel som helst. Förstår du nu vad jag menar? ...........
Det viktiga skriver du i andra meningen jag citerat.
Direktljudet är det ljud som först når lyssnaren eller mikrofonen från ljudkällan förutsatt att ljudkällan inte är skymd*. Det har alltså inte så mycket att göra med hur ljudkällan uppför sig. Sedan kan man lägga till viss andel reflekterat ljud vid konstruktion av högtalare sålänge hörseln uppfattar det som direktljud. Av rent fysikaliska skäl kommer dessa reflexer att vara väldigt "snabba"
*Det finns både i naturen och tillverkade ljudkällor där ljudledning sker . Det behöver inte vara ett membran som är ljudkällan utan t.ex ett veckat horns hornöppning bör betraktas som ljudkälla.
Jag förstår det där och att jag skrev det slarvigt. Men visst är du med på att man nås av mer mängd direktljud rakt framifrån en normal högtalarkonstruktion i.o.m att även de absolut högsta frekvenserna når lyssnaren i högre grad.
Kanske är det mer spridning i de högre frekvenserna än vad jag förstått, finns det någon visualisering av olika frekvensers spridning från en normal genomsnittlig diskant?
goat76 skrev:............. Med direktljud menar jag fullskaligt direktljud med huvudsak högtalarens membran riktat ganska precis rakt mot lyssnaren eller iallafall en huvudsaklig del av denna. Jag förstår mycket väl att man utsätts för ett visst direktljud från i stort sett vilken vinkel som helst. Förstår du nu vad jag menar? ...........
Det viktiga skriver du i andra meningen jag citerat.
Direktljudet är det ljud som först når lyssnaren eller mikrofonen från ljudkällan förutsatt att ljudkällan inte är skymd*. Det har alltså inte så mycket att göra med hur ljudkällan uppför sig. Sedan kan man lägga till viss andel reflekterat ljud vid konstruktion av högtalare sålänge hörseln uppfattar det som direktljud. Av rent fysikaliska skäl kommer dessa reflexer att vara väldigt "snabba"
*Det finns både i naturen och tillverkade ljudkällor där ljudledning sker . Det behöver inte vara ett membran som är ljudkällan utan t.ex ett veckat horns hornöppning bör betraktas som ljudkälla.
Bra där jansch. Jag återkommer med mina svar i frågor. Har inte tid för tillfället.
Kortfattat. Det är i princip enkom mottagaren som bestämmer direktljudet. Det betyder att om mottagaren befinner sig bakom högtalaren så är direktljudet det direkta ljud som når mottagaren bakom högtalaren, och inget annat. I det fallet så inkluderas enkom mottagaren.
Det betyder att högtalaren inte ens är med för att beskriva vektorns riktning!! Högtalarens punkt är alltid punkten (0,0,0) som också kallas Origo.
Jo, ni läser rätt. Direktljudet har en riktning. Därmed är det en vektor. Det är enkom denna vektor vi är intresserade av om vi nu skall dissekera vad som händer under 1 ms och försöka applicera detta på att uppnå en slags subjektiv ljudbild i ett fantomprojicerat stereofoniskt system.
Jag har tidigare skrivit att i vektoranalysen beskriver man vektorer i en rymd med ett koordinatsystem. Denna rymd kallas för det Euklidiska rummet. Koordinatsystemet är det vanliga kartesiska koordinatsystemet som beskrivs med (x,y,z). Riktningen av denna vektor kan därmed beskrivas av en godtycklig punkt, exempelvis (x1,y1,z1). Man använder normerade system med basvektorer. I ett sådant system väljer man Origo i koordinatsystemet som man utgår ifrån. Origo lägger man i det här fallet i högtalarens position. Koordinaten är då enkom mottagarens koordinat. T.ex. om jag anger koordinaten i ett tvådimensionellt system som (1/√2,1/√2) så är vinkeln entydigt definierad och det har ingen betydelse var högtalaren står eller hur högtalaren roteras. Vinkeln i detta fall är 45 grader för den som glömt gamla mattekurser. Man förlägger Origo i högtalaren.
Så, direktljudets riktning kan beskrivas med en och endast en punkt med 3 koordinater i ett tredimensionellt rum och denna punkt är i detta fall mottagarens punkt. Ljudalstraren är i Origo.
Jag tror de flesta har svårt att greppa detta. Det tarvar att man dammar av vektoranalysen, vilket man måste, om man pratar riktning.
Befinner man sig bakom en vanlig högtalare så går ljudvågor runt högtalarhöljet på grund av fenomenet diffraktion. Finns det kanter så finns det fassprång. Är högtalaren rund så blir det kontinuerlig diffraktion. Oavsett, så är direktljudet till en mottagare bakom en högtalare det ljud som når mottagaren utan reflektion av ljudvågor som innebär reflexer från annan riktning än direktljudets. Däremot ingår reflexer som är parallella med direktljudet.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
goat76 skrev:............. Med direktljud menar jag fullskaligt direktljud med huvudsak högtalarens membran riktat ganska precis rakt mot lyssnaren eller iallafall en huvudsaklig del av denna. Jag förstår mycket väl att man utsätts för ett visst direktljud från i stort sett vilken vinkel som helst. Förstår du nu vad jag menar? ...........
Det viktiga skriver du i andra meningen jag citerat.
Direktljudet är det ljud som först når lyssnaren eller mikrofonen från ljudkällan förutsatt att ljudkällan inte är skymd*. Det har alltså inte så mycket att göra med hur ljudkällan uppför sig. Sedan kan man lägga till viss andel reflekterat ljud vid konstruktion av högtalare sålänge hörseln uppfattar det som direktljud. Av rent fysikaliska skäl kommer dessa reflexer att vara väldigt "snabba"
*Det finns både i naturen och tillverkade ljudkällor där ljudledning sker . Det behöver inte vara ett membran som är ljudkällan utan t.ex ett veckat horns hornöppning bör betraktas som ljudkälla.
Jag förstår det där och att jag skrev det slarvigt. Men visst är du med på att man nås av mer mängd direktljud rakt framifrån en normal högtalarkonstruktion i.o.m att även de absolut högsta frekvenserna når lyssnaren i högre grad.
Kanske är det mer spridning i de högre frekvenserna än vad jag förstått, finns det någon visualisering av olika frekvensers spridning från en normal genomsnittlig diskant?
Du har fel. Du kan vrida högtalaren precis hur du vill. Det påverkar inte direktljudets riktning. Direktljudet är i sig en definierad riktning från ljudalstrare till ljudmottagare.
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
Håller vi på att skapa en diskussion ur ingenting?
Jag har förstått att det var slarvigt skrivet av mig, nu får ni möta mig lite här och försöka förstå det jag ville ha sagt för nu är vi återigen i nomenklatur-träsket och rotar istället för att ni bara kan rätta mig med att säga: ”Kanske menar du så här...”
goat76 skrev:Håller vi på att skapa en diskussion ur ingenting?
Jag har förstått att det var slarvigt skrivet av mig, nu får ni möta mig lite här och försöka förstå det jag ville ha sagt för nu är vi återigen i nomenklatur-träsket och rotar istället för att ni bara kan rätta mig med att säga: ”Kanske menar du så här...”
JAG TROR att du "ser" det helt korrekt Goat76! Det är bara så vanligt att diskutera direktljud utifrån ett högtalarperspektiv vilket blir lite "halvtaskigt". Det är inte alls komplext om man utgår ifrån att direktljud är DIREKTLJUD oavsett hur ljudkällan utstrålar.
Man kan faktiskt tänka sig situationer där det inte finns direktljud och då inser man konsekvensen av när direktljud saknas. Tänk dej en stor och hög mur mellan dej och en person som talar/sjunger bakom muren. Beroende vad du står längs muren kommer du uppfatta att den som talar/sjunger står närmare höger eller vänster...eller en bit upp i luften längs murens krön.
Din logik/insikt beslutar sig för att personen som talar/sjunger inte svävar längs murens kant ( det rationella beslutet som hörseln/hjärnan tar instinktivt). Sannolikt inser hjärnan att direktljud saknas = riktningen blir odefinierad. Alltså..... inget direktljud = ingen riktning. Väldigt förenklad beskivning men i verkligheten oerhört påtaglig.
HUR hjärnan/hörseln inser att direktljud saknas vet jag inte. Kanske beoende på mina tillkortakommande avseende kompetens eller så är vår hörsel så komplex i toknng av ljud att vi inte har alla "svar"
goat76 skrev:Jag förstår det där och att jag skrev det slarvigt. Men visst är du med på att man nås av mer mängd direktljud rakt framifrån en normal högtalarkonstruktion i.o.m att även de absolut högsta frekvenserna når lyssnaren i högre grad.
Kanske är det mer spridning i de högre frekvenserna än vad jag förstått, finns det någon visualisering av olika frekvensers spridning från en normal genomsnittlig diskant?
Jag tycker inte du skriver slarvigt, du har nog ganska bra koll på vad som är direktljud men du är inte van att diskutera detta ämne - därför det lätt att misstolka. Du nämner spridning i diskanten......
Först och främst - vår hörsel är beroende av direktljud för att definiera i vilken riktning "fienden" finns. Vi måste kunna definiera var rovdjuret är som vill äta upp oss......tror hjärnan. Att vi tycker det är kul med att stereofoni som kan skapa en 2- dimentionell känsa är kul men så underordnat i verkligheten. (när du blir skrämd av ett ljud är riktningen det primära och du drar ihop/mobiliserar kroppen för försvar eller för att fly.)
Riktningsverkan (som förutsätter direktljud) är som bäst i precensområdet, sådär 2 till 5 kHz och beroende av bl.a.örats utformning. I ett normalt bostadsrum krävs dock också "första vågfront" annars drunkar riktningsverkan i alla reflektioner.
Det där med direktljud är inte så självklart. Är direktljudet lika starkt som ett annat ljud identiskt ljud, framför nära lyssnaren, vilket anländer till örat samtidigt - uppfattas bara ett ljud vilket lokaliseras mitt emellan ljudkällorna. Typ att monoljud hamnar mittemellan stereohögtalarna. Detta gör att direktljudet från ett av Peters ägg för låga frekvenser hamnar mittemellan högtalarelementen medans vid högre frekvenser upplevs allmer komma från den närmaste högtalaren pga ökande beaming. Skugghögtalarens bidrag till direktljudet i de högsta frekvenserna minskar med ökande frekvens. Detta är bara av akademiskt intresse och påverkar i praktiken inte ljudupplevelsen.
Ett direkt klickljud följs av ett identiskt (map frekvens/ljudstyrka) klickljud efter 2 ms uppfattas som 2 olika ljud med olika lokalisation.
Ett prominent direkt talljud följt av ett identiskt talljud efter 20 ms men med 6 db dämpning uppfattas som bara ett ljud lokaliserat till det första ljudets position. Talet upplevs av en nornalhörande ungdom som extra klart spatialt medans en nybliven pensionär med normal åldersrelaterad hörselnedsättning upplever talet som något otydligt jämfört med samma tal på ett öppet fält. Hörselnedsättningen gör att reflexerna partiellt maskerar direktljudet.
Det intressanta är när reflexer av musik och tal likt i våra lyssningsrum kommer mellan 1-10 ms efter direktljudet. Prominenta reflexer maskerar partiellt i varierande grad direktljudet även hos individer utan hörselnedsättning. Det är här perceptionen avviker från mikrofonen registrering och varierar med åldern och olika hörselproblem trots normala audiogram. Hyperakusi har många utan att förstå att de har skadan och att det påverkar perceptionen. Många musiker och audiofiler har hyperakusi.
JM
Senast redigerad av JM 2019-12-03 00:50, redigerad totalt 5 gånger.
Senior neurofoskanre - KI. Annihilerar antimateria. Beauty is in the Brain of the Listener. We are standing on the shoulders of giants. "Kill your Darlings" => Scientific Progress.
goat76 skrev:Jag förstår det där och att jag skrev det slarvigt. Men visst är du med på att man nås av mer mängd direktljud rakt framifrån en normal högtalarkonstruktion i.o.m att även de absolut högsta frekvenserna når lyssnaren i högre grad.
Kanske är det mer spridning i de högre frekvenserna än vad jag förstått, finns det någon visualisering av olika frekvensers spridning från en normal genomsnittlig diskant?
Jag tycker inte du skriver slarvigt, du har nog ganska bra koll på vad som är direktljud men du är inte van att diskutera detta ämne - därför det lätt att misstolka. Du nämner spridning i diskanten......
Först och främst - vår hörsel är beroende av direktljud för att definiera i vilken riktning "fienden" finns. Vi måste kunna definiera var rovdjuret är som vill äta upp oss......tror hjärnan. Att vi tycker det är kul med att stereofoni som kan skapa en 2- dimentionell känsa är kul men så underordnat i verkligheten. (när du blir skrämd av ett ljud är riktningen det primära och du drar ihop/mobiliserar kroppen för försvar eller för att fly.)
Riktningsverkan (som förutsätter direktljud) är som bäst i precensområdet, sådär 2 till 5 kHz och beroende av bl.a.örats utformning. I ett normalt bostadsrum krävs dock också "första vågfront" annars drunkar riktningsverkan i alla reflektioner.
Tack jansch för informationen! Jag kan då gladeligen erkänna att jag har missförstått det hela och faktiskt trott att riktverkan hade med själva spridningen av ljud att göra, det är alltså riktverkan jag har försökt prata om.
Så den är alltså starkast mellan 2 till 5kHz och blir mindre tydlig uppåt succesivt efter det. När man tänker efter så visar helt alldagliga ljudupplevelser att det stämmer, det är lätt att lokalisera riktningen av röster, hundskall och liknande med enbart hörseln medans en brandvarnare som börjar pipa inte alls är lika lätt att lokalisera utan titta efter vart i taket den verkligen befinner sig.
JM skrev:Det där med direktljud är inte så självklart. Är direktljudet lika starkt som ett annat ljud identiskt ljud, framför nära lyssnaren, vilket anländer till örat samtidigt - uppfattas bara ett ljud vilket lokaliseras mitt emellan ljudkällorna. Typ att monoljud hamnar mittemellan stereohögtalarna.
Det var det där jag tog upp lite tidigare i tråden.
Ifall en center-högtalare ska användas för att hjälpa till att skapa en bredare sweetspot, och om denna spelar upp en mono-summering av vänster och höger kanal så behöver man ha ett betydligt större mellanrum mellan front-högtalarna just p.g.a. att de enskilda identiska ljuden i mixen då kommer dras innåt mot mitten. Ifall center-högtalaren spelar lika starkt som fronthögtalarna så kommer de enskilda ljuden i mixen att uppfattas komma allt från mittemellan exempelvis L och C till ännu närmare C för de ljudelement som i mixen inte är fullt panorerade till vänster. Man får då alltså halverad bredd av ljudbilden jämfört med det fysiska avståndet mellan frontarna och har därmed inte vunnit någonting alls vad gäller sweetspot. Om man sänker ljudet i C med -3dB så har man återvunnit bredden i ljudbilden till 75% av det fysiska avståndet mellan högtalarna.
Man kan allså konstatera att man måste ha väldigt brett mellan L och R om man vill bredda sweetspot med hjälp av C, såpass brett att man egentligen snarare förstorar hela ljudbilden vilket då medför en bredare sweetspot.
Med den ökade bredden så lockas man kanske att lägga in ytterligare fördröjning i C (utöver den fördröjning man eventuellt redan lagt för att matcha C med det fysiska avståndet från lyssningsplats från L och R) för att vinna ett uppfattat ännu större djup i ljudbilden, men om C är rak och enkel summering av L och R så kommer detta i så fall skapa fasfel för direktljudet. Dessa fasfel kommer antingen förstärka vissa frekvenser och försvaga andra beroende på hur många millisekunder som används för fördröjningen. Detta kommer därmed variera med program-materialet.
Så då återstår frågan: Går det på ett trovärdigt sätt att utvinna de ljud som ska befinna sig i en tänkt center-kanal från ett tvåkanal-spår, och sedan filtrera bort det från vänster och höger kanal? Isåfall behöver man inte oroa sig för varken minskad bredd i ljudbilden eller fasfel, och kan då (nästan) fritt bestämma bredd och djup i ljudbilden och därmed även vinna en bredare sweetspot.
Goat76, likställer du "bred ljudbild" med "stor sweetspot"? Att det är samma sak? Eller att det hänger ihop på något sätt? För mig är det två helt olika saker. Aldrig tänkt att det skulle höra ihop liksom. Men det kanske det gör?
Det roliga är att jag har absolut inga planer på att skaffa en centerhögtalare, eller att konkret försöka implementera någon sådan uppmixningsalgoritm. Jag bara tycker det är jäkligt intressant, rent teoretiskt Att skaffa surround-högtalare däremot kommer jag nog göra framöver, och då kommer jag prova det där att försöka skapa ett större upplevt rum med lite fejkade reflexer bakifrån.
Men nu har ju Peter givit oss sitt tysta medgivande att jag var på helt rätt spår, hehehe
Eller så har han bara inte hunnit ta fram storsågen ännu...
Bremenägg som surrounds hade varit lite av en dröm faktiskt för mig, men jag har inte den budgeten. Eller Peter kanske ger mig ett par för att få tyst på mig??
Senast redigerad av rajapruk 2019-12-03 02:27, redigerad totalt 1 gång.
rajapruk skrev:Goat76, likställer du "bred ljudbild" med "stor sweetspot"? Att det är samma sak? Eller att det hänger ihop på något sätt? För mig är det två helt olika saker. Aldrig tänkt att det skulle höra ihop liksom. Men det kanske det gör?
Oftast är det motsatsen. Oftast innebär en bred upplevd ljudbild då man befinner sig i sweetspot att sweetspot är liten. Bredden på ljudbilden har till stor del att göra med lyssningsvinkeln. Lyssningsvinkeln ökar då man förflyttar sig närmare högtalarnas axel. Högtalarnas axel är den linje som sammanbinder höger högtalare med vänster högtalare.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
rajapruk skrev:Goat76, likställer du "bred ljudbild" med "stor sweetspot"? Att det är samma sak? Eller att det hänger ihop på något sätt? För mig är det två helt olika saker. Aldrig tänkt att det skulle höra ihop liksom. Men det kanske det gör?
Jag har inte sagt att det hör ihop, men beroende på vilken lösning man väljer med hjälp av en center-högtalare så har man möjligheten att skapa en större sweetspot. Det är väl det som är tanken med en center i detta fall och beroende hur den lösningen ser ut/är utformad så har man möjligtvis även möjligheten att skapa en större ljudbild, vilket då på det viset även skapar en större sweetspot.
Det är väl även beroende på vilka högtalare som används för ändamålet. Stort är större!
rajapruk skrev:Det roliga är att jag har absolut inga planer på att skaffa en centerhögtalare, eller att konkret försöka implementera någon sådan uppmixningsalgoritm. Jag bara tycker det är jäkligt intressant, rent teoretiskt Att skaffa surround-högtalare däremot kommer jag nog göra framöver, och då kommer jag prova det där att försöka skapa ett större upplevt rum med lite fejkade reflexer bakifrån.
Men nu har ju Peter givit oss sitt tysta medgivande att jag var på helt rätt spår, hehehe
Eller så har han bara inte hunnit ta fram storsågen ännu...
Bremenägg som surrounds hade varit lite av en dröm faktiskt för mig, men jag har inte den budgeten. Eller Peter kanske ger mig ett par för att få tyst på mig??
De verkar fina, du får väl hoppas!
Jag tycker också det är intressant så vi får väl hoppas att Peter spiller bönorna.
goat76 skrev:Håller vi på att skapa en diskussion ur ingenting?
Jag har förstått att det var slarvigt skrivet av mig, nu får ni möta mig lite här och försöka förstå det jag ville ha sagt för nu är vi återigen i nomenklatur-träsket och rotar istället för att ni bara kan rätta mig med att säga: ”Kanske menar du så här...”
Sorry Goat, jag tänker inte möta dig. Jag vet att det jag säger är korrekt. Jag vill inte ens spekulera i vad du kanske måhända kan mena. Varför skulle jag göra det? Du får nog ta och bemöda dig att söka förstå orsak-verkan-sambanden så att en meningsfull diskussion kan formas.
Jag kan sträcka mig så långt att säga att du förväxlar och/eller blandar riktning/lokalisation med klang/timbre. Men de gör de flesta i tråden. Du är inte ensam därvidlag. Allt som dillas om 2 ms eller mindre har enkom med riktning att göra. Att blanda ihop detta med klang är gallimatias.
Du tror jag vill skapa en diskussion ur ingenting. Du tror helt fel. Det som du tror skulle vara "ingenting" är i själva verket nämligen "allting". Du får själv dricka den bägaren.
Dessutom undrar jag varför du anser att andra människor måste möta dig?? Varför då? Vad tillsätter du dig själv för betydelse egentligen? Varje människa får bemöda sig att söka förstå fysiken och att krypa fram även om man behöver ge upp sina gamla falsarier till idéer. Varför måste de som har korrekt svar möta just dig? Borde det inte vara tvärtom?!
Anser man att man har båda fötterna på sanningens bergfasta grund så skall man inte ge upp detta för att frångå det korrekta. Jag står bergfast kvar.
Tyvärr har jag inte tid att kontinuerligt skriva, ens om jag ville. Så det får gå några inlägg emellan även fast det däremellan skrivs en hel del missuppfattningar.
Men, av dina senaste svar i tråden att döma så ser det ut som du kanske måhända har förstått att den raka linjen mellan ljudkälla och ljudmottagare utgör den linje varmed vektorn som symboliserar direktljudets riktning definieras.
Detta är oberoende av ljudkällans riktningskarakteristik eller ljudmottagarens rotation kring sin egen axel. Här är en bild.
direktljud.jpg (67 KiB) Visad 6179 gånger
Här kan du se vektorn som utgör direktljudets vektor. Denna vektors riktning är oberoende av högtalarens spridning och riktningskarakteristik och oberoende av högtalarens rotation kring sin axel.
Vad mer är att vektorns riktning är oberoende av om din näsa pekar mot högtalaren eller bort från högtalaren d v s du kan vrida huvudet hur du vill eller sitta uppochner.
Du kan också lägga in vilket koordinatsystem du vill och förskjuta koordinatsystemet hur du vill och rotera koordinatsystemet hur du vill. Inget kommer att förändra vektorns riktning.
Vad representerar vektorn? Den representerar gradienten på trycket mellan punkt A och punkt B där trycket varierar i rummet hos en propagerande akustisk ljudvåg, där A är ljudkällan och B är ljudmottagaren. Det är en rumsderivata och inte en tidsderivata. Tidigare har jag berört ljudkällan A. Nu tänker jag beröra ljudmottagaren B.
I bilden anser B att ljudkällan A är rakt till vänster d v s 90 grader om näsans riktning anses vara noll grader och ljud som kommer in från höger har då riktningen 270 grader eller -90 grader. Vrider B huvudet 90 grader så att näsan pekar mot högtalaren så anser B att ljudkällan är placerad i riktningen 0 grader, men vektorns riktning är fortfarande identiskt lika.
Vad får detta för konsekvens? Jo, i fallet på bild är ITD Interaural time Difference på direktljudet ungefär = 0,65 ms, och i fallet då näsan pekar mot högtalaren är ITD Interaural Time Difference = noll ms, men direktljudsvektorn är fortfarande helt intakt och oförändrad. Så, den där millisekunden eller 2 det dillar om gällande direktljudet är en total missuppfattning av direktljudets innersta väsen. I princip det mesta som skrivs på detta forum om precedence är också helt nonsens.
Jag har lagt upp denna bild många gånger och gör det igen.
Lateralization_of_auditory_event_blauert.jpg (386.19 KiB) Visad 6179 gånger
Här har man klart definierat området för lokalisation som kallas summing localization. Både x och y-axel har linjär skala. Därför blir kurvan rak från noll till 1 ms. Görs y-axeln logaritmisk så blir kurvan istället exponentiell. Detta är inom den första millisekunden. I den här kurvan mellan 0 till 1 ms så kan man rotera huvudet 360 grader och få lika resultat under förutsättning att man korrigerar amplitud mellan öronen då man roterar huvudet. Det är till och med så att lokalisationsförmågan ökar då man vrider huvudet lite medans man lyssnar.
Byter man ut 2 högtalare mot en enda högtalare eller en godtycklig ljudkälla så är resultatet lika d v s du kan rotera ditt huvud och fortfarande peka mot ljudkällan medans du vrider huvudet. Ditt pekande kommer dock vara konstant mot ljudkällan, men din verbala beskrivning av ljudkällans placering kommer variera beroende på ditt huvuds rotation. I ett fall säger du rakt framifrån i ett annat fall rakt bakifrån och i ett tredje fall rakt från höger osv. Det beror på att ditt eget koordinatsystem gällande ljudets perception/sensation ändras med ditt huvuds rotation där noll grader alltid är näsans riktning. MEN DIREKTLJUDETS VEKTOR ÄR ÄNDOCK HELT OFÖRÄNDRAD!! I klartext, beroende på ditt huvuds rotationsläge då du roterar huvudet så kommer delay tiden eller snarast differenstiden mellan öronen ITD att variera utan att direktljudets vektor ändras. Det beror på ditt eget koordinatsystems förankring och rotation kring sin axel. Dessutom är det så att din klangupplevelse av ljudkällan i princip kommer vara rätt så lika oberoende av ditt huvuds rotation inom vissa gränser. Men den spektrala tonkurvan kommer variera med kanske 20 dB på respektive trumhinna då du vrider huvudet lite. Det är nämligen så att den spektrala tonkurvan på respektive trumhinna också motsvarar en given riktning och inte en klangfärg hos ljudkällan. Ljudkällan förändras inte och inte dess läge. Klangen förändras minimalt. Men den spektrala tonkurvan vid respektive trumhinna varierar enormt. Det är således inte den spektrala tonkurva som finns på dina respektive trumhinnor du hör som klang. En stor del av den spektrala tonkurvan är riktningsbestämmande kod som varierar då du roterar huvudet. Efter riktningsbestämmandet "trunkeras" denna kod, den har gjort sitt, så att klangupplevelsen inte skall variera på grund av denna kod. Det gäller inom viss gräns. Även detta har jag tidigare kommit in på.
Diskuteras det direktljud och lokalisation så är det detta jag först och främst diskuterar och inget annat. Jag vill gärna försöka cementera fenomenet direktljud och vad det är, ur alla möjliga synvinklar, innan jag går vidare i diskussionen.
Min ambition är att försöka kasta lite ljus över ett komplicerat ämne som ännu verkar vara ett mörker.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
JM skrev:Det där med direktljud är inte så självklart. Är direktljudet lika starkt som ett annat ljud identiskt ljud, framför nära lyssnaren, vilket anländer till örat samtidigt - uppfattas bara ett ljud vilket lokaliseras mitt emellan ljudkällorna. Typ att monoljud hamnar mittemellan stereohögtalarna. Detta gör att direktljudet från ett av Peters ägg för låga frekvenser hamnar mittemellan högtalarelementen medans vid högre frekvenser upplevs allmer komma från den närmaste högtalaren pga ökande beaming. Skugghögtalarens bidrag till direktljudet i de högsta frekvenserna minskar med ökande frekvens. Detta är bara av akademiskt intresse och påverkar i praktiken inte ljudupplevelsen.
Ett direkt klickljud följs av ett identiskt (map frekvens/ljudstyrka) klickljud efter 2 ms uppfattas som 2 olika ljud med olika lokalisation.
Ett prominent direkt talljud följt av ett identiskt talljud efter 20 ms men med 6 db dämpning uppfattas som bara ett ljud lokaliserat till det första ljudets position. Talet upplevs av en nornalhörande ungdom som extra klart spatialt medans en nybliven pensionär med normal åldersrelaterad hörselnedsättning upplever talet som något otydligt jämfört med samma tal på ett öppet fält. Hörselnedsättningen gör att reflexerna partiellt maskerar direktljudet.
Det intressanta är när reflexer av musik och tal likt i våra lyssningsrum kommer mellan 1-10 ms efter direktljudet. Prominenta reflexer maskerar partiellt i varierande grad direktljudet även hos individer utan hörselnedsättning. Det är här perceptionen avviker från mikrofonen registrering och varierar med åldern och olika hörselproblem trots normala audiogram. Hyperakusi har många utan att förstå att de har skadan och att det påverkar perceptionen. Många musiker och audiofiler har hyperakusi.
JM
JM - Jo, direktljud är självklart. Det är en tankevurpa att blanda ihop definitionen av direktljud med HUR VI UPPFATTAR LJUD.
Det du beskriver är några grundläggande egenskaper för hur vi detekterar riktning samt ETT UDDA SPECIALFALL.. Specialfallet, alltså två identiskt lika direktljud som du beskriver i början av ditt inlägg, kan man faktiskt betrakta som en brist (?) i människans utveckling av hörseln (evolutionen). Fantomprojektion med hjälp av 2 identiska ljudkällor är/var nog något som aldrig blev Beta-testat i vår fantastiska programvara i hjärnan! Hur många verkliga fall av 2 identiska ljudkällor kan vi hitta i naturen? Eller var det så att evolutionen förutspådde att " jo, människan kommer nog hitta på nåt som kommer kallas för stereo...." Det finns dock EN viktig fantomprojicering i naturen och det är när vi hör vårt eget tal som då hamnar mitt i huvudet*. Den påverkas dock av omgivande akustik och centerpunkten flyttas från mitt i huvudet till munnen (i ett frifältsrum eller typ "uppe på fjället" är centerpunkten mitt i huvudet, i ett vanligt rum längre fram) Såklart kan "att höra sig själv" tala genom fantomprojicering vara en medveten del i evolutionen då vi är väldigt beroende av detta för att ljuda korrekt.
Nu blev det kanske lite off topic! Prova/upplev själv fantomprojiceringen i huvudet när du talar. Prova i olika rum och ute och förundras hur centerpunkten flyttas..... så naturligt och ändå så förunderligt. Vår fantastiska hörsel/hjärna........
* Många vill nog inte kalla det för fantomprojicering då man kan hävda att det bara finns en ljudkälla = munnen. Det är dock inte korrekt då vi hör inte bara "utifrån", via ytterörat. Jag har dock full förståelse för dom som ändå hävdar att det inte är fantomprojcering då det inte handlar om att centerpunkten föskjuts i sidled utan framåt/bakåt. Vi får se hur mycket skit jag får för det.... det är ju verkligen ett unikt fall så det finns nog många teorier om rätt och fel. En kul test: Knacka på huvudet på olika ställen (och försök bortse från att du vet och känner var du knackar). Var lokaliserar du ljudet?
PS Är det någon som kan komma på ett bra exempel av/på fantomprojicering i naturen? DS
Lokalisering / precedence-effekt fungerar väl olika också beroende på om det är höga eller låga frekvenser det handlar om, samt om ljudet som skall lokaliseras är steady-state eller transient?
Personen som har världens bredaste huvud kanske har 2ms ”summing-localization”?
Jag tror jag fattar nu att jag har missförstått (eller snarare glömt av) precedence-effekt och lokalisering hur det fungerar. Vänt på det liksom, vad som sätts först i tiden av lokalisering och klang/timbre.
Det du skriver om trunkering, får konsekvensen att första millisekunden ”summing-localisation” bestämmer klangen/timbre nästan helt och hållet? Nä fan jag är förvirrad nu! Har läst för mycket i kombination med att ha glömt av för mycket. Fragmenterad.
rajapruk skrev:Jag tror jag fattar nu att jag har missförstått (eller snarare glömt av) precedence-effekt och lokalisering hur det fungerar. Vänt på det liksom.
Det du skriver om trunkering, får konsekvensen att första millisekunden bestämmer klangen/tonen nästan helt och hållet?
Oj, då har du helt missuppfattat det jag skrivit. Eller också har jag uttryckt mig väldigt dåligt eller båda delarna? Vad är det i det jag skrivit som får dig att dra den slutsatsen?? Tvärtom, under den första millisekunden sker enkom lokalisation av ljudkälla. Det är under den tiden som respektive öronsignal, som är 2 signaler, sammansmälter till 1 och endast 1 signal. Det kallas konvergens. 2 i tiden skilda signaler, en från höger öra och en från vänster öra skall konvergera till endast en signal med riktning. Klangen däremot integreras under lång tid och det är under den tid som precedence gäller. Vid undersökningar så har hörseln förmågan att integrera ljud med en fönstring på 500 ms och det är 0,5 sekunder. Det är ett så kallat tröskelvärde. Därefter inträffar nästa auditory event d v s hörselupplevelse. Det är den längsta fönstringstid som är möjlig för hörseln. Till exempel så behöver hörseln minst 35 ms för att höra/urskilja formanter på tal och sång. Det går inte under den tiden. Så, att tro att ljudet sätts under 1 eller 2 ms är inte korrekt utan snarast en total missuppfattning. Däremot sker riktningsbestämmande under denna ms. Lyssnar man på ett ljud som varar 1 ms upplevs det som en puls där man inte kan associera den med något, annat än en puls.
Så, VAR ljudet kommer från sker under första millisekunden. VAD ljudet är för något sker under tiden därefter. Tyvärr, tror jag att det inte kommer kunna förstås om inte det grundläggande förklaras och det tarvar ett ganska långt inlägg, eller snarast en hel serie långa inlägg.
Mvh Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
Aaah, skönt då hade jag bara en kort temporär morgonförvirring. Tror jag hängde upp mig på trunkerings-begreppet felaktigt.
Första millisekunden ger BARA lokalisering? Sätter INGEN klang? Summing-localization ljudet trunkeras helt och hållet från upplevd klang/timbre? Det skulle ju få enorma konsekvenser. Att direktljud bestämmer enbart riktning och att sedan rumsreflexer sätter klangen. Men jag kanske ska sluta dra slutsatser denna morgon. Det skulle väl i så fall kanske kunna förklara varför högtalare i ekofri kammare låter dåligt. Och här sitter jag med riktade högtalare... Har jag just blivit en Carlsson?
Direktljudet kan låta hur fan som helst nästan från en högtalare?? Bara totala energin ut i rummet är rätt så att senare ljud får rätt spektrum totalt?
Det skulle också kunna betyda att tidiga reflexer (som anländer efter summing-localization) är av godo, om det låter rätt? Det blir liksom ingen kamfiltereffekt/superposition med direktljudet pga att de anländer i olika tid/fas (för att direktljudet är trunkerat)? Det känns inte som det kan stämma? Är det ett paradigmskifte på gång i mitt huvud idag? Tänket "tidiga reflexer är automatiskt dåliga" går bort i så fall.
För att sluta cirkeln med center-högtalare, så skulle i så fall centern kunna spela L+R summerat, men fördröjt att anlända efter summing localization från L och R? 1ms fördröjd närmare bestämt. Och på så sätt stödja upp stereosystemfelen i ton, och även rumsakustiska problem och placeringsproblem av L och R, klangen blir "perfekt" från centerns direktljud, men inte stör lokaliseringen som är stereokodad från L och Rs direktljud första millisekunden. Då kan man ha 1 superduperklingande center (man kan läsa Bremen 3D8 här om man vill, frivilligt) , och två klangmässigt kassa högtalare på L och R som skickar ut vad fan som helst nästan bara de kan spela lika högt direktljud? Hallelelujah? Typ sätta in en bra center i JMs laserspridande system och det låter plötsligt bra och han kan slänga skruvstädet till huvudet? (skämt)
Fan det här får stora konceptuella konsekvenser för mig. Nästan så jag hoppas att jag missuppfattat. Konsekvenser för delning mellan element. Konsekvenser för placering av basar. Konsekvenser för akustikbehandling (dämpning är ofta dåligt då). Placering av högtalare. Hur en högtalare bör sprida. Hur man får en stor sweetspot. ALLT... Även om det kanske inte blir jättestora ändringar i praktiken av det. Jag har varit helt inriktad på att få till direktljudet "perfekt" (något jag då kanske knappt aldrig ens har hört klangen av), och sen minimera och senarelägga "tidiga" reflexer. Jag måste mäta på ett helt annat sätt i så fall.
Det blir till att gå ner i källaren ikväll och hämta upp en nerpackad JBL LSR305 och testa att sätta den som center, summerad och lite fördröjd. Spännande
Senast redigerad av rajapruk 2019-12-03 12:33, redigerad totalt 2 gånger.
goat76 skrev:Håller vi på att skapa en diskussion ur ingenting?
Jag har förstått att det var slarvigt skrivet av mig, nu får ni möta mig lite här och försöka förstå det jag ville ha sagt för nu är vi återigen i nomenklatur-träsket och rotar istället för att ni bara kan rätta mig med att säga: ”Kanske menar du så här...”
Sorry Goat, jag tänker inte möta dig. Jag vet att det jag säger är korrekt. Jag vill inte ens spekulera i vad du kanske måhända kan mena. Varför skulle jag göra det? Du får nog ta och bemöda dig att söka förstå orsak-verkan-sambanden så att en meningsfull diskussion kan formas.
Såg du inte vad som skedde på föregående sida där jansch bemödade sig att möta mig, jag kom snabbt till insikt i allt det jag tidigare missförstått vad gäller direktljud.
petersteindl skrev:Jag kan sträcka mig så långt att säga att du förväxlar och/eller blandar riktning/lokalisation med klang/timbre. Men de gör de flesta i tråden.
Se där, du har förmåga att sträcka dig halvvägs mot den som missförstått, ge honom en hand och dra honom till dig.
I de fall där du upptäcker att de flesta missförstått så kan jag tipsa dig om att du tänker till lite precis som jansch gjorde då han påpekade för mig att jag troligtvis blandade ihop riktningsverkan med direktljud.
petersteindl skrev:Dessutom undrar jag varför du anser att andra människor måste möta dig?? Varför då? Vad tillsätter du dig själv för betydelse egentligen? Varje människa får bemöda sig att söka förstå fysiken och att krypa fram även om man behöver ge upp sina gamla falsarier till idéer. Varför måste de som har korrekt svar möta just dig? Borde det inte vara tvärtom?!
Att möta mig halvvägs i diskussionen är inte lika med att godkänna något jag sagt eller att ge mig 50% rätt. Jag kan alltså ha 100% fel på den punkt som diskuteras, men om du sträcker ut en hand och istället ser möjligheten att jag blandat ihop riktningsverkan med direktljud så som jansch uppenbarligen upptäckte så kunde han med enkelhet övertyga och visa vad jag missförstått. Han visar prov på social förmåga att bemöta.
Sen måste jag ifrågasätta vad det är för (förlåt mig på förhand för kommande ordval) helvetes jävla sätt att på något vis antyda jag skulle tycka att just jag som person är viktig. Är det för mycket begärt att be dig försöka bemöta mig i diskusionen?
petersteindl skrev:Men, av dina senaste svar i tråden att döma så ser det ut som du kanske måhända har förstått att den raka linjen mellan ljudkälla och ljudmottagare utgör den linje varmed vektorn som symboliserar direktljudets riktning definieras.
Detta är oberoende av ljudkällans riktningskarakteristik eller ljudmottagarens rotation kring sin egen axel.
Så du hade allså kommit till insikt i att jag nu förstått att jag tidigare blandade ihop riktverkan med direktljud, varför skrev du då detta inlägg så som du gjorde???
rajapruk skrev:Aaah, skönt då hade jag bara en kort temporär morgonförvirring. Tror jag hängde upp mig på trunkerings-begreppet felaktigt.
Första millisekunden ger BARA lokalisering? Sätter INGEN klang? Summing-localization ljudet trunkeras helt och hållet från upplevd klang/timbre? Det skulle ju få enorma konsekvenser. Att direktljud bestämmer enbart riktning och att sedan rumsreflexer sätter klangen. Men jag kanske ska sluta dra slutsatser denna morgon. Det skulle väl i så fall kanske kunna förklara varför högtalare i ekofri kammare låter dåligt. Och här sitter jag med riktade högtalare... Har jag just blivit en Carlsson?
Direktljudet kan låta hur fan som helst nästan från en högtalare?? Bara totala energin ut i rummet är rätt så att senare ljud får rätt spektrum totalt?
Det skulle också kunna betyda att tidiga reflexer (som anländer efter summing-localization) är av godo, om det låter rätt? Det blir liksom ingen kamfiltereffekt/superposition med direktljudet pga att de anländer i olika tid/fas (för att direktljudet är trunkerat)? Det känns inte som det kan stämma? Är det ett paradigmskifte på gång i mitt huvud idag? Tänket "tidiga reflexer är automatiskt dåliga" går bort i så fall.
För att sluta cirkeln med center-högtalare, så skulle i så fall centern kunna spela L+R summerat, men fördröjt att anlända efter summing localization från L och R? 1ms fördröjd närmare bestämt. Och på så sätt stödja upp stereosystemfelen i ton, och även rumsakustiska problem och placeringsproblem av L och R, klangen blir "perfekt" från centerns direktljud, men inte stör lokaliseringen som är stereokodad från L och Rs direktljud första millisekunden. Då kan man ha 1 superduperklingande center (man kan läsa Bremen 3D8 här om man vill, frivilligt) , och två klangmässigt kassa högtalare på L och R som skickar ut vad fan som helst nästan bara de kan spela lika högt direktljud? Hallelelujah? Typ sätta in en bra center i JMs laserspridande system och det låter plötsligt bra och han kan slänga skruvstädet till huvudet? (skämt)
Fan det här får stora konceptuella konsekvenser för mig. Nästan så jag hoppas att jag missuppfattat. Konsekvenser för delning mellan element. Konsekvenser för placering av basar. Konsekvenser för akustikbehandling (dämpning är ofta dåligt då). Placering av högtalare. Hur en högtalare bör sprida. Hur man får en stor sweetspot. ALLT... Även om det kanske inte blir jättestora ändringar i praktiken av det. Jag har varit helt inriktad på att få till direktljudet "perfekt" (något jag då kanske knappt aldrig ens har hört klangen av), och sen minimera och senarelägga "tidiga" reflexer. Jag måste mäta på ett helt annat sätt i så fall.
Det blir till att gå ner i källaren ikväll och hämta upp en nerpackad JBL LSR305 och testa att sätta den som center, summerad och lite fördröjd. Spännande
Det är nog väldigt lätt för dig själv att visa medelst eget experiment att du har missförstått (igen). Du kan då att koppla upp två högtalare bredvid varandra där den ena får en fördröjd signal. Detta ger då kamfiltereffekter* (grav frekvensgångspåverkan) som låter som att sjunga i en dammsugarslang ungefär. Detta kan i ett utvecklat resonemang överföras på en högtalare som placeras i ett rum med reflekterande väggar; reflexerna är tidsfördröjda relativt direktljudet (och kommer även från andra riktningar) och har även en annan frekvensgång. Det man som människa uppfattar blir en blandning av dessa ljud klangmässigt (inom hörselns "integrationstid"), däremot uppfattar vi riktningen till där högtalaren står. Jag håller inte med dig om att tidiga reflexer skulle vara något av godo för ljud/musikåtergivning genom högtalare, däremot för musicerande eller taluppfattbarhet kan det vara av godo.
Inte lätt för Peter S att förklara, ju mer han skriver desto mer märkliga slutsatser dras...
Ordförande i Ljudtekniska Sällskapet sedan 17:e april 2025
Jo, men detta blir ju liknande kamfiltereffekter i alla riktningar, inte bara i direktljudet, så det kommer höras, eftersom reflexer även kommer innehålla detta. Så det motsäger inte min slutsats. Tror jag Så jag tror det var din slutsats som var märklig nu, hahaha
Samtidigt får jag inte ihop hur hörlurslyssning fungerar i så fall (om min slutsats stämmer), som bara har direktljud. Så jag är nog snett ute ändå. Eller inte! Jag har aldrig kunnat njuta av hörlurslyssning faktiskt.
Senast redigerad av rajapruk 2019-12-03 13:15, redigerad totalt 4 gånger.
Har inte läst alla inlägg i tråden, men några har jag läst (typ de första fem i tråden), och flera saker vill jag därför kommantera:
1. Planvåg är ett begrepp vars uppkomst INTE beror på avstånd från ljudkälla, alls! Missförstå mig inte - självklart man man använda ord humanistiskt och ”tycka” att en våg är plan då den har en viss planhet (radie), men den väsentliga faktorn är den akustiska impedansen i vågen, och den är frekvensberoende, det vill säga den bestäms av förhållandet mellan radien och frekvensen. Så från en punktformig ljudkälla så har man (fysikaliskt sett, inget luddigt humanistordbruk nu) definitivt en plan våg (=planvågsimpedans råder, det vill säga man har passerat knäpunkten där man övergår från böjvåg till planvåg i frekvensplanet) 50 cm från ljudkällan, om frekvensen är 500 Hz. Men är frekvensen 20 Hz så är så alls inte fallet! Inte ens när man är 5 meter från en punktformig ljudkälla så har man planvåg för en 20Hz-ton*
2. Det har talats om kamfiltereffekter, men några sådana har INGET med två sinustoner som möts att göra. Kamfilter är inte ett ljud (eller två) eller något som har med tryck i rummet att göra. Det är en speciell sorts överföringsfunktion, alltså något som finns även utan signaler. Om man utgår ifrån en svept sinus eller ett rosa brus och tvingar den igenom nömnd överföringsfunktion, så får man en tunkurva som visar kanfilterfuktionen. Kanske blandades det mönster i rummet som ståendevågen visar, ihop med en kamfiltereffekt? Men det är alltså helt olika saker. Båda skapas av interferens, men den ena som funktion av frekvens, den andra som funktion av position i rummet.
- - -
Nu svar på själva frågan om vad som händer när två sinusoidala ljudvågor (av samma frekvens) som brer ut sig i motsatt riktning möter varandra. Svaret är att man får två vågor:
•En stående våg vars styrka (peakljudtryck) är summan av de två ursprungliga och vars noder och bukar bestäms av faslägena, och,
•En vandrande våg vars styrka bestäms av differensen mellan dem. Är differensen noll så blir det bara en stående våg.
- - -
Svårare än så är det inte. I varje fall inte mycket svårare. Men lite svårare är det förstås, jag har förenklat lite. Har inte tid att skriva allt.
Vh, iö
- - - - -
*Det betyder dock INTE (som har antytts i tråden) att man behöver mäta mer än 5 meter från högtalare för att få en korrekt bild av dess tonkurveegenskaper. Det är nämligen inte alls planvågsförhållanden som primärt behöver uppfyllas för att en mätning skall vara relevant. Snarare handlar det om att eliminera närfältsbeteenden (nära en baffel blir baffelns ”ostöd” vid låga frekvenser underdrivet) och i hög grad handlar det också om att eliminera geometisk distorsion.
Så de flesta högtalare kan rimligt väl kartläggas på någon meters avstånd. Riktigt stora högtalare kan behöva mätas på mer än 3 meters avstånd för att man skall få en relevant bild av deras klangegenskaper.
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
Har nu läst även i slutet av tråden, och reagerar på dialogen mellan Peter och Rajapruk. Det ni skriver (Rajapruk i högre grad frågar, Peter i högre grad redovisar) innehåller vissa OTROLIGA förenklingar. Förenklingar som är våldsamt osanna i en mera komplex verklighet.
Om man redovisat saker med noggrant redovisade premisser (ställer man upp ett experiment såhär så får man detta resultat), så hade jag inte sagt något men de påståenden som syns i tråden är långt längre dragna än så, och de är INTE korrekta. Generaliseringarna av de slag som synts är inte exempel på tillåtna slutsatser.
Faktorer som frekvensregister och anländanderiktningar och senare anländande ljuds karaktär, fördröjning och multiplicitet är MYCKET betydelsefulla för den upplevelse som fås! Men det räcker inte med det - själva musiksignalen betyder också en massa. En anläggning/uppställning kan ha en mycket linjär (och därför också tidsinvariant) överföringsfunktion, men trots det så kan det påverka olika programmaterial väldigt olika. En faktor är också inspelnkngars val av stereofonikodning.
Jag blir smått oroad då jag ser att även vissa ”komplexa svar” i tråden gör förfärliga förenklingar. Men det är inte ett enkelt ämne... Jag kanske borde vara mera tolerant?
Känner dock att man gör folk en missgärning när man svarar exakt fel, och jag har sett lite sådant i tråden. Bättre att svara ungefär rätt. Och att vara supertydlig med just ”ungefär-faktorn”.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
Det skulle också kunna vara "obehagliga sanningar" för tillverkare av högtalare som har stereosystemfelskompensation inbyggt som förs på tal nu? Eller för rumsakustiker som jobbar med mycket dämpning av tidiga reflexer? Som nu ska försöka störsända bort detta, och scramblea det med hjälp av alla möjliga tillgängliga härskartekniker?
Nej, nu skojbråkar jag bara lite (jag tror inte på det jag skrev ovan i detta inlägget)
En annan grej med "min" slutsats (min nuvarande förståelse snarare) skulle kunna ha bäring på det att anläggningar ofta låter bättre på högre volym än på låg volym (till en viss gräns). Det kanske till viss del är för att reflexer som anländer efter summing-localization då kommer upp i hörbar amplitud? Som gör att vissa detaljer kan höras överhuvudtaget, även om de är teoretiskt hörbara amplitudmässigt i direktljudet på lägre volym? Jag svingar vilt nu
Och jag tvingas erkänna att jag inte ens förstår vad det är för ”sanning” som du menar att du kommit med, och som du tycks tänka att jag kritiserar. Kan du utveckla?
Jag har ju inte kritiserat någon ”sanning” typ alls, bara klargjort att det gjorts otillåtna förenklingar.
Annars så tror jag inte på din högspelningshypotes. Det finns dels alldeles utmärkta förklaringsmodeller redan som det är, och därtill så är de reflekterade ljuden (uppenbart) MYCKET starkare än du tror.
I de flesta lyssningsrum är de reflekterade ljuden (tillsammans) starkare än direktljudet.
Pik-varning: Jag tror det kan vara fördelaktigt att lära sig lite grundläggande fysik innan man spekulerar om sådana här saker. Självklart får man spekulera hur mycket man vill, men oddsen att det skall bli hypoteser med bäring är inte överväldigande.
(Jag litar på att din humor är aktiverad.)
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
Har inte läst alla inlägg i tråden, men några har jag läst (typ de första fem i tråden), och flera saker vill jag därför kommantera:
1. Planvåg är ett begrepp vars uppkomst INTE beror på avstånd från ljudkälla, alls! Missförstå mig inte - självklart man man använda ord humanistiskt och ”tycka” att en våg är plan då den har en viss planhet (radie), men den väsentliga faktorn är den akustiska impedansen i vågen, och den är frekvensberoende, det vill säga den bestäms av förhållandet mellan radien och frekvensen. Så från en punktformig ljudkälla så har man (fysikaliskt sett, inget luddigt humanistordbruk nu) definitivt en plan våg (=planvågsimpedans råder, det vill säga man har passerat knäpunkten där man övergår från böjvåg till planvåg i frekvensplanet) 50 cm från ljudkällan, om frekvensen är 500 Hz. Men är frekvensen 20 Hz så är så alls inte fallet! Inte ens när man är 5 meter från en punktformig ljudkälla så har man planvåg för en 20Hz-ton*
2. Det har talats om kamfiltereffekter, men några sådana har INGET med två sinustoner som möts att göra. Kamfilter är inte ett ljud (eller två) eller något som har med tryck i rummet att göra. Det är en speciell sorts överföringsfunktion, alltså något som finns även utan signaler. Om man utgår ifrån en svept sinus eller ett rosa brus och tvingar den igenom nömnd överföringsfunktion, så får man en tunkurva som visar kanfilterfuktionen. Kanske blandades det mönster i rummet som ståendevågen visar, ihop med en kamfiltereffekt? Men det är alltså helt olika saker. Båda skapas av interferens, men den ena som funktion av frekvens, den andra som funktion av position i rummet.
- - -
Nu svar på själva frågan om vad som händer när två sinusoidala ljudvågor (av samma frekvens) som brer ut sig i motsatt riktning möter varandra. Svaret är att man får två vågor:
•En stående våg vars styrka (peakljudtryck) är summan av de två ursprungliga och vars noder och bukar bestäms av faslägena, och,
•En vandrande våg vars styrka bestäms av differensen mellan dem. Är differensen noll så blir det bara en stående våg.
- - -
Svårare än så är det inte. I varje fall inte mycket svårare. Men lite svårare är det förstås, jag har förenklat lite. Har inte tid att skriva allt.
Vh, iö
- - - - -
*Det betyder dock INTE (som har antytts i tråden) att man behöver mäta mer än 5 meter från högtalare för att få en korrekt bild av dess tonkurveegenskaper. Det är nämligen inte alls planvågsförhållanden som primärt behöver uppfyllas för att en mätning skall vara relevant. Snarare handlar det om att eliminera närfältsbeteenden (nära en baffel blir baffelns ”ostöd” vid låga frekvenser underdrivet) och i hög grad handlar det också om att eliminera geometisk distorsion.
Så de flesta högtalare kan rimligt väl kartläggas på någon meters avstånd. Riktigt stora högtalare kan behöva mätas på mer än 3 meters avstånd för att man skall få en relevant bild av deras klangegenskaper.
De sista sex-sju raderna du skriver kan jag verkligen skriva upp och hålla med om. Det stämmer väldigt väl med min egen erfarenhet av högtalarmätningar på amatörnivå. Jag håller även med Johan Lindroos inlägg där han skriver att riktigt tidiga reflexer inte är någonting bra för en god återgivning från en högtalare i ett lyssningsrum.
I övrigt har jag inte förstått allt om planvågsresonemanget, men är lite förvånad att väldigt mycket i denna tråd motsäger* det man kan läsa på tex Wikipedia eller i Tooles böcker om precedenceeffekten mm.
*(Dock inte IÖ:s eller Johan Lindroos inlägg- samma information som de beskriver kan även hittas/läsas om på annat håll )
rajapruk skrev:Första millisekunden ger BARA lokalisering? Sätter INGEN klang? Summing-localization ljudet trunkeras helt och hållet från upplevd klang/timbre? Det skulle ju få enorma konsekvenser. Att direktljud bestämmer enbart riktning och att sedan rumsreflexer sätter klangen. Men jag kanske ska sluta dra slutsatser denna morgon. Det skulle väl i så fall kanske kunna förklara varför högtalare i ekofri kammare låter dåligt. Och här sitter jag med riktade högtalare... Har jag just blivit en Carlsson?
Nu verkar det nästan som om du glömmer bort att det är extremt få ljud i musik som är så korta som 1 ms eller mindre. Resten av direktljudet som kommer efter 1ms sätter ju fortfarande den huvudsakliga klangen
rajapruk skrev:Direktljudet kan låta hur fan som helst nästan från en högtalare?? Bara totala energin ut i rummet är rätt så att senare ljud får rätt spektrum totalt?
Det ljud som når lyssnaren till största del är ju direktljudet så det kan ju inte låta hur fan som helst.
rajapruk skrev: Det skulle också kunna betyda att tidiga reflexer (som anländer efter summing-localization) är av godo, om det låter rätt? Det blir liksom ingen kamfiltereffekt/superposition med direktljudet pga att de anländer i olika tid/fas (för att direktljudet är trunkerat)? Det känns inte som det kan stämma? Är det ett paradigmskifte på gång i mitt huvud idag? Tänket "tidiga reflexer är automatiskt dåliga" går bort i så fall.
Tidiga reflexer är alltid skadliga och bidrar endast till att diffusera direktljudet. Kanske kan den tidiga reflexen hjälpa ett ljud på 1ms eller kortare för att vi ska hinna upptäcka det.
rajapruk skrev:För att sluta cirkeln med center-högtalare, så skulle i så fall centern kunna spela L+R summerat, men fördröjt att anlända efter summing localization från L och R? 1ms fördröjd närmare bestämt. Och på så sätt stödja upp stereosystemfelen i ton, och även rumsakustiska problem och placeringsproblem av L och R, klangen blir "perfekt" från centerns direktljud, men inte stör lokaliseringen som är stereokodad från L och Rs direktljud första millisekunden. Då kan man ha 1 superduperklingande center (man kan läsa Bremen 3D8 här om man vill, frivilligt) , och två klangmässigt kassa högtalare på L och R som skickar ut vad fan som helst nästan bara de kan spela lika högt direktljud? Hallelelujah?
Det blir till att gå ner i källaren ikväll och hämta upp en nerpackad JBL LSR305 och testa att sätta den som center, summerad och lite fördröjd. Spännande
Jag gjorde precis ett litet test som visar vad som sker med direktljudet med en centerkanal som summerats till mono, och vad som sker om denna summerade mono-signal fördröjs med 1 ms respektive 2 ms.
I testet så agerar höger högtalare center-kanal och spelar upp den summerade monokanalen och den vänstra kanalen spelar endast upp det ljud från stereospåret som tillhör just vänstra kanalen. Tänk nu som så att höger högtalare är urkopplad och det ljud som i testet nu kommer från den högtalaren är en center-högtalare.
0:00 - 0:10 Ett summerat mono-spår spelas ensamt upp i center-högtalaren (höger högtalare).
0:10 - 0:20 Vänster kanal spelar endast upp vänstra halvan av stereospåret samtidigt som "centern" fortsätter spela det summerade mono-spåret. Nu hör man tydligt en stereomix vars mitt ligger mitt emellan "centern" och vänster högtalare (vilket i detta test är precis i mitten av L och R).
0:20 - 0:30 En 1 ms fördröjning läggs på det summerade monospåret från "centern" vilket ger en ganska diffus ljudbild där det är ganska svårt att peka ut vart ifrån de enskilda ljuden i mixen verkligen kommer ifrån. Det är tydligt hur mycket skada en fördröjning på 1 ms från centern ger och fas-förskjutningen skapar ett väldigt ihåligt och glest ljud.
0:30 - 0:40 Nu ökas fördröjningen till 2 ms och man kan nu höra att musiken får tillbaka lite mer av sin "kropp" och sången har tydligt dragit sig ut någonstans mot vänster högtalare, men fasförskutningen har egentligen bara flyttat på sig och förstärker nu vissa frekvenser något mer godartat för just detta specifika musikstycke. Helheten låter dock fortfarande något ihåligt.
0:40 - 0:54 Här har jag tagit bort fördröjningen och återgått till det som spelades i partiet 0:10 - 0:20 för att återigen visa hur det egentligen ska låta, och varför det är viktigt att den summerade mono-signalen från center-kanalen alltid bör spela tidsmässigt i rätt fas med vänster och höger kanal.
Om man däremot på något trovärdigt sätt kan filtrera fram det som endast ska spelas i centern från ett stereospår, och filtrera bort det samma från vänster och höger kanal så kan man isåfall styra och ställa över både bredd och djup lite som man behagar. Men hur görs då detta på ett lyckat sätt som fungerar bra för de flesta stereo-mixar?
P.S. Jag är medveten om att flera som läser tråden förstår allt detta, men det är alltid kul med lite praktik mitt i allt teori-snack.
petersteindl skrev:Fast, det är så man gör med användandet av flera basmoduler. Men det kanske inte är det du menar? Vad är det du vill ha sagt?
Är det att dåliga metoder är dåliga? I så fall håller jag med.
Sedan kan jag bara konstatera att missförstånden över hur ljud funkar fullkomligt haglar i några av de trådar som nu är aktuella. Det gäller exempelvis vad direktljud är, precedenceeffekten, vad som händer inom 2 ms, etc. Jag blir alldeles matt då jag läser allt i inläggen. Det blir lätt ett heltidsarbete att försöka reda ut.
Mvh Peter
Blir du lika matt av mitt inlägg här ovan, ser du några felaktigheter?
Egentligen hela inlägget.
goat76 skrev:
rajapruk skrev:Ok, nu ska jag försöka provocera fram att Peter avslöjar sin centerkanalshemlighet!
Jag tänker göra såhär för att mixa upp 2-kanal till surroundljud att spela i en flerkanalsanläggning med identiska högtalare runtom. Målet är en stor och stabilt centrerad ljudbild, som kan höras från en stor sweetspot, och stereosystemfel reducerade.
1. Jag skickar ut en kopia av ljudet 20ms fördröjt till surroundkanalerna, -3dB kanske. L-kanal går till L surround. R-kanal går till R-surround. Godartade reflexer bakifrån rummet simuleras. Detta ger förhoppningsvis känslan av en större lokal och större ljudbild.
2. Jag jämför L och R kanalerna och hittar allt ljud som är samma i dem. Detta är det ljud som skall upplevas komma från mitten antar jag. Detta ljud skickas till centern. Frågan är sedan om L och R enbart skall spela det för dem unika ljudet, eller även lite av centerns ljud? Det får jag testa mig fram med. Speciellt basen vill man väl nyttja alla högtalare för.
"Jag jämför L och R och hittar allt ljud som är samma i dem" - hur göra det rent praktiskt? Hmmm....
2.1. Nisse = L - ((L + R) / 2) Nisse innehåller alltså L utan allt som är gemensamt med R.
2.2. Bosse = R - ((L + R) / 2) Bosse innehåller alltså R utan allt som är gemensamt med L.
2.3. Centern Kalle skall spela enbart det som är gemensamt i L och R. Kalle = (L - Nisse) + (R - Bosse)
Slutgiltig output: L = Nisse (+ 0.5 Kalle kanske för att mjuka till övergång) R = Bosse (+ 0.5 Kalle kanske för att mjuka till övergång) C = Kalle (-0.5 Kalle om det lagts till Kalle i Nisse och Bosse också)
Plus görs med summering i dsp. Minus görs med summering med en invers/fasvänd i dsp. Division med 2 görs med -3dB i dsp. (Är jag rätt ute här??)
3. Eller så skiter man i allt det här i 2.x ovan, och bara låter C spela: (L+R)/2, fast fördröjt minst 2ms efter L och R. Så centern bara tillför lite mjukt av totala ljudet för att jämna ut stereosystemfel, men det kommer fördröjt efter att hörseln lokaliserat varifrån ljudet skall komma i stereomixen och i lägre amplitud, men ändå inom tiden det integreras tonmässigt av hörseln.
Klockan är mycket. Hjärnan är mosig. Ovan innehåller säkert massa feltänk, men det är det som är meningen. Peter skall provoceras av detta och avslöja företagshemligher i affekt! Om inte Peter skjuter detta fullständigt i sank, så vet vi att jag är på rätt spår
Jag har suttit här och tänkt lite på det du skriver här och har själv tidigare snurrat runt i liknande funderingar hur en center i Peters lösning fungerar, men nu har jag kommit fram till att både du och jag har överanalyserat vikten av att sålla fram något som endast ska komma från center-högtalaren.
Det enda man egentligen behöver göra är följande:
1. Både L och R får sina vanliga signaler.
2. Center-kanal C får rakt av en mono-signal, en summering av L och R.
3A. Det optimala är att alla tre högtalare är placerade med exakt samma avstånd till en tänkt sweetspot.
3B. Om punkt 3A inte är fysiskt genomförbart i det specifika lyssningrummet och C befinner sig närmare lyssnaren så bör den kanalen få en så nära på exakt fördröjning i millisekunder beräknat på 1ms = 34,4cm (eller om man vill räkna ut det ännu mer exakt för den miljön man befinner sig i vad gäller temperatur och luftfuktighet).
3C. Man kan leka med större grad av fördröjning i C för att uppnå ett uppfattat större djup i ljudbilden men då uppstår det mer och mer uppenbara fasfel för enskilda ljudelement i mixen. Beroende på vilka frekvenser dessa ljudelement består utav så kan dessa fasfel subjektivt låta både bättre eller sämre beroende på vilka frekvenser som förstärks respektive försvagas, därför är det nog inte önskvärt att på detta sätt fejka en djupare ljudbild.
4. Nivån på C anpassas tills önskad bredd i ljudbilden är uppnådd och ljudbildens bredd minskar succesivt ju starkare ljudnivån är i C. Exempel: Om ljudnivån på lyssningsplats uppfattas som exakt lika starkt från C och L och ett ljudelement i mixen har panorerats 100% till vänster så kommer nu detta ljud att uppfattas komma exakt mittemmelan C och L, förutsatt att man anpassat fördröjningen eller det fysiska avståndet till det samma i punkt 3A eller 3B.
Ovanstående parametrar är enligt mig egentligen de enda man behöver förhålla sig till. Att helt enkelt låta C spela upp en mono-signal av stereomixen och endast anpassa en fördröjning efter fysiska avståndsskillnader mellan de tre kanalerna och anpassa nivån i centerkanalen så kommer nog pusselbitarna falla på plats på det mest naturliga sättet.
Att däremot försöka utvinna någon slags modifierad centerkanal ur vänstra och högra kanalen blir nog på sin höjd bara mer eller mindre dåligt.
Det räcker alltså med att ett och samma ljud i inspelningen nås örat precis samtidigt från alla tre högtalare (eller två om det är ett fullt panorerat ljud till vänster eller höger).
Med en centerkanal har man nog vunnit en bredare sweetspot, eller kanske snarare så är sweetspoten inte lika tydligt allra bäst på lyssningsplatsen precis i mitten rakt framför centern, men jag vet inte hur Peters ägg ser ut och i vilka riktningar de utstrålar direktljudet.
Det blåmarkerade är, enligt mitt sätt att se på saken, konstigheter. Men det finns ytterligare konstigheter som jag dock för närvarande inte vill upplysa om. Jag nöjer mig med att kommentera din frågeställning gällande direktljud och hur Peters ägg ser ut.
Av det jag sett så är i stort sett samtliga inlägg på faktiskt gällande direktljud med emfas och nästan enkom förknippat med ljudkällan och möjligtvis även med dess utstrålning.
Du frågar nu i vilka riktningar äggen utstrålar direktljudet. Frågan är dock helt felställd och tyder på en total missuppfattning över vad direktljud är för något. Jag skall försöka förklara, åtminstone en liten del av det hela, den del jag anser behövs just nu. Jag vill ogärna vara magistral. Det betyder dock att det måste finnas en ömsesidig kommunikation och att det jag säger skapar eftertanke. Det är i alla fall min förhoppning. Du kan ge dig på att allt jag skriver har föregåtts av extremt mycket eftertanke innan jag skriver.
Låt oss titta på en pulserande sfär. [ Bild ] I vilken riktning anser du att direktljudet är? Det är en väldigt retorisk fråga och medvetet ställd så. Jag har nämnt detta i tidigare inlägg. Direktljudet är en vektor. Vilken riktning har denna vektor?
Så här ser det ut om man lägger in ljudtryck. OBS, det är tryck i Pascal och inte absolutbeloppet eller medelvärdet, d v s det är både positiva och negativa tryck i förhållande till atmosfärstrycket.
[ Bild ] I denna animering ville man åskådliggöra hur ljudtrycket i SPL minskar med avståndslagen.
Men, nu talar vi riktning och direktljud.
Återigen. I vilken riktning anser du att direktljudet är? från denna sfäriska ljudkälla.
Jag skall ge en annan synvinkel på frågeställningen. En högtalare är monterad på vägg och har denna utstrålning.
I vilken riktning anser du att direktljudet är? från denna väggmonterade ljudkälla? D v s vilken vinkel på vektorn?
Om du svarar på detta så återkommer jag i frågan. OBS! Jag frågar för att sätta igång en tankeverksamhet.
Med vänlig hälsning Peter
Nu var ju inte frågan ställd till mig, men då jag inte sett någon svara på den så har begreppet ”direkljud” inte ensamt med ljudkällan att göra. Direktljudet är det som kommer från ljudkällan till lyssnaren. Det blir också det först anländande ljudet i normalfallet (det finns dock specialfall (hoppas jag slipper ta upp dem)).
Så hur ljudutstrålningen från en ljudkälla ser ut saknar i princip betydelse, direktljudet är de som strålar (i valfri riktning) mot lyssnaren.
Lite mera komplext blir det om man drar in ljudkällans former och den diffraktion som den ger. Om man t ex har ett bredbandselement på en 4x4 meter stor baffel, skall man då kalla hela denna jättelika högtalare för ”ljudkällan”, eller är kantreflexerna reflekterade ljud, skilda från direktljudet? Det är en filosofisk fråga om man anfaller den från en humanistisk synvinkel, men från ett mera tekniskt perspektiv så kan det kanske kännasrimligt att sätta en gräns i tidsdomän. Med perseptionen som utgångspunkt kan det vara frestande att säga att alla reflexer som anländer inom 1 eller 2 ms (3-6 dm gångväg) ingår i direktljudet.
Men studerar man saken kliniskt så märker man att man inte kan angripa frågan bara med kunskap om nervsystemet som grund (närmare bestämt hörsystenets ”klockfrekvens”) utan man måste även ta hänsyn till sådant som anländanderiktningar och frekvens. Vid mycket låga frekvenser smälter flertalet av rummets primärreflexer ihop med direktljudet och blir oskiljbara sett psykoakustiskt.
Hittade även tidigare i tråden ett påstående som var gravt felaktiskt (bland väldigt många andra felaktiga påståenden... inlägget var så fullt av tvärsäkra tok-påståenden att arbetet med att nysta upp det är för stort), nämligen att två transienter identiska men skiljda bara i tiden med 2 ms, uppfattas som två transienter. Exempel på detta är att man klappar händerna 3 dm framför en vägg.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
IngOehman skrev:Nu var ju inte frågan ställd till mig, men då jag inte sett någon svara på den så har begreppet ”direkljud” inte ensamt med ljudkällan att göra. Direktljudet är det som kommer från ljudkällan till lyssnaren. Det blir också det först anländande ljudet i normalfallet (det finns dock specialfall (hoppas jag slipper ta upp dem)).
Kanske handlar följande bild om det du helst vill slippa ta upp, diffraktion?
The long wavelength sounds of the bass drum will diffract around the corner more efficiently than the more directional, short wavelength sounds of the higher pitched instruments. http://hyperphysics.phy-astr.gsu.edu/hb ... ffrac.html
Senast redigerad av goat76 2019-12-03 16:32, redigerad totalt 1 gång.
Har inte läst alla inlägg i tråden, men några har jag läst (typ de första fem i tråden), och flera saker vill jag därför kommantera:
1. Planvåg är ett begrepp vars uppkomst INTE beror på avstånd från ljudkälla, alls! Missförstå mig inte - självklart man man använda ord humanistiskt och ”tycka” att en våg är plan då den har en viss planhet (radie), men den väsentliga faktorn är den akustiska impedansen i vågen, och den är frekvensberoende, det vill säga den bestäms av förhållandet mellan radien och frekvensen. Så från en punktformig ljudkälla så har man (fysikaliskt sett, inget luddigt humanistordbruk nu) definitivt en plan våg (=planvågsimpedans råder, det vill säga man har passerat knäpunkten där man övergår från böjvåg till planvåg i frekvensplanet) 50 cm från ljudkällan, om frekvensen är 500 Hz. Men är frekvensen 20 Hz så är så alls inte fallet! Inte ens när man är 5 meter från en punktformig ljudkälla så har man planvåg för en 20Hz-ton*
2. Det har talats om kamfiltereffekter, men några sådana har INGET med två sinustoner som möts att göra. Kamfilter är inte ett ljud (eller två) eller något som har med tryck i rummet att göra. Det är en speciell sorts överföringsfunktion, alltså något som finns även utan signaler. Om man utgår ifrån en svept sinus eller ett rosa brus och tvingar den igenom nömnd överföringsfunktion, så får man en tunkurva som visar kanfilterfuktionen. Kanske blandades det mönster i rummet som ståendevågen visar, ihop med en kamfiltereffekt? Men det är alltså helt olika saker. Båda skapas av interferens, men den ena som funktion av frekvens, den andra som funktion av position i rummet.
- - -
Nu svar på själva frågan om vad som händer när två sinusoidala ljudvågor (av samma frekvens) som brer ut sig i motsatt riktning möter varandra. Svaret är att man får två vågor:
•En stående våg vars styrka (peakljudtryck) är summan av de två ursprungliga och vars noder och bukar bestäms av faslägena, och,
•En vandrande våg vars styrka bestäms av differensen mellan dem. Är differensen noll så blir det bara en stående våg.
- - -
Svårare än så är det inte. I varje fall inte mycket svårare. Men lite svårare är det förstås, jag har förenklat lite. Har inte tid att skriva allt.
Vh, iö
- - - - -
*Det betyder dock INTE (som har antytts i tråden) att man behöver mäta mer än 5 meter från högtalare för att få en korrekt bild av dess tonkurveegenskaper. Det är nämligen inte alls planvågsförhållanden som primärt behöver uppfyllas för att en mätning skall vara relevant. Snarare handlar det om att eliminera närfältsbeteenden (nära en baffel blir baffelns ”ostöd” vid låga frekvenser underdrivet) och i hög grad handlar det också om att eliminera geometisk distorsion.
Så de flesta högtalare kan rimligt väl kartläggas på någon meters avstånd. Riktigt stora högtalare kan behöva mätas på mer än 3 meters avstånd för att man skall få en relevant bild av deras klangegenskaper.
De sista sex-sju raderna du skriver kan jag verkligen skriva upp och hålla med om. Det stämmer väldigt väl med min egen erfarenhet av högtalarmätningar på amatörnivå. Jag håller även med Johan Lindroos inlägg där han skriver att riktigt tidiga reflexer inte är någonting bra för en god återgivning från en högtalare i ett lyssningsrum.
I övrigt har jag inte förstått allt om planvågsresonemanget, men är lite förvånad att väldigt mycket i denna tråd motsäger* det man kan läsa på tex Wikipedia eller i Tooles böcker om precedenceeffekten mm.
*(Dock inte IÖ:s eller Johan Lindroos inlägg- samma information som de beskriver kan även hittas/läsas om på annat håll )
Det kan möjligen bero på att det väl i princip bara är Johan Lindroos och jag (av dem som skrivit i tråden) som arbetat ett halv liv med akustik.
De flesta andras inlägg ger mig intrycket att vara skrivna av någon som kanske läst litegrann och känner till några begrepp, men som i mindre eller högre grad missförstått sammanhangen och komplexiteten.
Och det är absolut begripligt! För de flesta vill ju vara en som förstår, en som kan berätta för andra, man vill därför gärna att allt skall vara tillräckligt enkelt, så enkelt att man ”redan förstår det”. Det är ju enklare när det är det.
Men - varken vår funktion som hörande varelser eller fysiken i övrigt bryr sig, de är så komplicerade som de är.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
IngOehman skrev:......................*Det betyder dock INTE (som har antytts i tråden) att man behöver mäta mer än 5 meter från högtalare för att få en korrekt bild av dess tonkurveegenskaper. Det är nämligen inte alls planvågsförhållanden som primärt behöver uppfyllas för att en mätning skall vara relevant. Snarare handlar det om att eliminera närfältsbeteenden (nära en baffel blir baffelns ”ostöd” vid låga frekvenser underdrivet) och i hög grad handlar det också om att eliminera geometisk distorsion.
Så de flesta högtalare kan rimligt väl kartläggas på någon meters avstånd. Riktigt stora högtalare kan behöva mätas på mer än 3 meters avstånd för att man skall få en relevant bild av deras klangegenskaper
Vh, iö
Vad menar du med "rimligt väl kartläggas"? Jag har visserligen inte jobbat "ett halvt liv" i frifältsrum men har gjort mätningar på 100-tals högtalare i den miljön. Du använder begreppet "planvåg" och "planvågsförhållande" och att det inte primärt behöver uppfyllas för att en mätning skall vara relevant. Jag vet inte om jag misstolkar dej men en plan vågfront krävs för att en frifältsmikrofon skall mäta korrekt. Då menas givetvis att det dynamiska trycket skall vara homogent över hela membranytan. Är "planvåg" och plan vågfront samma sak för dej?
Vid traditionell placering av mätmikrofonen, alltså i diskantens nollaxel på "flervägare" är det mer regel än undantag att differenser på +/- 2dB uppstår mellan 1 meters och 2meters mätningar. Jag har aldig märkt några större förändringar när mätavståndet är över ett par meter. Visserligen går det att minimera skillnadeni resultat med lägre skrivhastighet eller "smothing" som det numera kallas. Vid polärdiagramsmätninggar är det ännu mer uppenbart. Jag är medveten om att mätning i diskantens o-axel egentligen inte är korrekt men det är ju en annan sak. Bruel&kjaer rekommenderar sedan 70-talet att alltid ha minst en meter om ljudkällan är enkel (ett högtalarelement) för att vågfronten skall vara acceptabel för en frifältsmikrofon.
1. ”Flervägare” är ett diffust begrepp, som i sig inte säger särskilt mycket om hur stor ljudkällan är. De flesta högtalare som existerar är små, så små att 1 meter är ett tillräckligt avstånd för att man skall hamna i högtalarens fjärrfält. Men du såg väl att jag också talade om att större högtalare kan kräva mätavstånd på över 3 meter?
2. Att mäta på diskantens nollaxel ger alltid geometrisk distorsion! (Diskanten blir proportionellt närmare på kortare mätavstånd) Jag tolkar det du skriver som att du är medveten om detta problem. Det blir definitivt märkbart när man rör sig från en till två meters mätavstånd. Högtalartillverkare som definierar detta som lyssningsaxeln tycks mig inte ha tänkt igenom saken särdeles väl (om inte högtalaren är vertikalsymmetrisk). Så är de också påfallande ofta omedvetna om att det i princip dikterar ett fast lyssnkngsavstånd*.
3. Lägre skrivarhastighet och smothing är två olika saker. Lägre skrivarhastighet är därtill inte ett entydigt begrepp och ger i sin vanligare betydelse (”pappershastighet”) dessutom en mera högupplöst mätning. Kanske är det lägre ”pennhastighet” du talar om? Jag gissar det. Det är hur som helst inte heller samma sak som smothing. I synnerhet inte när man talar om mätningar i icke-ekofria rum.
4. Du skriver lite om planvågsförhållanden, och du har både fel och rätt... Du har rätt i att membranet behöver tryckutsättas homogent. Men du har inte rätt i att det kräver planvågsförhållanden. Vid 20 Hz har man inte planvågsförhållande från någon högtalare, ens på lyssningsplats! Men ändå har man mycket hög tryckhomogenitet på en där placerad mätmikrofon, eftersom dess membran är så litet i förhållande till våglängden. Så trots att man inom det s k audioområdet har sämst planvåg vid 20 Hz (det blir bättre och bättre ju högre upp i frekvens man går) så har man bäst tryckhomogenitet för mätmikrofonens membran vid 20 Hz. Tryckhomogenitet beror på många olika faktorer.
5. Du nämner B&K och vad de rekommenderat. Påstår du att det står i motsatsförhållande till det jag skrev (nämligen i princip samma sak) eller varför nämner du det? Jag klargjorde förvisso även att det finns undantag - högtalare så stora att längre mätavstånd definitivt är nödvändiga, men det står ju på inte sätt i motsatsförhållande till B&K’s rekommendation.
Vh, iö
- - - - -
*Och här hoppas jag inte att någon missförstår mig. En högtalare kan definitivt konstrueras för att avlyssnas i diskanthöjd på t ex två meters avstånd, men konsekvensen i normalfallet är då att den behöver avlyssnas från högre höjd än så om man sitter 4 meter från högtalaren om den senare är på så vis konstruerad att den ger en snäv lyssningsvinkel vertikalt.
Senast redigerad av IngOehman 2019-12-04 10:18, redigerad totalt 2 gånger.
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
Av kontexten är det uppenbart och självklart att jansh avser pennhastigheten, vilken medelst lågpassfiltrering medför en glättad kurva. (I Svantes "tombstone" kan man ange glättningen i termer av lågpassfiltrets gränsfrekvens).
Begränsad pennhastighet är inte samma sak som att dess rörelse är LP-filtrerad. Det är normal en olinjär reglering av pennans rörelser. En som motsvarar en slewrate-begränsning, inte en LP-filtrering.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
IngOehman skrev:I de flesta lyssningsrum är de reflekterade ljuden (tillsammans) starkare än direktljudet
Ja, det faktumet ger ännu mer bränsle till mina tankar om att det skulle kunna vara relativt oviktigt hur en högtalares direktljud till lyssnaren låter. Relativt till vad jag har trott tidigare.
Lite humor att du gav mig mothugg i form av medhugg. Eller snarare medhugg i form av mothugg.
rajapruk, lyssnade du på det där testspåret jag knåpade ihop och la upp på föregående sida? Det med det summerade mono-spåret och med eller utan fördröjningar på 1 till 2 ms från en tilltänkt center.
IngOehman skrev:I de flesta lyssningsrum är de reflekterade ljuden (tillsammans) starkare än direktljudet
Ja, det faktumet ger ännu mer bränsle till mina tankar om att det skulle kunna vara relativt oviktigt hur en högtalares direktljud till lyssnaren låter. Relativt till vad jag har trott tidigare.
Lite humor att du gav mig mothugg i form av medhugg. Eller snarare medhugg i form av mothugg.
Har inte mothuggit med avsikt. Håller med dig om flera saker.
Men givet hur debatten sett ut genom åren, har jag alltid tagit ställning mot de vinklingar som funnits. Vinklingarna skapas nästan alltid av trender och trender fördummar typ alltid. Verklighetens fysik och psykoakustik skapas inte av den populäraste synen på det, de är sig själv. De struntar i vad (tokigt) folk just nu råkar tro. Men trender är ”enkla sanningar” (läs lögner) och folk vill ha de enkla svaren.
På 70-talet så tillmättes direktljudet närapå ingen betydelse, så då hävdade jag såklart dess betydelse.
Idag är det reflekterade ljudet näst intill bortglömt, så då hävdar jag såklart dess betydelse för musikåtergivningen, vilket dock är mera komplicerat...
Varför? Jo, för att det beror på så många olika saker, och det reflekterade ljudets inverkan på upplevelsen är därtill beroende på VILKA reflekterade ljud man talar om! Det finns ETT direktljud (well även det en svag förenkling, men den får duga) men det finns inte ett reflekterat ljud - de reflekterade ljuden är legio!
Och beroende på anländandetid, anländande vinkel, klang och diffusitet påverkar de på väldigt olika sätt.
Fast nu känns det som om vi lämnat trådämnet.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
goat76 skrev:rajapruk, lyssnade du på det där testspåret jag knåpade ihop och la upp på föregående sida? Det med det summerade mono-spåret och med eller utan fördröjningar på 1 till 2 ms från en tilltänkt center.
Har du någon kommentar på det?
Jag lyssnade inte på det, för jag kände spontant att inte det testet som det är utformat var relevant eftersom allt summerades i elektroniska domänen till MONO. Det är ju något helt annat. Ingen riktig center, med annan riktning på direktljud etc.
rajapruk skrev:Första millisekunden ger BARA lokalisering? Sätter INGEN klang? Summing-localization ljudet trunkeras helt och hållet från upplevd klang/timbre? Det skulle ju få enorma konsekvenser. Att direktljud bestämmer enbart riktning och att sedan rumsreflexer sätter klangen. Men jag kanske ska sluta dra slutsatser denna morgon. Det skulle väl i så fall kanske kunna förklara varför högtalare i ekofri kammare låter dåligt. Och här sitter jag med riktade högtalare... Har jag just blivit en Carlsson?
Nu verkar det nästan som om du glömmer bort att det är extremt få ljud i musik som är så korta som 1 ms eller mindre. Resten av direktljudet som kommer efter 1ms sätter ju fortfarande den huvudsakliga klangen
rajapruk skrev:Direktljudet kan låta hur fan som helst nästan från en högtalare?? Bara totala energin ut i rummet är rätt så att senare ljud får rätt spektrum totalt?
Det ljud som når lyssnaren till största del är ju direktljudet så det kan ju inte låta hur fan som helst.
rajapruk skrev: Det skulle också kunna betyda att tidiga reflexer (som anländer efter summing-localization) är av godo, om det låter rätt? Det blir liksom ingen kamfiltereffekt/superposition med direktljudet pga att de anländer i olika tid/fas (för att direktljudet är trunkerat)? Det känns inte som det kan stämma? Är det ett paradigmskifte på gång i mitt huvud idag? Tänket "tidiga reflexer är automatiskt dåliga" går bort i så fall.
Tidiga reflexer är alltid skadliga och bidrar endast till att diffusera direktljudet. Kanske kan den tidiga reflexen hjälpa ett ljud på 1ms eller kortare för att vi ska hinna upptäcka det.
rajapruk skrev:För att sluta cirkeln med center-högtalare, så skulle i så fall centern kunna spela L+R summerat, men fördröjt att anlända efter summing localization från L och R? 1ms fördröjd närmare bestämt. Och på så sätt stödja upp stereosystemfelen i ton, och även rumsakustiska problem och placeringsproblem av L och R, klangen blir "perfekt" från centerns direktljud, men inte stör lokaliseringen som är stereokodad från L och Rs direktljud första millisekunden. Då kan man ha 1 superduperklingande center (man kan läsa Bremen 3D8 här om man vill, frivilligt) , och två klangmässigt kassa högtalare på L och R som skickar ut vad fan som helst nästan bara de kan spela lika högt direktljud? Hallelelujah?
Det blir till att gå ner i källaren ikväll och hämta upp en nerpackad JBL LSR305 och testa att sätta den som center, summerad och lite fördröjd. Spännande
Jag gjorde precis ett litet test som visar vad som sker med direktljudet med en centerkanal som summerats till mono, och vad som sker om denna summerade mono-signal fördröjs med 1 ms respektive 2 ms.
I testet så agerar höger högtalare center-kanal och spelar upp den summerade monokanalen och den vänstra kanalen spelar endast upp det ljud från stereospåret som tillhör just vänstra kanalen. Tänk nu som så att höger högtalare är urkopplad och det ljud som i testet nu kommer från den högtalaren är en center-högtalare.
0:00 - 0:10 Ett summerat mono-spår spelas ensamt upp i center-högtalaren (höger högtalare).
0:10 - 0:20 Vänster kanal spelar endast upp vänstra halvan av stereospåret samtidigt som "centern" fortsätter spela det summerade mono-spåret. Nu hör man tydligt en stereomix vars mitt ligger mitt emellan "centern" och vänster högtalare (vilket i detta test är precis i mitten av L och R).
0:20 - 0:30 En 1 ms fördröjning läggs på det summerade monospåret från "centern" vilket ger en ganska diffus ljudbild där det är ganska svårt att peka ut vart ifrån de enskilda ljuden i mixen verkligen kommer ifrån. Det är tydligt hur mycket skada en fördröjning på 1 ms från centern ger och fas-förskjutningen skapar ett väldigt ihåligt och glest ljud.
0:30 - 0:40 Nu ökas fördröjningen till 2 ms och man kan nu höra att musiken får tillbaka lite mer av sin "kropp" och sången har tydligt dragit sig ut någonstans mot vänster högtalare, men fasförskutningen har egentligen bara flyttat på sig och förstärker nu vissa frekvenser något mer godartat för just detta specifika musikstycke. Helheten låter dock fortfarande något ihåligt.
0:40 - 0:54 Här har jag tagit bort fördröjningen och återgått till det som spelades i partiet 0:10 - 0:20 för att återigen visa hur det egentligen ska låta, och varför det är viktigt att den summerade mono-signalen från center-kanalen alltid bör spela tidsmässigt i rätt fas med vänster och höger kanal.
Om man däremot på något trovärdigt sätt kan filtrera fram det som endast ska spelas i centern från ett stereospår, och filtrera bort det samma från vänster och höger kanal så kan man isåfall styra och ställa över både bredd och djup lite som man behagar. Men hur görs då detta på ett lyckat sätt som fungerar bra för de flesta stereo-mixar?
P.S. Jag är medveten om att flera som läser tråden förstår allt detta, men det är alltid kul med lite praktik mitt i allt teori-snack.
Jag har lyssnat på spåret nu och i mina öron mitt system upplevs det inte riktigt som du beskriver Min upplevelse blir att allt efter 20s upplevs komma ur vänster högtalare, Det vrider inte tillbaka någon gång utan något lurar mig
Framtiden är här... men har den blivit som vi önskade den? Läs innan du beaktar Disclaimer-> Viktig information
goat76 skrev:rajapruk, lyssnade du på det där testspåret jag knåpade ihop och la upp på föregående sida? Det med det summerade mono-spåret och med eller utan fördröjningar på 1 till 2 ms från en tilltänkt center.
Har du någon kommentar på det?
Jag lyssnade inte på det, för jag kände spontant att inte det testet som det är utformat var relevant eftersom allt summerades i elektroniska domänen till MONO. Det är ju något helt annat. Ingen riktig center, med annan riktning på direktljud etc.
Det spelar ingen roll hur det summerades till mono, mono är mono.
Testet visar vilka fel du inför om en centerhögtalare spelar precis samma ljud som fronthögtalarna med en fördröjning på 1 ms, vilket du hade teorier om i ditt inlägg här nedanför:
rajapruk skrev:För att sluta cirkeln med center-högtalare, så skulle i så fall centern kunna spela L+R summerat, men fördröjt att anlända efter summing localization från L och R? 1ms fördröjd närmare bestämt. Och på så sätt stödja upp stereosystemfelen i ton, och även rumsakustiska problem och placeringsproblem av L och R, klangen blir "perfekt" från centerns direktljud, men inte stör lokaliseringen som är stereokodad från L och Rs direktljud första millisekunden.
Att lägga en fördröjning av direktljudet från en center som spelar upp samma ljud som frontarna är en riktigt dålig ide p.g.a. de fasfel som då sker. lyssna på spåret så får du höra hur illa det låter med 1 ms fördröjning.
dewpo skrev:Jag har lyssnat på spåret nu och i mina öron mitt system upplevs det inte riktigt som du beskriver Min upplevelse blir att allt efter 20s upplevs komma ur vänster högtalare, Det vrider inte tillbaka någon gång utan något lurar mig
Det kan säkert te sig lite olika i olika lyssningsmiljöer men det huvudsakliga problemet jag ville visa är de uppenbara fasfelen som introduceras. Det hör du väl?
dewpo skrev:Jag har lyssnat på spåret nu och i mina öron mitt system upplevs det inte riktigt som du beskriver Min upplevelse blir att allt efter 20s upplevs komma ur vänster högtalare, Det vrider inte tillbaka någon gång utan något lurar mig
Det kan säkert te sig lite olika i olika lyssningsmiljöer men det huvudsakliga problemet jag ville visa är de uppenbara fasfelen som introduceras. Det hör du väl?
Nu har jag lyssnat noggrannare, Det vrider tillbaka på slutet Från 22s så låter det som ljudet kommer från vänster högtalare ljudet från höger maskeras på något sätt. Klangen är ihålig på 1ms paritet, Kanske upplevs den som lite renare i 2ms området men inte mycket.
Jag tror att olika personer upplever effekten olika. För mig är effekten av att ljudet som kommer först maskerar det senare kommande ljudet mest påtaglig redan på 1ms.
Hur lång fördröjning krävs innan man upplever det som ett eko?
Framtiden är här... men har den blivit som vi önskade den? Läs innan du beaktar Disclaimer-> Viktig information
Ett helt identiskt ljud kommer aldrig att upplevas som ett fullt övertygande eko, det gör bara ljudet mer diffust p.g.a fasförskjutningen tills fördröjningen till slut är tillräckligt lång så att man istället uppfattar det som två enskilda ljud i följd, om än identiska.
IngOehman skrev:1. ”Flervägare” är ett diffust begrepp, som i sig inte säger särskilt mycket om hur stor ljudkällan är. De flesta högtalare som existerar är små, så små att 1 meter är ett tillräckligt avstånd för att man skall hamna i högtalarens fjärrfält. Men du såg väl att jag också talade om att större högtalare kan kräva mätavstånd på över 3 meter?
Jag menar just "flervägare" till skillnad från mätning på högtalare med ett element. Det är visserligen generalisering och det finns alltså då undantag. ville inte använda begreppet "flera ljudkällor" då det inte blir korrekt eller kan misstolkas. Jag tycker begreppet "flervägare" är i sammanhanget bra, om dock generaliserande. Ungefär som dina begrepp "de flesta högtalare" och "riktigt stora högtalare" som jag tolkar efter bästa förmåga (jag vet att du brukar säga att man ska läsa vad som står,inte tolka).
2. Att mäta på diskantens nollaxel ger alltid geometrisk distorsion! (Diskanten blir proportionellt närmare på kortare mätavstånd) Jag tolkar det du skriver som att du är medveten om detta problem. Det blir definitivt märkbart när man rör sig från en till två meters mätavstånd. Högtalartillverkare som definierar detta som lyssningsaxeln tycks mig inte ha tänkt igenom saken särdeles väl (om inte högtalaren är vertikalsymmetrisk). Så är de också påfallande ofta omedvetna om att det i princip dikterar ett fast lyssningsavstånd*.
Japp, konsekvenserna är påtagliga. Dock, man får lättare att "fixa till" en bra kurva i övre diskanten på de flesta högtalare och har man tur blir resten också OK. Det du nämner om geometrisk dist är ett alldeles utmärkt skäl till att öka mätavståndet så att mätkurvan bättre rimmar med normalt lyssningsavstånd.
3. Lägre skrivarhastighet och smothing är två olika saker. Lägre skrivarhastighet är därtill inte ett entydigt begrepp och ger i sin vanligare betydelse (”pappershastighet”) dessutom en mera högupplöst mätning. Kanske är det lägre ”pennhastighet” du talar om? Jag gissar det. Det är hur som helst inte heller samma sak som smothing. I synnerhet inte när man talar om mätningar i icke-ekofria rum.
Nja, målet har väl alltid varit att jämna till kurvan (antingen för att öka tydligheten (!) eller för att lura konsumenten). Skrivhastighet, som jag skrev inte skrivarhastighet, var en taskig (?) översättning av "writing speed" till skillnad från "paperspeed". 2 välkända begrepp innan digitalisering skedde. Måste varit mycket välkända begrepp för t.ex Stig Carlsson som använde B&K utrustning, t.ex skrivaren B&K2305. I ärlighetens namn, jag vet inte hur "smothing" sker digitalt - måste läsa på..... jag vet hur "writing speed" och "paperspeed" funkar i B&K2305.
4. Du skriver lite om planvågsförhållanden, och du har både fel och rätt... Du har rätt i att membranet behöver tryckutsättas homogent. Men du har inte rätt i att det kräver planvågsförhållanden. Vid 20 Hz har man inte planvågsförhållande från någon högtalare, ens på lyssningsplats! Men ändå har man mycket hög tryckhomogenitet på en där placerad mätmikrofon, eftersom dess membran är så litet i förhållande till våglängden. Så trots att man inom det s k audioområdet har sämst planvåg vid 20 Hz (det blir bättre och bättre ju högre upp i frekvens man går) så har man bäst tryckhomogenitet för mätmikrofonens membran vid 20 Hz. Tryckhomogenitet beror på många olika faktorer.
Det var därför jag frågade om "planvåg" i din begreppsvärd är samma sak som plan vågfront och relaterade till mikrofonmembranet. Att uppnå en rimligt plan vågfront för ett membran som är 6,35 eller 12,7 mm i diameter är ju inte svårt men den lilla ytan skall ju representera vågfronten som sådan om man ska ha någon nytta av mätningen
5. Du nämner B&K och vad de rekommenderat. Påstår du att det står i motsatsförhållande till det jag skrev (nämligen i princip samma sak) eller varför nämner du det? Jag klargjorde förvisso även att det finns undantag - högtalare så stora att längre mätavstånd definitivt är nödvändiga, men det står ju på inte sätt i motsatsförhållande till B&K’s rekommendation.
Ville bara påpeka att B&K:s mätnigar/slutsatser (finns beskrivet in någon B&K Technical Review) att det gällde mätningar på enskilda högtalarelement. Problembilden blir större och kräver större avstånd vid "flervägare" (eller dimension som påverkar). Javisst! generalisering, tolka efter bästa förmåga
Vh, iö
- - - - -
*Och här hoppas jag inte att någon missförstår mig. En högtalare kan definitivt konstrueras för att avlyssnas i diskanthöjd på t ex två meters avstånd, men konsekvensen i normalfallet är då att den behöver avlyssnas från högre höjd än så om man sitter 4 meter från högtalaren om den senare är på så vis konstruerad att den ger en snäv lyssningsvinkel vertikalt.
Mitt mål med att uppmana till att använda längre mätavstånd är bara att längre avstånd ger generellt båttre/korrektare mätresultat. Tyvärr blir det också svårare för gemene man att mäta , b.la. problematiskare gating
När jag läser alla inlägg gjorda av förståsigpåare i tråden så undrar jag om de nästan allihopa har rökt på?
Maken till dumheter, missförstånd och allt sen presenterat i lärarens kostym, har jag sällan skådat! Vad är det frågan om???
Varför inte ställa frågor när man inte vet, vad hände med det? Det kusliga är ju att det finns massa människor som vet lika lite (men vet det) som luras av alla självsäkra inlägg fulla av nonsens!
Obs: Detta inlägg är inte riktat mot någon specifik person, utan adresserar många olika inlägg.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
PS. Det gör dock tråden på många sätt intressant. Tummen upp till Rajapruk som startade den, med en fantastiskt enkel fråga, som i alla sin enkelhet fått okunskaper att flöda från många som svarat! Fascinerande.
Jag skriver detta med förhoppningen att ingen av dem som skrivit klokheter skall ta åt sig. Men jag vill inte peka finger, därav de svepande beskrivningarna av vad jag sett i tråden.
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
Det KAN vara bäst att göra egna experiment, men att påstå att det måste vara så är definitivt en osanning. Massor av människor som experimenterat, har dragit heltokiga slutsatser. Att jorden är platt t ex.
Så att ha bra lärare är inte dumt heller. Och hur identifierar eleven (som saknar kunskaper) en bra lärare?
Enkelt - en god lärare vill inte bli trodd utan lyssnad på. En bra lärare vill att eleven skall vänta med att tro saker tills alla mynt trillat ned. Inte tro utan förstå.
Talar då inte om ämnen som historia och geografi (kunskapsämnen) utan om förståndsämnena - sådana som går ut på att lära sig att förstå samband, att se hur saker häng ihop och varför. Ämnen som hanteras via vetenskapligt tänk.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
För mig är trådens ämne nu istället av få höra Peter Steindls tankar om alla dessa frågor:
rajapruk skrev:Aaah, skönt då hade jag bara en kort temporär morgonförvirring. Tror jag hängde upp mig på trunkerings-begreppet felaktigt.
Första millisekunden ger BARA lokalisering? Sätter INGEN klang? Summing-localization ljudet trunkeras helt och hållet från upplevd klang/timbre? Det skulle ju få enorma konsekvenser. Att direktljud bestämmer enbart riktning och att sedan rumsreflexer sätter klangen. Men jag kanske ska sluta dra slutsatser denna morgon. Det skulle väl i så fall kanske kunna förklara varför högtalare i ekofri kammare låter dåligt. Och här sitter jag med riktade högtalare... Har jag just blivit en Carlsson?
Direktljudet kan låta hur fan som helst nästan från en högtalare?? Bara totala energin ut i rummet är rätt så att senare ljud får rätt spektrum totalt?
Det skulle också kunna betyda att tidiga reflexer (som anländer efter summing-localization) är av godo, om det låter rätt? Det blir liksom ingen kamfiltereffekt/superposition med direktljudet pga att de anländer i olika tid/fas (för att direktljudet är trunkerat)? Det känns inte som det kan stämma? Är det ett paradigmskifte på gång i mitt huvud idag? Tänket "tidiga reflexer är automatiskt dåliga" går bort i så fall.
För att sluta cirkeln med center-högtalare, så skulle i så fall centern kunna spela L+R summerat, men fördröjt att anlända efter summing localization från L och R? 1ms fördröjd närmare bestämt. Och på så sätt stödja upp stereosystemfelen i ton, och även rumsakustiska problem och placeringsproblem av L och R, klangen blir "perfekt" från centerns direktljud, men inte stör lokaliseringen som är stereokodad från L och Rs direktljud första millisekunden. Då kan man ha 1 superduperklingande center (man kan läsa Bremen 3D8 här om man vill, frivilligt) , och två klangmässigt kassa högtalare på L och R som skickar ut vad fan som helst nästan bara de kan spela lika högt direktljud? Hallelelujah? Typ sätta in en bra center i JMs laserspridande system och det låter plötsligt bra och han kan slänga skruvstädet till huvudet? (skämt)
Fan det här får stora konceptuella konsekvenser för mig. Nästan så jag hoppas att jag missuppfattat. Konsekvenser för delning mellan element. Konsekvenser för placering av basar. Konsekvenser för akustikbehandling (dämpning är ofta dåligt då). Placering av högtalare. Hur en högtalare bör sprida. Hur man får en stor sweetspot. ALLT... Även om det kanske inte blir jättestora ändringar i praktiken av det. Jag har varit helt inriktad på att få till direktljudet "perfekt" (något jag då kanske knappt aldrig ens har hört klangen av), och sen minimera och senarelägga "tidiga" reflexer. Jag måste mäta på ett helt annat sätt i så fall.
Det blir till att gå ner i källaren ikväll och hämta upp en nerpackad JBL LSR305 och testa att sätta den som center, summerad och lite fördröjd. Spännande
rajapruk skrev:Trådens ursprungliga ämne/fråga löstes ju tidigt.
Gjorde den? Det såg jag inte.
rajapruk skrev:För mig är trådens ämne nu istället av få höra Peter Steindls tankar om alla dessa frågor:
rajapruk skrev:Aaah, skönt då hade jag bara en kort temporär morgonförvirring. Tror jag hängde upp mig på trunkerings-begreppet felaktigt.
Första millisekunden ger BARA lokalisering? Sätter INGEN klang? Summing-localization ljudet trunkeras helt och hållet från upplevd klang/timbre? Det skulle ju få enorma konsekvenser. Att direktljud bestämmer enbart riktning och att sedan rumsreflexer sätter klangen. Men jag kanske ska sluta dra slutsatser denna morgon. Det skulle väl i så fall kanske kunna förklara varför högtalare i ekofri kammare låter dåligt. Och här sitter jag med riktade högtalare... Har jag just blivit en Carlsson?
Direktljudet kan låta hur fan som helst nästan från en högtalare?? Bara totala energin ut i rummet är rätt så att senare ljud får rätt spektrum totalt?
Det skulle också kunna betyda att tidiga reflexer (som anländer efter summing-localization) är av godo, om det låter rätt? Det blir liksom ingen kamfiltereffekt/superposition med direktljudet pga att de anländer i olika tid/fas (för att direktljudet är trunkerat)? Det känns inte som det kan stämma? Är det ett paradigmskifte på gång i mitt huvud idag? Tänket "tidiga reflexer är automatiskt dåliga" går bort i så fall.
För att sluta cirkeln med center-högtalare, så skulle i så fall centern kunna spela L+R summerat, men fördröjt att anlända efter summing localization från L och R? 1ms fördröjd närmare bestämt. Och på så sätt stödja upp stereosystemfelen i ton, och även rumsakustiska problem och placeringsproblem av L och R, klangen blir "perfekt" från centerns direktljud, men inte stör lokaliseringen som är stereokodad från L och Rs direktljud första millisekunden. Då kan man ha 1 superduperklingande center (man kan läsa Bremen 3D8 här om man vill, frivilligt) , och två klangmässigt kassa högtalare på L och R som skickar ut vad fan som helst nästan bara de kan spela lika högt direktljud? Hallelelujah? Typ sätta in en bra center i JMs laserspridande system och det låter plötsligt bra och han kan slänga skruvstädet till huvudet? (skämt)
Fan det här får stora konceptuella konsekvenser för mig. Nästan så jag hoppas att jag missuppfattat. Konsekvenser för delning mellan element. Konsekvenser för placering av basar. Konsekvenser för akustikbehandling (dämpning är ofta dåligt då). Placering av högtalare. Hur en högtalare bör sprida. Hur man får en stor sweetspot. ALLT... Även om det kanske inte blir jättestora ändringar i praktiken av det. Jag har varit helt inriktad på att få till direktljudet "perfekt" (något jag då kanske knappt aldrig ens har hört klangen av), och sen minimera och senarelägga "tidiga" reflexer. Jag måste mäta på ett helt annat sätt i så fall.
Det blir till att gå ner i källaren ikväll och hämta upp en nerpackad JBL LSR305 och testa att sätta den som center, summerad och lite fördröjd. Spännande
Jag är inte Peter, men jag kan kommentera det du skriver ändå, kanske?
Direktljudet har stor betydelse, ibland. Det beror lite på uppspelningsfilosofi/lyssningsmiljö (saker som förhoppningsvis hör ihop).
Men även när filosofin inte i hög grad värderar direktljudet så KAN det ha stor påverkan på upplevda resultatet - genom att vara starkt och dåligt (färgat). Däremot kan man bygga högtalare med nästan obefintligt direktljud, som ändå kan upplevas i varje fall trevligt av många lyssnare.
Å andra sidan... Med högtalare utan direktljud hör man som primärt anländande ljud den först anlända spegelbilden av högtalarna, och den tar då nästan rollen som direktljud.
Egenskaper som är karakteristiska med sådana lyssningar är att man får ett kolossalt lyssningsavstånd och en ganska diffus ljudbild, som dock kan kännas igen från många ”dåliga” live-situationer.
Utan att det ger en uppställning helt fri från direktljud kan ett intressant experiment för många (som lyssnar i ett vanligt odämpat vardagsrum) vara att ställa högtalarna någon meter från väggen bakom dem - och sen vända högtalarna bort från lyssnarna. Många blir förvånade av resultatet. Speciellt de som tror att man i normalfallet primärt hör direktljud...
Vh, iö
- - - - -
PS. I en akustiskt välkonstruerad hemmabio är skillnaden (för en mittplacerad lyssnare) minimal mellan att ha en centerhögtalare och att inte ha det, förutsatt att den är av hög kvalitet och är avdelad nedåt vid en tillräckligt hög frekvens (således att dess låga register fantomprojiceras).
För sidoplacerade lyssnare är skillnaden dock betydligt större. Och till nackdel vid spelning av musik utan bild (!), men till fördel vid spelning av programmaterial där ljudet har en ackompagnerande bild.
Senast redigerad av IngOehman 2019-12-04 16:53, redigerad totalt 1 gång.
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
Ja, och tar man bort det framåtriktade elementet (i ett normalt vardagsrum) så märks det knappt alls.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
dewpo skrev:Jag har lyssnat på spåret nu och i mina öron mitt system upplevs det inte riktigt som du beskriver Min upplevelse blir att allt efter 20s upplevs komma ur vänster högtalare, Det vrider inte tillbaka någon gång utan något lurar mig
Det kan säkert te sig lite olika i olika lyssningsmiljöer men det huvudsakliga problemet jag ville visa är de uppenbara fasfelen som introduceras. Det hör du väl?
Nu har jag lyssnat noggrannare, Det vrider tillbaka på slutet Från 22s så låter det som ljudet kommer från vänster högtalare ljudet från höger maskeras på något sätt. Klangen är ihålig på 1ms paritet, Kanske upplevs den som lite renare i 2ms området men inte mycket.
Jag tror att olika personer upplever effekten olika. För mig är effekten av att ljudet som kommer först maskerar det senare kommande ljudet mest påtaglig redan på 1ms.
Hur lång fördröjning krävs innan man upplever det som ett eko?
Gjorde precis en upptäckt.
Tidigare i tråden hade jag fel då jag hade teorin att man kanske skulle behöva fördröja en center som spelar ett summerat mono-spår av det vänster och höger kanal spelar, för att matcha frontarnas fysiska avstånd. Den teorin stämmer inte alls, ljudet bör i princip aldrig fördröjas i centern i något läge alls ifall man vill undvika att det uppstår fasförskjutningar som i sin tur diffuserar helhetsljudet. Ljud-reflexerna har precis som herr Öhman säger nästan alltid en större inverkan på helhetsljudet jämnfört med direktljudet och reflexerna påverkas självklart även de vid en fördröjning, därmed kommer en fördröjning av direktljudet från en center i alla lägen medföra en mer eller mindre destruktiv fas-förskjutning för helhets-ljudet.
Pudelns kärna för mig är gällande den mänskliga hörseln, hur den processar inkommande ljud.
Sätter första 1ms ungefär ENBART lokaliseringen och INGENTING annat? Trunkeras sedan denna första 1ms HELT bort av hörseln och används inte för att bestämma klang med mera ALLS i den fortsatta processingen?
De som anser sig veta svaret på detta, svara gärna först: JA eller NEJ. Och sedan en utläggning om så önskas.
Jag är mycket tacksam för alla svar jag får.
Om svaret beror på om det är ljud som är steady-state eller transient, så svara för transient. Om svaret beror på frekvensregister, så svara för högre register snarare än låga basregister.
Om svaret är JA får det stora konsekvenser för hur jag ser på ljudåtergivning i allmänhet.
Sen har jag massor med följdfrågor, om svaret är JA.
Senast redigerad av rajapruk 2019-12-05 01:59, redigerad totalt 5 gånger.
rajapruk skrev:Lokalisering / precedence-effekt fungerar väl olika också beroende på om det är höga eller låga frekvenser det handlar om, samt om ljudet som skall lokaliseras är steady-state eller transient?
Personen som har världens bredaste huvud kanske har 2ms ”summing-localization”?
Jag svarar lite kort på ditt inlägg. Du frågar om lokalisering / precedence-effekt.
Jag svarar gällande Summing-localization-området. Man förutsätter 2 öron med separata öronsignaler, en för höger öra, en för vänster öra. Dessa 2 signaler skall på ett synnerligen fiffigt sätt summeras till en och endast en signal. Denna summationsprocess kallas summing localization. Det är en summation som sker i hjärnan under en viss tidsperiod och tidsperioden för summationen i hjärnan kan maximalt vara 1 ms och kan aldrig vara längre tid än så för då funkar inte systemet d v s nervsystemet i denna process. Detta är oberoende av steady state eller transient insignal och även elefanter med mycket större bredd mellan öronen har denna maximala 1 ms. Det finns ett skäl för detta som jag återkommer till vid tillfälle.
Så, det finns en process i hjärnan som kallas summing localization. Den processen kan enkom vara i maximalt 1 ms. Sedan träder andra processer i kraft i hjärnan. De andra processerna kallas olika saker. En av dessa processer kallas precedence. Men det finns många fler parallellprocesser, och speciellt kognitiva, efter det att processen summing localization skett.
Summing-localization-intervallet är lika för låga frekvenser d v s djup bas som för mellanfrekvenser d v s mellanregister som för höga frekvenser d v s diskant. Det betyder dock inte att summing localization lyckas lika bra/effektivt för låga frekvenser som för mellanfrekvenser eller höga frekvenser. Det betyder heller inte att summing localization lyckas lika för steady state som för transient insignal. Men 1 ms är alltid den maximala tiden för summing localization och det beror på nervsystemets uppbyggnad och funktion.
Så, nu kommer vi till avdelningen direktljud. Det är det ljud som är kortaste vägen från ljudkälla till ljudmottagare. Den följer tryckgradienten från ljudkälla till ljudmottagare. Det är en vektor i ett vektorfält. En vektor har en riktning och en skalär magnitud. Vektorn d v s tryckgradienten i en specifik riktning uppstår på grund av tryckskillnad i rummet i den riktningen och är en rumsderivata, d v s skillnad i tryck i rummet på grund av den propagerande ljudvågen. Vektorn i detta fall är på linjen från ljudkälla till ljudmottagare och är normalen mot tryckgradienten längs med denna linje.
Den skalära magnituden av vektorn varierar i tiden och är således en tidsderivata. OBS! Förväxla aldrig rumsderivata med tidsderivata! För att få fram tidsderivata och i samband med fourieranalys d v s att gå in i frekvensdomänen och åskådliggöra frekvensgång kräver en tidsfönstring som tillämpas. Fönstringen kan göras olika lång. Ju längre tidsfönster desto längre ned i frekvens kan frekvensgången korrekt åskådliggöras. Problemet är att då kommer reflexer in från olika håll som inte hör hemma i direktljudet. Enda chansen är då att mäta i exempelvis en gymnastiklokal med stora avstånd till närmaste väggar, tak och golv.
Så, nu har vi tittat lite på direktljudet i den fysikaliska världen. Hörseln lokaliserar direktljudets riktning för att lokalisera ljudkällor. Bra funktion! Det betyder i klartext att hörseln har förmågan att urskilja tryckgradient och den processen tar som sagt 1 ms i anspråk i hjärnan och begränsas i tid av nervsystemets funktionalitet. Denna process har en mycket viktig funktion och det handlar inte om barnsagor om att tigrar och lejon sitter runt hörnet för att jaga människorna för ett skrovmål längs med evolutionens fortskridande mot högre höjder med förfinad hörsel. Det handlar om att hörseln är intimt kopplad till vårt inre koordinatsystem som finns i respektive inneröra och systemet kallas Vestibular system med 3 st. Semicircular Canals (eller Ducts), samt två andra kammare, som kallas för sacculus och utriculus. Huvudets läge registreras i dessa 2 kammare. Det finns som sagt 3 stycken Canals per öra och tillsammans sätter de vårt inre koordinatsystem som är helt essentiellt för vårt balanssinne och rumsliga orientering, ja det utgör helt sonika vårt balanssinne. Det systemet triggar på acceleration. Exempel; sitter man helt stilla i en hiss som är mörk så man inte ser något så känner man ändå att hissen börja röra sig, antingen uppåt eller neråt och även då hissen stannar in. Rör man på huvudet i förhållande till kroppen så är nackens muskler och leder rikligt försedda med känselkroppar s.k. proprioceptorer. Dessa receptorer känner av musklernas spänning och ledernas läge. Proprioceptionen är led- och muskelsinnet, som informerar centrala nervsystemet om lemmarnas inbördes positioner och rörelser. Av alla muskler i kroppen är de djupa musklerna kring nackryggraden de som har den högsta tätheten av muskelsinnesreceptorer. informationen från nackens led- och muskelsinne behövs för att ge referenssignaler till balanssinnet om huvudets läge i förhållande till bålen. Denna information är nödvändig för att balansreflexerna från balansorganen i inneröronen ska fungera perfekt.
Det är alltså vårt totala balanssinne det handlar om och att kunna förflytta sig i det euklidiska rummet d v s i omgivningen utan att konstant behöva spy på grund av yrsel och sjösjuka. Sedan är det ihopkopplat med synen, annars skulle snabba ögonrörelser fara än hit och än dit, så kallade vestibulo-ocular reflex. Hörselns och synens koordinatsystem och synens förmåga att mäta upp den yttre världen för lokalisering av sig själv i förhållande till omgivningen är hörnstenar i balanssinnet. Det är ett synnerligen motkopplat system mellan hörsel och syn och till och med push-pull kopplat. Höger vestibularsystem är kopplat till både höger och vänster öga och så är även vänster vestibularsystem. Dessutom är höger och vänster vestibularsystem differenskopplade. Diskrepans mellan systemen och mellan hörsel och syn skapar yrsel och är en mycket allvarlig åkomma. Vestibularsystemet är en hel värld i sig som kan studeras. Jag har läst lite grand för att ha den kunskapen som grund i en större förståelse om människans natur. Jag länkar först till 3 korta videos och därefter till en längre.
Nästa är väldigt rolig rätt bra och rekommenderas att titta på. Han är inte helt född i farstun. Det som jag dock inte sett någonstans tidigare är hans info om längden på hörseltrådarna utmed basilarmembranet. Det är en info som jag gärna vill kolla upp om det stämmer. Däremot finns mycket info om själva basilarmembranets utformning som gör att resonans vid olika frekvenser sker på olika ställen längs med basilarmembranet som ger hörseln egenskapen att vara tonotopiskt organiserad. Detta är en annan synnerligen väsentlig egenskap hos hörseln.
Se även denna:
Den här är väsentlig för ökad förståelse över vad som händer i just de inre hårcellerna som ger receptor potentialer som efter synaps ger upphov till aktionspotentialer i nervsystemet. Det kan vara bra att tagit del av dessa videos då man går vidare i nervsystemet för att sedan kunna förstå den där gäckande millisekunden.
Det är intressant att se att dessa ungdomar faktiskt gillar det dom föreläser om och det ser jag som mycket positivt och lovande inför framtidens entreprenörer inom ljud måhända.
För att fortsätta, om alla ljudkällor i världen helt sonika skulle upplevas som varandes totalt diffusa så uppstår stora problem. Ja, jag vet, det är förenklat. Det är dessutom total överkurs i sammanhanget, men det kan vara värt att ha lite hum om vårt inre koordinatsystem.
Ett exempel, visserligen på ett helt annat specifikt problem, är att då man landar med flygplan och inte tryckutjämnar trycket som uppstår i mellanörat så blir allt ljud väldigt dovt och diffust. Om man skulle fastna i det läget så skulle det innebära extrema problem med hörsel och förmodligen med hela balanssinnet eftersom de är sammankopplade via membran i innerörat mellan båda dessa system. Tryckutjämningen sker i mellanörat. Mellanörat har funktion av impedansanpassning mellan trumhinna och innerörat.
Vill man förkovra sig i balanssinnet och i vestibular systemet, så läser man lämpliga böcker inom området. Jag har läst lite av nyfikenhet och för att kunna ha som grund i förståelse gällande ljud och vår uppfattning om ljud i vår kommunikation med omvärlden.
De tre Semicircular Canals i vestibularsystemet är, Horizontal semicircular Canal, Superior semicircular Canal och Posterior semicircular Canal. De är i stort set ortogonala mot varandra och kan sägas representera huvudrörelser i ett rätvinkligt koordinatsystem där koordinatsystemet vi orienterar oss i kallas för det Kartesiska koordinatsystemet med ortogonala axlar x,y,z. Det är detta koordinatsystem man använder inom vektoranalysen och inom matematik och algebra. Så, nu är lite fler saker ihopkopplade för förståelse av människans natur och av ljud. Koordinatsystemet inuti människan sammanfaller med koordinatsystemet man använder i den fysikaliska världen.
Tidigare har jag enkom fokuserat på just funktionen riktningshörande som är en slags tracing av ljudkälla d v s spårande av ljudkälla i ett kartesiskt koordinatsystem i det Euklidiska rummet och det är att betraktas som ett mätförfarande av direktljudets tryckgradient d v s rumsderivata, som människan har till sitt förfogande alldeles gratis.
Vad sedan gäller direktljudets skalära magnitud är en helt annan femma och är än så länge inte intressant i diskussionen som handlar om direktljudets riktning och vår uppfattning därom och hur denna uppfattning därom uppstår.
Skilj på riktning, d v s VARIFRÅN (tryckgradientens normal som först når lyssnaren som beror på tryckskillnaden i rum på grund av ljudvågens propagerande karaktär) och på magnitudförändring i tid som är = VAD = klang/timbre/ljudstyrka/dynamik och annat. De sätts genom skilda processer i nervsystemet varav VAR kommer först i ordningen och tar 1 ms i anspråk.
OBS! De interna processerna d v s i vårt centrala nervsystem och hjärna fortgår tills den slutgiltiga processen tar vid, nämligen den process som innebär varseblivet medvetet ljud. Alla processer sammanlagt kallas perception och där ingår allt från att ljudvågor når vår kropp och ytteröron och örongång och mellanöra och inneröra till hårcellerna som är kopplade till nervsystemet och dess processer.
Allt detta tillhör processen perception av akustiska ljudvågor, vare sig det är direktljud eller första reflexer eller efterklang. Den slutgiltiga destinationen som innebär varseblivet medvetet ljud kallas ofta sensation på engelska. Sensing i de sensoriska systemen går mot sensation. Det sensoriska systemets uppgift är att servera en sensation. Jag vill påpeka att det inom litteraturen gällande medvetandeforskning inte gäller konsensus över vilka ord som används för respektive sak gällande alla dessa processer och det är inte helt entydigt och kan troligtvis inte heller bli så länge som man fortfarande med ljus och lykta söker efter medvetandet, varseblivningen och vad liv är. Jag vill dock påstå att området gällande artificial intelligence AI samt området gällande robotar kommer ett steg närmare roten, men kan inte nå ända fram till roten enligt mitt förmenande. Då krävs ytterligare ett stort förståelseområde som jag inte går in på här.
Så, hur lång tid varar direktljudet?
Direktljudet varar så länge som ljudkällor vibrerar d v s ger ifrån sig ljud och frambringar akustiska ljudvågor i luft som fortskrider i form av tryckgradienter och det finns en ljudmottagare som mottager denna tryckgradient.
I klartext, sitter du i konserthuset på exempelvis parkett och musikerna framför Beethovens 5e symfoni som exempelvis varar i 33 minuter och 12 sekunder så kommer du att nås av direktljud från respektive musikers instrument i 33 minuter och 12 sekunder. Punkt. Det är inte 1 ms eller 2 ms, som det ibland står.
Man måste sära på begreppen om man skall kunna begripa essensen av direktljud och dess funktion. Dessutom är det så att även akustiska ljudvågor från låga frekvenser hos kontrabasar ger upphov till direktljud. 1 våglängd av 100 Hz = 10 ms. Skulle det då inte finnas direktljud vid 100 Hz? Det är ju totalnonsens att direktljudets varaktighet endast skulle vara 1-2 ms som skulle innebära att tidsfönstret är alldeles för kort till att registrera undre mellanregister och bas hos direktljudet. Man kan med viss noggrannhet kanske mäta ner till ungefär 1500 Hz med en fönstring på 1 ms. 1 kHz har våglängden 1 ms. Tror ni verkligen att det inte existerar direktljud under 1500 Hz? Eller tror ni att det är betydelselöst?
En annan sak, tänk dig att du befinner dig i ett tämligen perfekt ekofritt rum. Nu har du ett litet bredbandselement som det kommer musik ur i exakt 5 minuter och 3 sekunder. Om det nu vore så att direktljudet enkom existerar i 1-2 ms och det i det ekofria rummet inte finns reflexer så är det entydigt så att musiken skulle tystna efter 1-2 ms även om det kommer musik ur högtalarelementet. Tror ni som skriver i tråden och läser att musik under övrig tid är någon slags ickedirektljud? Eller precedenceljud eller ekoljud eller vad då? Eller tror ni verkligen att det skulle vara tyst efter 2 ms? Jag sätter en slant på att man kommer höra musik i exakt 5 minuter och 3 sekunder och allt är direktljud.
Dessutom är jag helt övertygad om att man kommer kunna lokalisera ljudkällan och detta under hela denna tid d v s under 5 minuter och 3 sekunder. Och det är längre tid än dessa 1-2 ms som det skrivs. 1 kHz har våglängden 1 ms. Ni kanske menar att man inte kan höra under 1 kHz från högtalaren? Att allt under 1 kHz inte skulle kunna tillhöra direktljudet?
Däremot är det så att processtiden i hjärnan gällande lokalisation är maximerat till 1 ms och detta gäller även frekvenser under 1500 Hz. Denna process sker på ett mycket speciellt och finurligt sätt. Återkommer om det.
Så, då har vi förhoppningsvis kommit en bit på väg.
Då måste vi ta med en sak i beräkningen, nämligen, påverkar ljudets initiala förlopp d v s onset vid varje transient hörselns möjlighet eller effektivitet till detektion av riktning d v s lokalisation. I princip inte så mycket vid lyssning på en reell ljudkälla d v s t.ex. en trumpet eller en och endast en högtalare. Men, vid fantomprojektion av ljudobjekt vid stereofonisk och binaural lyssning d v s uppspelning med 2 eller fler högtalare och lyssning med 2 intakta öron kan det vara helt avförande för hörselns lokalisationförmåga av fantomprojicerade ljudobjekt i ljudbilden. Det är därför jag pratar om koden vid inspelning samt hur koden förmedlas eller kodas ytterligare via högtalare. Det gäller för högtalarna att få till sådan kod som hörseln känner igen och enkelt kan snappa upp för att dechiffrera koden i en avkodningsprocess i nervsystem och hjärna. Då påverkar, tidsfel, fasfel, amplitudfel i direktljudet från respektive högtalare denna process. Då kan man som högtalartillverkare göra en serie mätningar som faktiskt kan vara olika utförda i olika frekvensområden och ha underlag vid dimensionering av högtalarna så att hörselns lokaliseringsprocess underlättas och effektiviseras. Istället för att köra all mat och dryck till middagen i en blender innan det serveras så kan man servera maten smakligt på en tallrik och drycken i ett glas.
Vad gäller trunkering så är det detta jag tidigare skrivit:
petersteindl skrev:. . . . Byter man ut 2 högtalare mot en enda högtalare eller en godtycklig ljudkälla så är resultatet lika d v s du kan rotera ditt huvud och fortfarande peka mot ljudkällan medans du vrider huvudet. Ditt pekande kommer dock vara konstant mot ljudkällan, men din verbala beskrivning av ljudkällans placering kommer variera beroende på ditt huvuds rotation. I ett fall säger du rakt framifrån i ett annat fall rakt bakifrån och i ett tredje fall rakt från höger osv. Det beror på att ditt eget koordinatsystem gällande ljudets perception/sensation ändras med ditt huvuds rotation där noll grader alltid är näsans riktning. MEN DIREKTLJUDETS VEKTOR ÄR ÄNDOCK HELT OFÖRÄNDRAD!! I klartext, beroende på ditt huvuds rotationsläge då du roterar huvudet så kommer delay tiden eller snarast differenstiden mellan öronen ITD att variera utan att direktljudets vektor ändras. Det beror på ditt eget koordinatsystems förankring och rotation kring sin axel. Dessutom är det så att din klangupplevelse av ljudkällan i princip kommer vara rätt så lika oberoende av ditt huvuds rotation inom vissa gränser. Men den spektrala tonkurvan kommer variera med kanske 20 dB på respektive trumhinna då du vrider huvudet lite. Det är nämligen så att den spektrala tonkurvan på respektive trumhinna också motsvarar en given riktning och inte en klangfärg hos ljudkällan. Ljudkällan förändras inte och inte dess läge. Klangen förändras minimalt. Men den spektrala tonkurvan vid respektive trumhinna varierar enormt. Det är således inte den spektrala tonkurva som finns på dina respektive trumhinnor du hör som klang. En stor del av den spektrala tonkurvan är riktningsbestämmande kod som varierar då du roterar huvudet. Efter riktningsbestämmandet "trunkeras" denna kod, den har gjort sitt, så att klangupplevelsen inte skall variera på grund av denna kod. Det gäller inom viss gräns. Även detta har jag tidigare kommit in på.
Först visade jag en bild med 2 högtalare- Sedan sökte jag förklara vad som händer då man lyssnar på reella ljudkällor istället för lyssning resulterande i fantomprojicerade ljudobjekt. Som du kan läsa så är det den riktningsbestämmande delen av den spektrala koden vid respektive trumhinna som kallas HRTF och bidrar till riktningsbestämmande. Gör koden det korrekt, så har den gjort sitt. Lyckas den inte göra det, så blir ljudet färgat utav koden. Mitt citat gäller reella ljudkällor, såsom exempelvis akustiska instrument eller vid lyssning på mono i en högtalare och inte fantomprojicerade ljudkällor i ett stereofoniskt system.
Slutligen, allt som det spekuleras i gällande hur jag använder centerhögtalare i ett stereofoniskt system är inkorrekt, inte ens i närheten av att vara korrekt. Spekulationer både från dig och alla andra i denna tråd gällande min koppling med centerhögtalare har inget att göra med mitt system.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
Peter vad vill du förmedla? För mig är inlägget bara förvirrande. Jag skulle uppskatta om du fokuserade på kärnbudskapet. Blanda inte in oväsentligheter. Inlägget blir inte bättre genom att blanda in fragment av begrepp som är oväsentliga. Då hörandet är komplicerat är det viktigt som jag ser det att belysa ett område i taget. Hörandet sker i den neuropsykologiska och fysiologiska dimensionen. För att förstå hur hörandet fungerar måste den fysikaliska dimensionen vara glasklar. Exakta beskrivningar av fysikaliska ljud är en förutsättning för förstå hur vi hör.
JM
Senior neurofoskanre - KI. Annihilerar antimateria. Beauty is in the Brain of the Listener. We are standing on the shoulders of giants. "Kill your Darlings" => Scientific Progress.
Ok. Nu ska jag försöka sammanfatta vilka slutsatser jag drar kopplat till stereofonisk återgivning av Peters senaste inlägg, och eventuella följdfrågor jag får. Så får det sågas det som jag fattat fel.
Det är alltså flera parallella processer som pågår i hörselsinnet i ett första skede när varje ny transient anländer till öronen, där frågan VAR besvaras av en av dessa processer. Men sedan i ett senare skede blir perceptionen till där frågan VAD (man hör) besvaras (med en 1ms eftersläpning minst då relativt trumhinnornas verklighet).
Direktljuden (4st om det är envägshögtalare, från varje högtalare till varje öra) måste tillsammans hålla alla de koder intakta som finns i programmaterialet som gör att VAR-processen kan ge ett så korrekt svar som möjligt. Annars korrumperas svaret från den senare VAD-frågan. Detta gör att det ställs STORA krav på hur direktljudet är beskaffat, och svaret på min fråga i föregående inlägg om huruvida direktljudet kan låta lite hur som helst blir alltså då NEJ (och det är synd för eventuella 70-talshögtalare som arbetat med principen att direktljudet inte spelar någon större roll).
Men jag blir djupare intresserad av hur dessa sekventiella och parallella processer (där VAD bestäms sekventiellt efter VAR mm) påverkar VAD som hörs.
Ponera att direktljuden från 2 högtalare som skall skapa en fantomprojektion då är såpass väl skapade att de når öronen med alla koder för att svara på frågan VAR intakta. Hur blir det då när frågan VAD besvaras, är något av ljudet som anlände den första millisekunden av en ny transient "borta" då för att det redan har hänt? Jag fiskar efter om det snarare är reflektioner än direktljud vi hör senare i frågan VAD på grund av tiden som har passerat för att bestämma VAR? Eller ligger det buffrat till VAD-processen liksom? Försvinner något lite från direktljudet när frågan VAD skall besvaras, som måste hämtas tillbaka från reflektioner för att inte försvinna från svaret?
Sen undrar jag om det finns något som liknar samplingsfrekvens i allt detta? Att VAR och VAD-processerna mfl körs om och om igen för varje sample liksom, i någon fast frekvens?
Jag undrar också om hörseln viktar direktljud och reflektioner olika mycket när de skall summeras i VAD-processen? Eller om det bara är en enkel sorts summering rätt av inom tidsområdet som integreras?
Jag har börjat fantisera om att starta en ny tråd med basic-frågan om exakt vad en transient är för något? Som kanske skulle mynna ut i en ökad förståelse om impulssvar och sådant. Men det kanske någon annan kan göra så att jag slipper stå med Svarte Petter varje gång?
petersteindl skrev:Spekulationer både från dig och alla andra i denna tråd gällande min koppling med centerhögtalare har inget att göra med mitt system.
F-n också! Kan du säga om ditt system liknar Michael Gerzons tänk, eller är det åt något helt annat håll? Jag har läst hans AES-papers från 90-talet, men förstår bara fragment. Jag har inte mattekunskaperna mm för att förstå det fullt tror jag. Var han på rätt väg?
rajapruk skrev:Ok. Nu ska jag försöka sammanfatta vilka slutsatser jag drar kopplat till stereofonisk återgivning av Peters senaste inlägg, och eventuella följdfrågor jag får. Så får det sågas det som jag fattat fel.
Det är alltså flera parallella processer som pågår i hörselsinnet i ett första skede när varje ny transient anländer till öronen, där frågan VAR besvaras av en av dessa processer. Men sedan i ett senare skede blir perceptionen till där frågan VAD (man hör) besvaras (med en 1ms eftersläpning minst då relativt trumhinnornas verklighet).
Direktljuden (4st om det är envägshögtalare, från varje högtalare till varje öra) måste tillsammans hålla alla de koder intakta som finns i programmaterialet som gör att VAR-processen kan ge ett så korrekt svar som möjligt. Annars korrumperas svaret från den senare VAD-frågan. Detta gör att det ställs STORA krav på hur direktljudet är beskaffat, och svaret på min fråga i föregående inlägg om huruvida direktljudet kan låta lite hur som helst blir alltså då NEJ (och det är synd för eventuella 70-talshögtalare som arbetat med principen att direktljudet inte spelar någon större roll).
Men jag blir djupare intresserad av hur dessa sekventiella och parallella processer (där VAD bestäms sekventiellt efter VAR mm) påverkar VAD som hörs.
Ponera att direktljuden från 2 högtalare som skall skapa en fantomprojektion då är såpass väl skapade att de når öronen med alla koder för att svara på frågan VAR intakta. Hur blir det då när frågan VAD besvaras, är något av ljudet som anlände den första millisekunden av en ny transient "borta" då för att det redan har hänt? Jag fiskar efter om det snarare är reflektioner än direktljud vi hör senare i frågan VAD på grund av tiden som har passerat för att bestämma VAR? Eller ligger det buffrat till VAD-processen liksom? Försvinner något lite från direktljudet när frågan VAD skall besvaras, som måste hämtas tillbaka från reflektioner för att inte försvinna från svaret?
Sen undrar jag om det finns något som liknar samplingsfrekvens i allt detta? Att VAR och VAD-processerna mfl körs om och om igen för varje sample liksom, i någon fast frekvens?
Jag undrar också om hörseln viktar direktljud och reflektioner olika mycket när de skall summeras i VAD-processen? Eller om det bara är en enkel sorts summering rätt av inom tidsområdet som integreras?
Fundera lite över din egen uppfattning om tillvaron överlag. Din verklighet består inte av tid i en linjär process där det som var är borta. Du rör dig över ett tidsspektrum och befinner dig i en omgivning av tid bakåt och även framåt, vad som rimligen kan förväntas. Om vi pratar om att leva i nuet så kan man undra när nu är, är det 1ms, 1 ps, 1 nanosekund, vilken vi inte ens uppfattat. När du tänkt på det en stund så tror jag du får ett annat perspektiv på ljudet också.
It ain't what you don't know that gets you into trouble. It's what you know for sure that just ain't so.
M.Twain
Perhaps you say that it's not accurate? I say it's entertainment!
rajapruk skrev:Ok. Nu ska jag försöka sammanfatta vilka slutsatser jag drar kopplat till stereofonisk återgivning av Peters senaste inlägg, och eventuella följdfrågor jag får. Så får det sågas det som jag fattat fel.
Det är alltså flera parallella processer som pågår i hörselsinnet i ett första skede när varje ny transient anländer till öronen, där frågan VAR besvaras av en av dessa processer. Men sedan i ett senare skede blir perceptionen till där frågan VAD (man hör) besvaras (med en 1ms eftersläpning minst då relativt trumhinnornas verklighet).
Direktljuden (4st om det är envägshögtalare, från varje högtalare till varje öra) måste tillsammans hålla alla de koder intakta som finns i programmaterialet som gör att VAR-processen kan ge ett så korrekt svar som möjligt. Annars korrumperas svaret från den senare VAD-frågan. Detta gör att det ställs STORA krav på hur direktljudet är beskaffat, och svaret på min fråga i föregående inlägg om huruvida direktljudet kan låta lite hur som helst blir alltså då NEJ (och det är synd för eventuella 70-talshögtalare som arbetat med principen att direktljudet inte spelar någon större roll).
Men jag blir djupare intresserad av hur dessa sekventiella och parallella processer (där VAD bestäms sekventiellt efter VAR mm) påverkar VAD som hörs.
Ponera att direktljuden från 2 högtalare som skall skapa en fantomprojektion då är såpass väl skapade att de når öronen med alla koder för att svara på frågan VAR intakta. Hur blir det då när frågan VAD besvaras, är något av ljudet som anlände den första millisekunden av en ny transient "borta" då för att det redan har hänt? Jag fiskar efter om det snarare är reflektioner än direktljud vi hör senare i frågan VAD på grund av tiden som har passerat för att bestämma VAR? Eller ligger det buffrat till VAD-processen liksom? Försvinner något lite från direktljudet när frågan VAD skall besvaras, som måste hämtas tillbaka från reflektioner för att inte försvinna från svaret?
Sen undrar jag om det finns något som liknar samplingsfrekvens i allt detta? Att VAR och VAD-processerna mfl körs om och om igen för varje sample liksom, i någon fast frekvens?
Jag undrar också om hörseln viktar direktljud och reflektioner olika mycket när de skall summeras i VAD-processen? Eller om det bara är en enkel sorts summering rätt av inom tidsområdet som integreras?
Fundera lite över din egen uppfattning om tillvaron överlag. Din verklighet består inte av tid i en linjär process där det som var är borta. Du rör dig över ett tidsspektrum och befinner dig i en omgivning av tid bakåt och även framåt, vad som rimligen kan förväntas. Om vi pratar om att leva i nuet så kan man undra när nu är, är det 1ms, 1 ps, 1 nanosekund, vilken vi inte ens uppfattat. När du tänkt på det en stund så tror jag du får ett annat perspektiv på ljudet också.
Jo tid är linjär för mig. Väl?! Jag kan inte resa i tiden vad jag vet. Den enda som jag vet lyckas med det på riktigt är Anders Limpar. Min egen uppfattade samplingsfrekvens av tillvaron är en tiondel i taget, kanske? Eller menar du tidsresa med hjälp av Madeleinekaka eller något sådant? Imaginärt liksom? Spana efter den tid som flytt.
petersteindl skrev:Slutligen, allt som det spekuleras i gällande hur jag använder centerhögtalare i ett stereofoniskt system är inkorrekt, inte ens i närheten av att vara korrekt. Spekulationer både från dig och alla andra i denna tråd gällande min koppling med centerhögtalare har inget att göra med mitt system.
Med vänlig hälsning Peter
Jag vill bara påpeka att mina spekulationer i tråden vad gäller centerhögtalare inte har något direkt fokus på just din lösning, även om det nu hade varit intressant att få veta om centern i din lösning kör en mono-signal av stereospåret som helhet eller om du filtrerar ut något specifikt som bara eller delvis spelas upp i centern.
Jag har svårt att se varför du inte vill ge en sådan ytlig information, ingen här är ute efter alla detaljer från din lösning.
Själv har jag på 70-talet experimenterat en del med monokoppling för C och svag stereoexpansion för L och R. Typ L = L-0,3R.
Det fungerar svindlande väl på visst programmaterial, men all form av sådan matris-processning jag testat (både teoretiskt och praktiskt) står och faller med systemets informations-coincidens, det vill säga det blir jättedåligt tillsammans med de allra bästa stereofoniska inspelningarna - tidsskillnadsinspelningarna. Så har man en sådan lösning så behöver den kunna kopplas bort på de bästa inspelningarna.
rajapruk skrev:...Jo tid är linjär för mig. Väl?! Jag kan inte resa i tiden vad jag vet.
Jag är precis tvärtom, jag kan inte låta bli att resa i tiden. Rör mig ständigt framåt med hastigheten 1s/s.
Så jag måste försiktigt ifrågasätta ditt påstående. Den text du författade är liksom ett bevis för att du rest i tiden. Utan att göra det kan inget hända, nämligen.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
Hahahaha Så du menar att tiden hela tiden står still, och det är vi själva som rör oss i den? Jag ser mig själv mer som en baksätespassagerare till tiden, jag bara åker med den. Jag kan resa med tiden, men inte resa i den.
Det hade varit väldigt kul att läsa teknisk fysik på universitet och lära sig mer kanske om vad tid är. Men jag har inte tiden som krävs.
På samma sätt som du reser i rummet när du åker med en buss. Oavsett hur passiv du är under resan.
Och nej, jag menar INTE att tiden står stilla. Då hade jag skrivit det. Jag menar nästan alltid det jag skriver (även om jag såklart någon gång kan råka skriva fel, alltså således att texten inte representerar min uppfattning).
Jag menar det motsatta - att tiden går, ständigt. Vi kan inte som från en buss hoppa av och stanna resan. Vi är alla ständiga tidsresenärer. Möjligen kan vi få tiden att gå saktare genom att ha det tråkigt. Jag avråder dock från det, eftersom den retroaktiva tiden påverkas tvärtom. Ju tråkigare man haft desto snabbare har livet gått när man tittar tillbaka. Så gör tvärtom istället - ha kul! Då går tiden fort men den retroaktiva tiden blir LÅÅÅÅNG! Talar nu såklart om tidsupplevelsen och inte om tiden i sig.
Förvisso kan systemtiden skilja sig från ett annat systems tid, och på så vis kan man resa väsentligt framåt i tiden, det vill säga nå t ex 500 år framåt i tiden och bara förbruka 50 år av sitt liv. Det blir dock dels kanske en småtrist resa och dessutom så hinner man inte med mera. Man bara hamnar någon annanstans, längre fram. Kan säkert vara kul på sitt sätt dock, men praktiska förutsättningar finns inte idag.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
rajapruk skrev:Jag har börjat fantisera om att starta en ny tråd med basic-frågan om exakt vad en transient är för något? Som kanske skulle mynna ut i en ökad förståelse om impulssvar och sådant. Men det kanske någon annan kan göra så att jag slipper stå med Svarte Petter varje gång?
Utifrån hur vi hör är det bättre att använda begreppet prominent ljud. Ett mätbart transient ljud behöver inte vara hörbart. Ett hörbart icke prominenta ljud aktiverar inte precedens effekten. Vissa prominenta ljud aktiverar även autonoma flykt/försvars reaktioner även hos djur/människor. Lågfrekventa ljud är mer hotfulla. Lejonets vrål upplevs helt annorlunda relativt musen pipande. Generellt frambringar stora djur mer lågfrekventa ljud. När hunden morrar hotfullt sjunker relativa frekvensen. Ett prominent ljud behöver inte vara lågfrekvent.
Tiden i hörandet är helt avgörande för perceptionen. Ett främmande ljud jämförs autonomt med tidigare upplevda ljud i ca 5 s förutsatt att inget annat ljud tillstöter inom 5 s och upplevs som viktigare. Vid icke träff i erfarenhetsbanken förkastas ljudet om ljudet i sin kontext upplevs som meningslöst eller skapas en ny ljuderfarenhet i sin upplevt viktiga kontext.
Se mina tidigare referenser.
JM
Senior neurofoskanre - KI. Annihilerar antimateria. Beauty is in the Brain of the Listener. We are standing on the shoulders of giants. "Kill your Darlings" => Scientific Progress.
JM skrev:Lågfrekventa ljud är mer hotfulla. Lejonets vrål upplevs helt annorlunda relativt musen pipande. Generellt frambringar stora djur mer lågfrekventa ljud. Ett prominent ljud behöver inte vara lågfrekvent.
Möss som vrålar som lejon är läskiga. En stor del av ”kvinnfolket” är lika rädd för möss som för lejon. Jag är mer rädd för spindlar än min sambo, spindlar saknar hörbart läte men de skapar en prominent känsla hos mig att vilja springa. Jag är aningen rädd för min sambo då hon ryter till.
Förlåt, din text var lite rolig. Åter till transistenter och prominenta ljud.
rajapruk skrev:Jag har börjat fantisera om att starta en ny tråd med basic-frågan om exakt vad en transient är för något? Som kanske skulle mynna ut i en ökad förståelse om impulssvar och sådant. Men det kanske någon annan kan göra så att jag slipper stå med Svarte Petter varje gång?
Utifrån hur vi hör är det bättre att använda begreppet prominent ljud. Ett mätbart transient ljud behöver inte vara hörbart. Ett hörbart icke prominenta ljud aktiverar inte precedens effekten. Vissa prominenta ljud aktiverar även autonoma flykt/försvars reaktioner även hos djur/människor. Lågfrekventa ljud är mer hotfulla. Lejonets vrål upplevs helt annorlunda relativt musen pipande. Generellt frambringar stora djur mer lågfrekventa ljud. När hunden morrar hotfullt sjunker relativa frekvensen. Ett prominent ljud behöver inte vara lågfrekvent.
Tiden i hörandet är helt avgörande för perceptionen. Ett främmande ljud jämförs autonomt med tidigare upplevda ljud i ca 5 s förutsatt att inget annat ljud tillstöter inom 5 s och upplevs som viktigare. Vid icke träff i erfarenhetsbanken förkastas ljudet om ljudet i sin kontext upplevs som meningslöst eller skapas en ny ljuderfarenhet i sin upplevt viktiga kontext.
Se mina tidigare referenser.
JM
Inte en siffra rätt där. Praktiskt taget alla transienta ljud har ett kontinuerligt spektrum och är därför nästan undantagslöst hörbara. Statiska ljud behöver inte vara det däremot.
Prominent betyder framträdande. Det är halvt subjektivt och inte översättbart till någon entydig teknisk egenskap hos ljud. Sambandet mellan frekvens och djurstorlek har till stor del mekaniska orsaker. Små saker har närmare till högfrekventa rörelser.
Är lågfrekventa ljud mera hotande? Är dunkandet från skenskarvarna i tågets sovkupé hotfullt? Är moderns hjärtslag hotfulla för det ofödda barnet? Är skrikande däck i trafiken inte hotfullt? Är ett tjutande larm inte hotfullt?
Bara för att det finns exempel (man kan hitta exempel på nästan vad som helst) så påvisar det inte en trend! Du måste sluta dra en massa ovetenskapliga, ogenomtänkta slutsatser, och samtidigt ikläda dig lärarrollen!
- - -
Sammanfattnkngsvis - Rajapruks originalförslag är mycket bättre.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
sprudel skrev: Watch out! Det kommer en tidpunkt när du kommer att sakna den tiden tjyvarna ”stal”.
Den var faktiskt lite tvetydig Ska tolkningen av "sakna den tiden" vara positiv eller negativ, retrospektivt?
Ah! Du såg det!
Visst är språk och meningar skönt.
Klart kul formulering! Jag fattade inte den avsiktliga dubbeltydigheter och trodde det var ett misstag - trodde att du egentligen menade ”Det kommer en tidpunkt då du kommer att sakna den tiden då tjuvarna stal tid.”
Typ inse att de inte stal tid utan bara förgyllde den.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
rajapruk skrev:Jag har börjat fantisera om att starta en ny tråd med basic-frågan om exakt vad en transient är för något? Som kanske skulle mynna ut i en ökad förståelse om impulssvar och sådant. Men det kanske någon annan kan göra så att jag slipper stå med Svarte Petter varje gång?
Utifrån hur vi hör är det bättre att använda begreppet prominent ljud. Ett mätbart transient ljud behöver inte vara hörbart. Ett hörbart icke prominenta ljud aktiverar inte precedens effekten. Vissa prominenta ljud aktiverar även autonoma flykt/försvars reaktioner även hos djur/människor. Lågfrekventa ljud är mer hotfulla. Lejonets vrål upplevs helt annorlunda relativt musen pipande. Generellt frambringar stora djur mer lågfrekventa ljud. När hunden morrar hotfullt sjunker relativa frekvensen. Ett prominent ljud behöver inte vara lågfrekvent.
Tiden i hörandet är helt avgörande för perceptionen. Ett främmande ljud jämförs autonomt med tidigare upplevda ljud i ca 5 s förutsatt att inget annat ljud tillstöter inom 5 s och upplevs som viktigare. Vid icke träff i erfarenhetsbanken förkastas ljudet om ljudet i sin kontext upplevs som meningslöst eller skapas en ny ljuderfarenhet i sin upplevt viktiga kontext.
Se mina tidigare referenser.
JM
Inte en siffra rätt där. Praktiskt taget alla transienta ljud har ett kontinuerligt spektrum och är därför nästan undantagslöst hörbara. Statiska ljud behöver inte vara det däremot.
Prominent betyder framträdande. Det är halvt subjektivt och inte översättbart till någon entydig teknisk egenskap hos ljud. Sambandet mellan frekvens och djurstorlek har till stor del mekaniska orsaker. Små saker har närmare till högfrekventa rörelser.
Är lågfrekventa ljud mera hotande? Är dunkandet från skenskarvarna i tågets sovkupé hotfullt? Är moderns hjärtslag hotfulla för det ofödda barnet? Är skrikande däck i trafiken inte hotfullt? Är ett tjutande larm inte hotfullt?
Bara för att det finns exempel (man kan hitta exempel på nästan vad som helst) så påvisar det inte en trend! Du måste sluta dra en massa ovetenskapliga, ogenomtänkta slutsatser, och samtidigt ikläda dig lärarrollen!
- - -
Sammanfattnkngsvis - Rajapruks originalförslag är mycket bättre.
Vh, iö
Jag är öppen för att ha fel! Men då måste du bevisa att så är fallet.
Att auktoritärt bara hävda att jag har fel köper jag inte.
Förstår du inte att att du kommer med ett svepande personangrepp i avsaknad av fakta.
Jag känner mig trygg i mina kunskaper. Det är bara att kolla mina tidigare referenser.
JM
Senior neurofoskanre - KI. Annihilerar antimateria. Beauty is in the Brain of the Listener. We are standing on the shoulders of giants. "Kill your Darlings" => Scientific Progress.
Jag gav dig flera exempel på hur du har fel, jag pekade på det tokiga att basera en slutsats på utvalda exempel (Lejon/mus) utan att ha en susning om helheten (som innehåller massor av motsatta saker).
Men din reaktion är den vanliga - du låtsas som om det inte händt. Du gör gållande att jag har inte argumenterat mot dina dumheter... Du är immun! Men det gör inget. Jag vet ju att du är ett lost case. Så poängen med att peka på dina tokigheter är inte att du skall lära dig något, det är för andras skull.
Att du är trygg med dina ”kunskaper” är det som kanske är mest skrämmande. Det är ju det som gör att du ser dig som lämplig att föreläsa, vilket du verkligen INTE ÄR!!!
Du är så totalblind för var du befinner dig! Det tycks omöjligt att knuffa dig över krönet och nedför backen. Trots att du borde ha varit där för länge, länge sedan.
Vh, iö
Senast redigerad av IngOehman 2019-12-06 12:51, redigerad totalt 1 gång.
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
rajapruk skrev:Så du menar att tiden hela tiden står still, och det är vi själva som rör oss i den?
Nej, varför skulle jag mena det? Men faktum är att man KAN se det så. Som att tiden är en almanacka, och ögonblicket rör sig däri, men du kan röra ditt finger hur du vill och peka på tid som varit, på nuet eller tid som komma skall. Det är inte konstigare än att man kan hålla en karta stilla och röra fingret på den. Det betyder inte att man reser, bara att man förstår hur man projicerar. Vi människor är bra på sådant.
rajapruk skrev:Jag kan resa med tiden, men inte resa i den.
rajapruk skrev:Jag skulle nog hellre formulera det tvärtom - som att du visst reser i tiden, tillsammans med ögonblickets rörelse i tidsdimensionen.
rajapruk skrev:Det hade varit väldigt kul att läsa teknisk fysik på universitet och lära sig mer kanske om vad tid är. Men jag har inte tiden som krävs.
Nästan allt i livet handlar om prioriteringar.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
Den har ritats på många sätt, det viktiga är att ha som mål att ta sig till den ”riktiga startpunkten” - dippen mellan topparna! Och sen jobba vidare på sin kunskap därifrån. Med rätt mentalitet så kan man ta sig över första toppen redan första dagen.
Men, många fastnar för livet redan i den första uppförsbacken. Skrämmande ofta nära toppen dessutom.
En bra lärare kan till och med föra en begåvad elev åt höger utan att passera den första toppen alls. Tips 1 är att skippa alla tumregler. Att alltid lägga mera energi på sammanhangen än på detaljerna. Tumregler och andra sorters förenklingar bygger topp nummer 1.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
IngOehman skrev:Jag gav dig flera exempel på hur du har fel, jag pekade på det tokiga att basera en slutsats på utvalda exempel (Lejon/mus) utan att ha en susning om helheten (som innehåller massor av motsatta saker).
Men din reaktion är den vanliga - du låtsas som om det inte händt. Du gör gållande att jag har inte argumenterat mot dina dumheter... Du är immun! Men det gör inget. Jag vet ju att du är ett lost case. Så poängen med att peka på dina tokigheter är inte att du skall lära dig något, det är för andras skull.
Att du är trygg med dina ”kunskaper” är det som kanske är mest skrämmande. Det är ju det som gör att du ser dig som lämplig att föreläsa, vilket du verkligen INTE ÄR!!!
Du är så totalblind för var du befinner dig! Det tycks omöjligt att knuffa dig över krönet och nedför backen. Trots att du borde ha varit där för länge, länge sedan.
Jag kan förstå din frustration när din kunskap inte får fäste trots att du försöker så ihärdigt. Men jag tycker ändå att det mesta du skriver i det citerade inlägget ovan är väldigt onödigt. Du, med din kunskap, borde kunna stå över sådant. Det behövs inga föreläsningar om vad andra kan och inte kan, det räcker med att du visar vad DU kan!
/ B (hobbymoderator mpa)
När Einstein insåg att allt var relativt började han kröka på rummet.
Nja, jag vet inte om jag kan hålla med. Det här har pågått länge och ingen har hittills vad jag vet hållit med JM och beslagit Öhman med att ha fel i det han påpekar, så jag läser alltid JM's postningar med en gnagande känsla av att det kanske inte alls är riktigt. För mig som inte har mycket teoretisk kunskap om ljud och hörsel och försöker lära mig så är det problematiskt att det som skrivs kanske inte alls stämmer.
Ted_B skrev:Nja, jag vet inte om jag kan hålla med. Det här har pågått länge och ingen har hittills vad jag vet hållit med JM och beslagit Öhman med att ha fel i det han påpekar, så jag läser alltid JM's postningar med en gnagande känsla av att det kanske inte alls är riktigt. För mig som inte har mycket teoretisk kunskap om ljud och hörsel och försöker lära mig så är det problematiskt att det som skrivs kanske inte alls stämmer.
Bra fråga. Vad är mest sannolikt? Hur skall frågan lösas? Observera att mina påståenden/citeringar är vanligen i den psykologiska/medicinska dimensionen och inte i den tekniska. Se tidigare inlägg.
JM
Senior neurofoskanre - KI. Annihilerar antimateria. Beauty is in the Brain of the Listener. We are standing on the shoulders of giants. "Kill your Darlings" => Scientific Progress.
1. När någon skriver något som är uppåt väggarna fel så bör det påpekas av så många som möjligt. Den som själv inte har kunskap slipper då luras av påståenden som levereras på ett sätt som får det att verka som om den som skriver rappakalja ser sig som kunnig och lämplig lärare.
2. När man själv söker kunskap så tro inte på en massa påståenden eller hänvisningar till vad andra skriver - oavsett från vem de kommer! Tro bara det som motiveras sålunda att du själv förstår att det är riktigt. Att lära sig några av de grundläggande vetenskapsprinciperna är till stor hjälp för att man skall se när otillåtna slutsatser dragits.
3. Helst skulle den som som ständigt klampar i klaveret lära sig av det också, men det är från svårt till omöjligt att lära någon som inte vill lära sig. Speciellt då det är en person som är i den första uppförsbacken nära krönet. Krönet kännetecknas ju av en tro att kunna allt, om du finns ju inte plats för att lära sig mera.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
petersteindl skrev:Jag vill exemplifiera en sak för flera på faktiskt, dock speciellt för JM och för tangband. Det gäller direktljudet från Bremen 3D8 även kallad äggen. Hur ser direktljudet i diskanten ut? Det spekuleras ju en del. Låt oss se hur en sådan konfiguration kan te sig.
Med vänlig hälsning Peter
Mycket intressanta mätningar. Direktljudet ser mycket bra ut på dina mätningar map frekvens i mätpositionen. Saknar mätningar i lyssningspositionen vid övrigt identiska mätningarna med äggen på vägg med allt inkopplat även basar. Hur ser mätningarna ut efter ca 0-1, 1-2, 2 -8, 8-15, 15- 20 och 20-30 ms. Rummet måste vara exakt beskrivet för att förstå resultaten.
JM
Så, nu har jag lite tid över. Jag förstår inte vad du vill se för typ av mätningar?
Du vill att mätning redovisas gällande hela högtalaren monterad på vägg. D v s med alla högtalarelement + delningsfilter inkopplade. Så har jag förstått det. Ok, det förstår jag. Du vill att mikrofonen är placerad i lyssningsposition. Ok, det förstår jag till viss del. Men du bör kunna motivera varför.
Du vill att det är direktljudet som mäts och inget annat än direktljudet skall ingå i mätningen. Ok, det förstår jag. Du skriver att rummet måste vara exakt beskrivet för att förstå resultaten. Jag vill här faktiskt hävda motsatsen. Rummet behöver inte alls förstås eftersom rumsegenskaper inte ingår i direktljudet. Däremot om mätningen är ett slags mellanting av mätning på direktljud samt några reflexer så bör delar av rummet specas, t.ex. avstånd från högtalare till 3 närstående begränsningsytor (golv eller tak + 2 väggar). Så fort man tagit med påverkan från 2 parallella begränsningsytor så är rumsegenskaper med i mätningen. Däremot är det inte så med 3 ortogonala begränsningsytor. Vill du mäta rumsegenskaper eller högtalarens högtalaregenskaper?
Sedan har vi en liten konstig sak som du raddar upp och som jag inte förstår vad du vill ha sagt. Du frågar hur mätningarna ser ut med mikrofon på lyssnarplats och efter ca 0-1, 1-2, 2 -8, 8-15, 15- 20 och 20-30 ms.
Vad vill du skall ingå i mätningarna? Är det: 1. från tidpunkten 0 t.o.m. 1 ms. 2. från tidpunkten 0 t.o.m. 2 ms. 3. från tidpunkten 0 t.o.m. 8 ms. 4. från tidpunkten 0 t.o.m. 15 ms. 5. från tidpunkten 0 t.o.m. 20 ms. 6. från tidpunkten 0 t.o.m. 30 ms. I alla dessa mätresultat ingår originalpulsen vid tidpunkten 0.
Eller är det så här? 1. från tidpunkten 0 t.o.m. 1 ms. Här ingår originalpulsen. 2. från tidpunkten 1 ms t.o.m. 2 ms. 3. från tidpunkten 2 ms t.o.m. 8 ms. 4. från tidpunkten 8 ms t.o.m. 15 ms. 5. från tidpunkten 15 ms t.o.m. 20 ms. 6. från tidpunkten 20 ms t.o.m. 30 ms. I mätningar 2 till 6 ingår inte originalpulsen. Den har ju fönstrats bort.
Jag förstår inte hur du tänker?? Vad är det du vill få fram? Vad specifikt anser du att man skulle kunna utläsa av sådana mätningar??
Är det någon form av vattenfallsmätning du vill se?
Om man skulle kunna utäsa något väsentligt i sådana mätningar så måste det finnas lika mätningar för andra högtalare som jämförelse. Har du jämförande ekvivalenta mätningar på andra högtalare?? Om inte, så säger mätningarna ingenting.
Du bör kunna beskriva mätningen tydligare och kunna motivera varför mätningen skall utföras.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
Även detta inlägg har jag svårt att förstå. Jag kommer här göra som jag ibland gör, nämligen försöka göra en analys genom att fokusera på varje fragment som skrivs för att därefter binda ihop fragmenten till en övergripande helhet, en så kallad syntes.
Analys förståelse av de enskilda enheterna sammanfogande av enheterna Syntes. Då får man dels fram om det finns logiska tankevurpor t.ex. om sakerna/enheterna är i strid med varandra d v s motsägelsefulla och då faller både fragmenten och syntesen. Är det logiskt korrekt kan syntesen vara falsk eller sann.
JM skrev:Det där med direktljud är inte så självklart.
Påstående 1A.) Är direktljudet lika starkt som ett annat ljud identiskt ljud, framför nära lyssnaren, vilket anländer till örat samtidigt -. Påstående 1B.) Typ att monoljud hamnar mittemellan stereohögtalarna.
Påstående 2.) Detta gör att direktljudet från ett av Peters ägg för låga frekvenser hamnar mittemellan högtalarelementen medans vid högre frekvenser upplevs allmer komma från den närmaste högtalaren pga ökande beaming.
Påstående 3.) Skugghögtalarens bidrag till direktljudet i de högsta frekvenserna minskar med ökande frekvens. Detta är bara av akademiskt intresse och påverkar i praktiken inte ljudupplevelsen.
Ett direkt klickljud följs av ett identiskt (map frekvens/ljudstyrka) klickljud efter 2 ms uppfattas som 2 olika ljud med olika lokalisation. . . . JM
Här finns nu 4 st påståenden. Jag skall försöka göra en analys.
Påstående 1A.) Här verkar det vara 2 ljudkällor som ger varsitt koherent med varandra ljud ifrån sig. Det ena ljudet verkar definieras som direktljud. Det andra ljudet är koherent med direktljudet med riktningen och avståndet framför uppfattas bara ett ljud vilket lokaliseras mitt emellan ljudkällornaoch nära lyssnaren. Dock anländer det till örat samtidigt. Ok, låt oss säga att det rör sig om höger öra. Då kan man ta en passare och sätta spetsen i höger öra. Sedan ritar man en cirkel runt lyssnaren där höger öra är cirkelns origo. Båda högtalarna måste ha sitt centrum på cirkelns omkrets för att deras ljud skall kunna anlända till örat samtidigt. Låt säga att högtalare H är positionerad på cirkelbågen 30 grader till höger om höger öra och den andra högtalaren, kallad C är ungefär rakt framför d v s har 0 grader. Då påstås det att det uppfattas bara ett ljud vilket lokaliseras mitt emellan ljudkällorna. I beg to dissagree, som man säger på engelska. Det beror på att vänster öra hamnar längre bort från högtalare H än från högtalare C. Summationen blir osymmetrisk med olika kamfiltereffekter på respektive öron som följd som hörseln har svårt med att klara av. Det är faktiskt den svåraste situationen vid stereolyssning med 2 högtalare.
Påstående 1B.) Detta är något helt annat än påstående 1A. Normalt sett är origo mitt emellan öronen d v s i centrum av huvudet och då kan man vrida huvudet runt origo d v s runt sitt eget huvuds centrum. Det ger symmetri som hörseln har hyfsat lätt för att klara.
Påstående 2.) Detta gäller tydligen 1 och endast 1 ägg. Direktljudet från 1 ägg för låga frekvenser kommer ur Midwoofern. Direktljudet från höga frekvenser kommer från diskanterna samt från närmaste väggreflex Tidsskillnaden mellan diskanten närmast lyssnaren och den skuggade diskanten är 0,2 ms. Tidsskillnaden mellan diskanten närmast lyssnaren och väggreflexen d v s dess spegelbildsdiskant är 0,11 ms. Så, vi har en initial puls vid tiden 0 + en puls vid tiden 0,11 ms + vid 0,2 ms + en fjärde spegelbild som är vid ungefär 0,3 ms. De fördröjda ligger betydligt lägre i nivå och speciellt vid höga frekvenser. Efter filter ser en impuls inte ut som före filter. Lägger man ihop dessa 4 bandpassfiltrerade pulser enligt superpositionsprincipen fås 1 puls som jag redovisat tidigare i tråden. Det ser ut så här.
4a 3D8 på vägg med 2 diskanter direct-axis 1500us.png (105.08 KiB) Visad 5802 gånger
Här ser man klart och tydligt att det rör sig om 1 och endast 1 puls.
JM påstår att direktljudet hamnar mittemellan högtalarelementen vid låga frekvenser, viket jag inte förstår vilka element det skulle vara eftersom det enkom rör sig om 1 och endast 1 Midwoofer. JM påstår vidare att högre frekvenser upplevs alltmer komma från den närmaste högtalaren pga ökande beaming. Skulle den närmaste högtalaren här vara det närmaste diskantelementet? Om det är det som JM menar så är det ett felaktigt påstående. Dessutom spelar ingen beaming någon roll för direktljudet från 1 högtalare. Dessutom kan jag säga att ägghögtalarna upplevs beama betydligt mindre än de flesta andra högtalarna på marknaden.
Påstående 3.) Här vet jag inte riktigt vad JM vill ha sagt?
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
JM skrev:Peter vad vill du förmedla? För mig är inlägget bara förvirrande. Jag skulle uppskatta om du fokuserade på kärnbudskapet. Blanda inte in oväsentligheter. Inlägget blir inte bättre genom att blanda in fragment av begrepp som är oväsentliga. Då hörandet är komplicerat är det viktigt som jag ser det att belysa ett område i taget. Hörandet sker i den neuropsykologiska och fysiologiska dimensionen. För att förstå hur hörandet fungerar måste den fysikaliska dimensionen vara glasklar. Exakta beskrivningar av fysikaliska ljud är en förutsättning för förstå hur vi hör.
JM
Lite info om ljud in natura och ljud upplevt och vilken typ av processer som ingår. Ljud finns beskrivet som en fysikaliskt fenomen inom akustiken och som psykologiskt fenomen inom psykofysiken psykoakustiken och såsom intermediär process inom psykofysiken och som inre neural företeelse som studeras inom neurofysiologin. Som medvetandeprocess beskrivs det inom kognitiv psykologi.
petersteindl skrev:Diskuteras det direktljud och lokalisation så är det detta jag först och främst diskuterar och inget annat. Jag vill gärna försöka cementera fenomenet direktljud och vad det är, ur alla möjliga synvinklar, innan jag går vidare i diskussionen. Min ambition är att försöka kasta lite ljus över ett komplicerat ämne som ännu verkar vara ett mörker.
Eftersom det diskuteras riktning på ljud och riktningshörande så är vektoranalysen den klart dominanta grenen att damma av. Dessutom är den väldigt svår och krävande och inte lättillgänglig om man inte har grunderna lagda som man kan bygga vidare på. Skall man bygga en skyskrapa så måste man ha lagt en betydligt bredare grundstomme som skyskrapan skall vila på än bredden på skälva skyskrapan. Därför blir grunden till synes betydligt bredare än vad man först kan tro behövas. Upplevs det förvirrande så tror jag att jag lyckats.
Det gäller att koppla ihop vektoranalysens objektiva värld med vektorer som grund och hur vektorer beskrivs och att det finns grundläggande regler, såsom t.ex. koordinatsystem med origo och rumsderivata i form av gradient och tidsderivata. Rumsderivata i form av gradient är tryckgradient som har riktning i ett vektorfält. Tidsderivata är en hastighet som t.ex. partikelhastighet hos Ljudintensitet.
Öronen med respektive trumhinna mäter tryck i olika positioner och hjärnan får fram tryckgradienten runt huvudet och speciellt från direktljudet. Då kan det vara bra att veta att koordinatsystemet i människan är fysikaliskt uppbyggt som det kartesiska koordinatsystemet och vi har 2 känsliga organ med 2 koordinatsystem som dessutom är differentiellt ihopkopplade för att öka exaktheten och noggrannheten med kanske en faktor 100 - 1000 ggr. Har du 2 kopplade system som summerar så blir skillnaden mellan olika värden liten bråkdel av 1 procent medans med differentiell koppling kan det bli flera 100 procents vid samma inbördes förändring mellan inneröronens koordinatsystem. Varje transient registreras betydligt effektivare. Varje inkrementskillnad ger stort utslag med differentiell mätning.
Det är klara samband mellan fysikens lagar i den yttre materiella världen och människan som mätinstrument med fysikens lagar i den inre materiella världen som tycks vara specialiserad för mätning av stimuli i den yttre materiella världen.
Att ta en sak i sänder är meningslöst eftersom allt hänger ihop som en kunskapslabyrint.
Det gäller att få kunskap runt om cirkeln i yttersta lagret. Det går inte utan att tränga ett lager djupare. Då måste man gå ytterligare ett lager djupare som förståelse för näst yttersta lagret som behövs för förståelse av yttersta lagret. Dessutom måste man behärska områdena runtomkring. Man tränger alltså in i djupled samt i sidled. Kunskapslabyrinten a la onkel Steindl. Jag har även tagit upp detta i tidigare inlägg.
Än så länge är detta med riktningshörande ett enigma. Så småningom kommer jag in på det verkligt svårsmälta. Det som ingen tycks tänka på, inte ens di lärde som du ibland refererar till. Enigma betyder gåta, men är även namnet på en krypteringsmaskin d v s kodning och avkodning. Synnerligen passande ord. Di lärde undervisar inte om hörseln som en mätapparat för mätning av tryckgradienter d v s mätning av vektorer. I princip alla utgår ifrån att man hör ljudtryck d v s en skalär storhet. Och så är det efter denna initiala lilla millisekund av tryckgradientprocess i vårt centrala nervsystem och hjärna.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
rajapruk skrev:Jag har börjat fantisera om att starta en ny tråd med basic-frågan om exakt vad en transient är för något? Som kanske skulle mynna ut i en ökad förståelse om impulssvar och sådant. Men det kanske någon annan kan göra så att jag slipper stå med Svarte Petter varje gång?
Utifrån hur vi hör är det bättre att använda begreppet prominent ljud. Ett mätbart transient ljud behöver inte vara hörbart. Ett hörbart icke prominenta ljud aktiverar inte precedens effekten. Vissa prominenta ljud aktiverar även autonoma flykt/försvars reaktioner även hos djur/människor. Lågfrekventa ljud är mer hotfulla. Lejonets vrål upplevs helt annorlunda relativt musen pipande. Generellt frambringar stora djur mer lågfrekventa ljud. När hunden morrar hotfullt sjunker relativa frekvensen. Ett prominent ljud behöver inte vara lågfrekvent.
Tiden i hörandet är helt avgörande för perceptionen. Ett främmande ljud jämförs autonomt med tidigare upplevda ljud i ca 5 s förutsatt att inget annat ljud tillstöter inom 5 s och upplevs som viktigare. Vid icke träff i erfarenhetsbanken förkastas ljudet om ljudet i sin kontext upplevs som meningslöst eller skapas en ny ljuderfarenhet i sin upplevt viktiga kontext.
Se mina tidigare referenser.
JM
Prominent ljud är en helt annan egenskap än transient ljud. Två skilda världar.
Wiki skrev:A transient event is a short-lived burst of energy in a system caused by a sudden change of state. The source of the transient energy may be an internal event or a nearby event. The energy then couples to other parts of the system, typically appearing as a short burst of oscillation. The typical sound of some musical instruments is also characterized by acoustic transients, which can be heard when striking a percussion instrument or the strings of a string instrument. In electrical engineering, oscillation is an effect caused by a transient response of a circuit or system. It is a momentary event preceding the steady state (electronics) during a sudden change of a circuit or start-up
Prominent ljud är en helt annan femma. Prominenta ljud är ofta helt kognitiva till sin natur. kanske det mest prominenta ljudet människan kan konfronteras med är våra spädbarns skrik. Då vaknar vi till liv.
Människans neurofysiologi är specialanpassat för detektion av förändringar i omgivningen. Man kan se det som acceleration från steady state.
Exakt vilka av dina tidigare referenser vill du explicit referera till?
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
petersteindl skrev:Jag börjar med att svara JMs olika inlägg.
JM skrev:
rajapruk skrev:Jag har börjat fantisera om att starta en ny tråd med basic-frågan om exakt vad en transient är för något? Som kanske skulle mynna ut i en ökad förståelse om impulssvar och sådant. Men det kanske någon annan kan göra så att jag slipper stå med Svarte Petter varje gång?
Utifrån hur vi hör är det bättre att använda begreppet prominent ljud. Ett mätbart transient ljud behöver inte vara hörbart. Ett hörbart icke prominenta ljud aktiverar inte precedens effekten. Vissa prominenta ljud aktiverar även autonoma flykt/försvars reaktioner även hos djur/människor. Lågfrekventa ljud är mer hotfulla. Lejonets vrål upplevs helt annorlunda relativt musen pipande. Generellt frambringar stora djur mer lågfrekventa ljud. När hunden morrar hotfullt sjunker relativa frekvensen. Ett prominent ljud behöver inte vara lågfrekvent.
Tiden i hörandet är helt avgörande för perceptionen. Ett främmande ljud jämförs autonomt med tidigare upplevda ljud i ca 5 s förutsatt att inget annat ljud tillstöter inom 5 s och upplevs som viktigare. Vid icke träff i erfarenhetsbanken förkastas ljudet om ljudet i sin kontext upplevs som meningslöst eller skapas en ny ljuderfarenhet i sin upplevt viktiga kontext.
Se mina tidigare referenser.
JM
Prominent ljud är en helt annan egenskap än transient ljud. Två skilda världar.
Wiki skrev:A transient event is a short-lived burst of energy in a system caused by a sudden change of state. The source of the transient energy may be an internal event or a nearby event. The energy then couples to other parts of the system, typically appearing as a short burst of oscillation. The typical sound of some musical instruments is also characterized by acoustic transients, which can be heard when striking a percussion instrument or the strings of a string instrument. In electrical engineering, oscillation is an effect caused by a transient response of a circuit or system. It is a momentary event preceding the steady state (electronics) during a sudden change of a circuit or start-up
Prominent ljud är en helt annan femma. Prominenta ljud är ofta helt kognitiva till sin natur. kanske det mest prominenta ljudet människan kan konfronteras med är våra spädbarns skrik. Då vaknar vi till liv.
Människans neurofysiologi är specialanpassat för detektion av förändringar i omgivningen. Man kan se det som acceleration från steady state.
Exakt vilka av dina tidigare referenser vill du explicit referera till?
Brandvarnare är oftast mätmässigt och upplevelsemässigt transienta för vuxna/djur. Många barn har en djupare sömn än vuxna där brandvarnarens ljud är inte tillräckligt prominent. From stem of Latin transiens, present participle of transire (“to go over, to pass”) https://en.wiktionary.org/wiki/transient From obsolete French prominent (compare proéminent), from Latin prōminēns, present active participle of prōmineō (“jut out, to project”), from prō (“before, forward”) + mineō (in compounds, “jut, project”) https://en.wiktionary.org/wiki/prominent
Prominenta ljud är upplevda ljud skilda från fysikens mätbara ljud. Hörbara upplevda prominenta ljud urskiljer sig från bakgrundsljuden. Vad som är prominent ljud beror på kontexten. Kontexten är här både bakgrundsljuden och hjärnans momentana sensitivitet för ett specifikt ljud.
Testar jag brandvarnaren flyr katten till ett annat rum.
Hörandet är till största delen icke viljestyrt - autonomt. Vi kan vanligen inte välja att inte höra. Kognitiva processer i hjärnan är vanligen viljestyrda. Processen att lära sig ett nytt språk är en kognitiv process. När vi kan vissa delar det nya språket blir hörandet och förståelsen av dessa ord icke viljemässig. Dvs icke viljemässig förståelse av språk förutsätter tidigare kognitiva processer/erfarenheter vilka utvecklats och lagrats i hjärnan på många olika platser.
JM
Senior neurofoskanre - KI. Annihilerar antimateria. Beauty is in the Brain of the Listener. We are standing on the shoulders of giants. "Kill your Darlings" => Scientific Progress.
"transient (plural transients)" "(acoustics) A relatively loud, non-repeating signal in an audio waveform which occurs very quickly, such as the attack of a snare drum." https://en.wiktionary.org/wiki/transient
Det är mer än originellt - det är uppåt väggarna fel!
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
Man bör nog värdera informations-innehållet i signalen som är helt olika för barn och vuxna.
För de flesta vuxna betyder brandvarnarljudet : Jävlar! Det brinner!
Vad betyder det för ett barn?
Vår fantastiska förmåga att tolka ljud är samtidigt vårt sätt att selektera och av det prioritera och reagera. "Cocktail effekten" kallas den ibland för.....
Min hund reagerar inte på "vanliga ljud" ( även höga ljud) i sömnen men om jag försiktigt skruvar av locket på hundgodisburken vaknar han direkt
petersteindl skrev:Jag börjar med att svara JMs olika inlägg.
JM skrev:Utifrån hur vi hör är det bättre att använda begreppet prominent ljud. Ett mätbart transient ljud behöver inte vara hörbart. Ett hörbart icke prominenta ljud aktiverar inte precedens effekten. Vissa prominenta ljud aktiverar även autonoma flykt/försvars reaktioner även hos djur/människor. Lågfrekventa ljud är mer hotfulla. Lejonets vrål upplevs helt annorlunda relativt musen pipande. Generellt frambringar stora djur mer lågfrekventa ljud. När hunden morrar hotfullt sjunker relativa frekvensen. Ett prominent ljud behöver inte vara lågfrekvent.
Tiden i hörandet är helt avgörande för perceptionen. Ett främmande ljud jämförs autonomt med tidigare upplevda ljud i ca 5 s förutsatt att inget annat ljud tillstöter inom 5 s och upplevs som viktigare. Vid icke träff i erfarenhetsbanken förkastas ljudet om ljudet i sin kontext upplevs som meningslöst eller skapas en ny ljuderfarenhet i sin upplevt viktiga kontext.
Se mina tidigare referenser.
JM
Prominent ljud är en helt annan egenskap än transient ljud. Två skilda världar.
Wiki skrev:A transient event is a short-lived burst of energy in a system caused by a sudden change of state. The source of the transient energy may be an internal event or a nearby event. The energy then couples to other parts of the system, typically appearing as a short burst of oscillation. The typical sound of some musical instruments is also characterized by acoustic transients, which can be heard when striking a percussion instrument or the strings of a string instrument. In electrical engineering, oscillation is an effect caused by a transient response of a circuit or system. It is a momentary event preceding the steady state (electronics) during a sudden change of a circuit or start-up
Prominent ljud är en helt annan femma. Prominenta ljud är ofta helt kognitiva till sin natur. kanske det mest prominenta ljudet människan kan konfronteras med är våra spädbarns skrik. Då vaknar vi till liv.
Människans neurofysiologi är specialanpassat för detektion av förändringar i omgivningen. Man kan se det som acceleration från steady state.
Exakt vilka av dina tidigare referenser vill du explicit referera till?
Brandvarnare är oftast mätmässigt och upplevelsemässigt transienta för vuxna/djur. Många barn har en djupare sömn än vuxna där brandvarnarens ljud är inte tillräckligt prominent. From stem of Latin transiens, present participle of transire (“to go over, to pass”) https://en.wiktionary.org/wiki/transient From obsolete French prominent (compare proéminent), from Latin prōminēns, present active participle of prōmineō (“jut out, to project”), from prō (“before, forward”) + mineō (in compounds, “jut, project”) https://en.wiktionary.org/wiki/prominent
Prominenta ljud är upplevda ljud skilda från fysikens mätbara ljud. Hörbara upplevda prominenta ljud urskiljer sig från bakgrundsljuden. Vad som är prominent ljud beror på kontexten. Kontexten är här både bakgrundsljuden och hjärnans momentana sensitivitet för ett specifikt ljud.
Testar jag brandvarnaren flyr katten till ett annat rum.
Hörandet är till största delen icke viljestyrt - autonomt. Vi kan vanligen inte välja att inte höra. Kognitiva processer i hjärnan är vanligen viljestyrda. Processen att lära sig ett nytt språk är en kognitiv process. När vi kan vissa delar det nya språket blir hörandet och förståelsen av dessa ord icke viljemässig. Dvs icke viljemässig förståelse av språk förutsätter tidigare kognitiva processer/erfarenheter vilka utvecklats och lagrats i hjärnan på många olika platser.
JM
Jag vidhåller att ljud som skall uppfattas som prominenta skall först genomgå en kognitiv process. Det handlar om kognitiva processer. Du hänvisar till en artikel från TT. då jag läser den är det helt klart att det handlar om kognitans och kognitiva processer, d v s inlärda processer och det kräver minne samt igenkänning.
TT skrev:Niamh NicDaeid, professor i rättsmedicin vid universitetet i skotska Dundee, har de senaste åren tillsammans med Derbyshires räddningstjänst genomfört flera studier för att ta reda på hur effektiva brandvarnare egentligen är när det gäller att väcka barn. I en studie utförde forskarna tester på 644 barn i deras hemmiljö. Forskarna lät brandlarmet utlösas mitt i natten, när barnen befann sig i djupsömn. Endast 28 procent av barnen vaknade av tjutet. När forskarna i stället bytte ut brandvarnarens höga frekvens mot en signal med lägre frekvens, kombinerat med ett inspelat varningsmeddelande uppläst av barnens mamma, vaknade mer än 75 procent av dem.
– Vi säger inte alls att brandvarnare inte fungerar. Vad vi säger är att du inte nödvändigtvis kan vänta dig att dina barn vaknar av brandvarnaren, säger Niamh NicDaeid till TT.
Ju äldre barnen är, desto större är sannolikheten att de faktiskt vaknar av en konventionell brandvarnare. Vid tolv års ålder vaknar de flesta. Men varför inte små barn vaknar av höga frekvenser är inte helt klart.
– Tidigare forskning visar att unga barn inte är programmerade att uppfatta pipande oljud från födseln. Däremot har de en anknytning till sina föräldrars röst, säger NicDaeid.
För övrigt vet jag inte vad det är som skulle sätta transienta förlopp i ett slags förhållande till prominenta ljud. Det är skilda världar.
Med vänlig hälsning Peter
VD Bremen Production AB + Ortho-Reality AB; Grundare av Ljudbutiken AB; Fd import av hifi; Konstruktör av LICENCE No1 D/A, Bremen No1 D/A, Forsell D/A, SMS FrameSound, Bremen 3D8 m.fl.
jansch skrev:Man bör nog värdera informations-innehållet i signalen som är helt olika för barn och vuxna.
För de flesta vuxna betyder brandvarnarljudet : Jävlar! Det brinner!
Vad betyder det för ett barn?
Vår fantastiska förmåga att tolka ljud är samtidigt vårt sätt att selektera och av det prioritera och reagera. "Cocktail effekten" kallas den ibland för.....
Min hund reagerar inte på "vanliga ljud" ( även höga ljud) i sömnen men om jag försiktigt skruvar av locket på hundgodisburken vaknar han direkt
Det är nog som du säger, det handlar helt klart om inlärning och om person till person.
Om en person som är livrädd för möss bor i ett hus där det ibland händer att det dyker upp en mus, så kommer nog den personen möjligen hoppa högt ifall hon/han hör ett litet mus-pip.
Hittade inget bra tecken för att illustrera att den vänstra L var en icke-urspunglig signal. Hade kanske kunnat kalla den högra för L’.
goat76 skrev:
jansch skrev:Man bör nog värdera informations-innehållet i signalen som är helt olika för barn och vuxna.
För de flesta vuxna betyder brandvarnarljudet : Jävlar! Det brinner!
Vad betyder det för ett barn?
Vår fantastiska förmåga att tolka ljud är samtidigt vårt sätt att selektera och av det prioritera och reagera. "Cocktail effekten" kallas den ibland för.....
Min hund reagerar inte på "vanliga ljud" ( även höga ljud) i sömnen men om jag försiktigt skruvar av locket på hundgodisburken vaknar han direkt
Det är nog som du säger, det handlar helt klart om inlärning och om person till person.
Om en person som är livrädd för möss bor i ett hus där det ibland händer att det dyker upp en mus, så kommer nog den personen möjligen hoppa högt ifall hon/han hör ett litet mus-pip.
Njae, riktigt så fungerar det inte. Men huvudsaken är att ”transienter” som ordet användes av TS är en teknisk beskrivning av en signal. Begreppet som sådant har inte med varseblivning att göra, och att blanda in prominens är irrelevant.
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).
En specifik kommentar till trådfrågan - njae, vågorna förenas inte. De passerar varandra och färdas därefter solo igen. De får dock när de möts en summa i varje position i rummet, men i grunden så gäller superpositionsprincipen (vid rimliga ljudtryck).
Vh, iö
Fd psykoakustikforskare & ordf LTS. Nu akustiker m specialiteten
studiokontrollrum, hemmabiosar & musiklyssnrum. Även Ch. R&D
åt Carlsson och Guru, konsult åt andra + hobbyhögtalartillv (Ino).